Like many other marketing buzzwords, the concept of “serverless” has taken on a life of its own, which can make it difficult to understand what serverless actually means. What it really means is that the cloud provider fully manages server infrastructure all the way up to the application layer. For example, GCE isn’t serverless because, while Google manages the physical server infrastructure, we still have to deal with patching operating systems, managing load balancers, configuring firewall rules, and so on. Serverless means we merely worry about our application code and business logic and nothing else. This concept extends beyond pure compute though, including things like databases, message queues, stream processing, machine learning, and other types of systems.
There are several benefits to the serverless model. First, it allows us to focus on building products, not managing infrastructure. These operations-related tasks, while important, are not generally things that differentiate a business. It’s just work that has to be done to support the rest of the business. With cloud—and serverless in particular—many of these tasks are becoming commoditized, freeing us up to focus on things that matter to the business.
Another benefit related to the first is that serverless systems provide automatic scaling and fault-tolerance across multiple data centers or, in some cases, even globally. When we leverage GCP’s serverless products, we also leverage Google’s operational expertise and the experience of an army of SREs. That’s a lot of leverage. Few companies are able to match the kind of investment cloud providers like Google or Amazon are able to make in infrastructure and operations, nor should they. If it’s not your core business, leverage economies of scale.
Finally, serverless allows us to pay only for what we use. This is quite a bit different from what traditional IT companies are used to where it’s more common to spend several millions of dollars on a large solution with a contract. It’s also different from what many cloud-based companies are used to where you typically provision some baseline capacity and pay for bursts of additional capacity as needed. With serverless, VMs are eschewed and we pay only for the resources we use to serve the traffic we have. This means no more worrying about over-provisioning or under-provisioning.
GCP’s Compute Options
GCP has a comprehensive set of compute options ranging from minimally managed VMs all the way to highly managed serverless backends. Below is the full spectrum of GCP’s compute services at the time of this writing. I’ll provide a brief overview of each of these services just to get the lay of the land. We’ll start from the highest level of abstraction and work our way down, and then we’ll hone in on the serverless solutions.
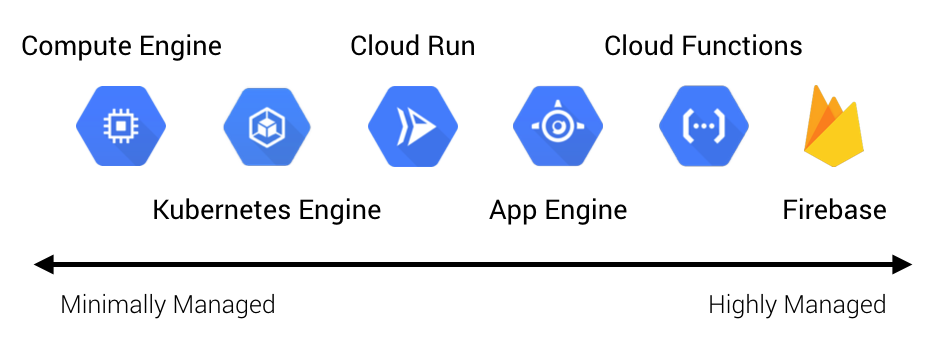
Firebase is Google’s managed Backend as a Service (BaaS) platform. This is the highest level of abstraction that GCP offers (short of SaaS like G Suite) and allows you to build mobile and web applications quickly and with minimal server-side code. For example, it can implement things like user authentication and offline data syncing for you. This is often referred to as a “backend as a service” because there is no server code. The trade-off is you have less control over the system, but it can be a great fit for quickly prototyping applications or building a proof of concept with minimal investment. The primary advantage is that you can focus most of your development effort on client-side application code and user experience. Note that some components of Firebase can be used outside of the Firebase platform, such as Cloud Firestore and Firebase Authentication.
Cloud Functions is a serverless Functions as a Service (FaaS) offering from GCP. You upload your function code and Cloud Functions handles the runtime of it. Because it’s a sandboxed environment, there are some restrictions to the runtime, but it’s a great choice for building event-driven services and connecting systems together. While you can develop basic user-facing APIs, the operational tooling is not sufficient for complex systems. The benefit is Cloud Functions are highly elastic and have minimal operational overhead since it is a serverless platform. They are an excellent choice for dynamic, event-driven plumbing such as moving data between services or reacting to log events. They work well for basic APIs, but can rapidly become operationally complex for more than a few endpoints.
App Engine is Google’s Platform as a Service (PaaS). Like Cloud Functions, it’s an opinionated but fully managed runtime that lets you upload your application code while handling the operational aspects such as autoscaling and fault-tolerance. App Engine has two modes: Standard, which is the opinionated PaaS runtime, and Flexible, which allows providing a custom runtime using a container—this is colloquially referred to as a Container as a Service (CaaS). For stateless applications with quick instance start-up times, it is often an excellent choice. It offers many of the benefits of Cloud Functions but simplifies operational aspects since larger components are easy to deploy and manage. App Engine allows developers to focus most of their effort on business logic. Standard is a great fit for greenfield applications where server-side processing and logic is required. Flex can be easier for migrating existing workloads because it is less opinionated.
Cloud Run is a new offering in GCP that provides a managed compute platform for stateless containers. Essentially, Google manages the underlying compute infrastructure and all you have to do is provide them an application container. Like App Engine, they handle scaling instances up and down, load balancing, and fault-tolerance. Cloud Run actually has two modes: the Google-managed version, which runs your containers on Google’s internal compute infrastructure known as Borg, and the GKE version, which allows running workloads on your own GKE cluster. This is because Cloud Run is built on an open source Kubernetes platform for serverless workloads called Knative.
Cloud Run and App Engine Flex are similar to each other, but there are some nuanced differences. One key difference is Cloud Run has very fast instance start-up time due to its reliance on the gVisor container runtime. Flex instances, on the other hand, usually take minutes to start because they involve provisioning GCE instances, load balancers, and other GCP-managed infrastructure. Flex is also more feature-rich than Cloud Run, supporting things like traffic splitting, deployment rollbacks, WebSocket connections, and VPC connections.
Kubernetes Engine, or GKE, is Google’s managed Kubernetes service. GKE effectively adds a container orchestration layer on top of GCE, putting it somewhere between IaaS (Infrastructure as a Service) and CaaS. This is typically the lowest level of abstraction most modern applications should require. There is still a lot of operational overhead involved with using a managed Kubernetes service.
Lastly, Compute Engine, or GCE, is Google’s VM offering. GCE VMs are usually run on multi-tenant hosts, but GCP also offers sole-tenant nodes where a physical Compute Engine server is dedicated to hosting a single customer’s VMs. This is the lowest level of infrastructure that GCP offers and the lowest common denominator generally available in the public clouds, usually referred to as IaaS. This means there are a lot of operational responsibilities that come with using it. There are generally few use cases that demand a bare VM.
Choosing a Serverless Option
Now that we have an overview of GCP’s compute services, we can focus in on the serverless options.
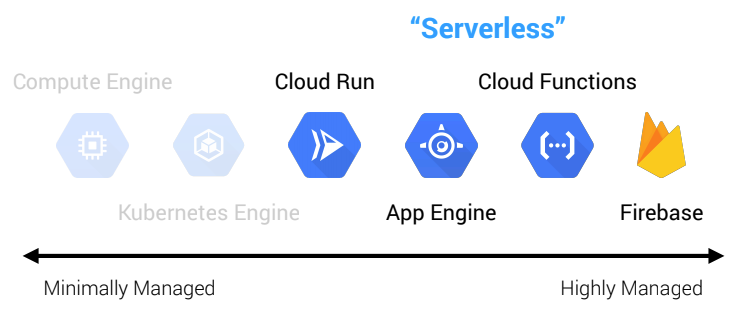
GCP currently has four serverless compute options (emphasis on computebecause there are other serverless offerings for things like databases, queues, and so forth, but these are out of scope for this discussion).
- Cloud Run: serverless containers (CaaS)
- App Engine: serverless platforms (PaaS)
- Cloud Functions: serverless functions (FaaS)
- Firebase: serverless applications (BaaS)
With four different serverless options to choose from, how do we decide which one is right? The first thing to point out is that we don’t necessarily need to choose a single solution. We might end up using a combination of these services when building a system. However, I’ve provided some criteria below on selecting solutions for different types of problems.
Firebase
If you’re looking to quickly prototype an application or focus only on writing code, Firebase can be a good fit. This is especially true if you’re wanting to focus most of your investment and time on the client-side application code and user experience. Likewise, if you want to build a mobile-ready application and don’t want to implement things like user authentication, it’s a good option.
Firebase is obviously the most restrictive and opinionated solution, but it’s great for rapid prototyping and accelerating development of an MVP. You can also complement it with services like App Engine or Cloud Functions for situations that require server-side compute.
Good Fit Characteristics
- Mobile-first (or ready) applications
- Rapidly prototyping applications
- Applications where most of the logic is (or can be) client-side
- Using Firebase components on other platforms, such as using Cloud Firestore or Firebase Authentication on App Engine, to minimize investment in non-differentiating work
Bad Fit Characteristics
- Applications requiring complex server-side logic or architectures
- Applications which require control over the runtime
Cloud Functions
If you’re looking to react to real-time events, glue systems together, or build a simple API, Cloud Functions are a good choice provided you’re able to use one of the supported runtimes (Node.js, Python, and Go). If the runtime is a limitation, check out Cloud Run.
Good Fit Characteristics
- Event-driven applications and systems
- “Glueing” systems together
- Deploying simple APIs
Bad Fit Characteristics
- Highly stateful systems
- Deploying large, complex APIs
- Systems that require a high level of control or need custom runtimes or binaries
App Engine
If you’re looking to deploy a full application or complex API, App Engine is worth looking at. Standard is good for greenfield applications which are able to fit within the constraints of the runtime. It can scale to zero and deploys take seconds. Flexible is easier for existing applications where you’re unwilling or unable to make changes fitting them into Standard. Deploys to Flex can take minutes, and you must have a minimum of one instance running at all times.
Good Fit Characteristics
- Stateless applications
- Rapidly developing CRUD-heavy applications
- Applications composed of a few services
- Deploying complex APIs
Bad Fit Characteristics
- Stateful applications that require lots of in-memory state to meet performance or functional requirements
- Applications built with large or opinionated frameworks or applications that have slow start-up times (this can be okay with Flex)
- Systems that require protocols other than HTTP
Cloud Run
If you’re looking to react to real-time events but need custom runtimes or binaries not supported by Cloud Functions, Cloud Run is a good choice. It’s also a good option for building stateless HTTP-based web services. It’s trimmed down compared to App Engine Flex, which means it has fewer features, but it also has faster instance start-up times, can scale to zero, and is billed only by actual request-processing time rather than instance time.
Good Fit Characteristics
- Stateless services that are easily containerized
- Event-driven applications and systems
- Applications that require custom system and language dependencies
Bad Fit Characteristics
- Highly stateful systems or systems that require protocols other than HTTP
- Compliance requirements that demand strict controls over the low-level environment and infrastructure (might be okay with the Knative GKE mode)
Finally, Google also provides a decision tree for choosing a serverless compute platform.
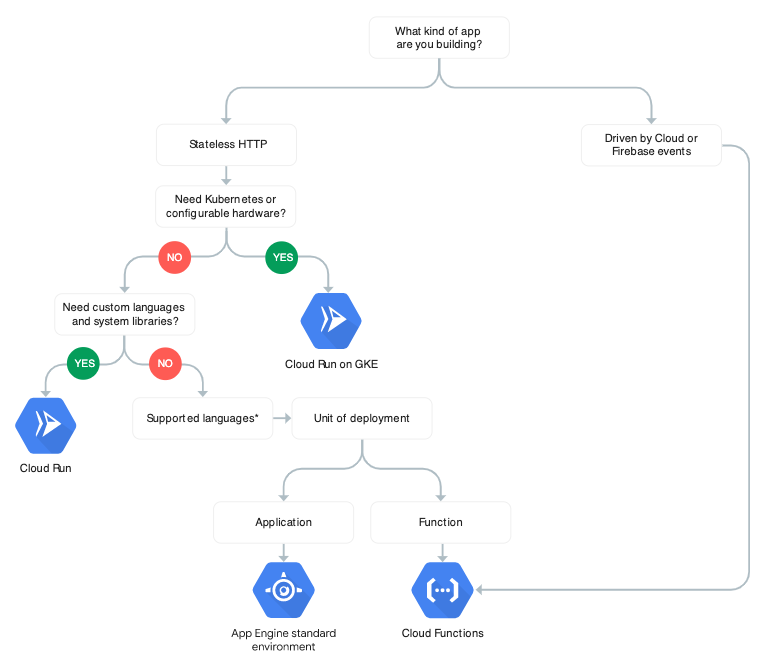
* Cloud Function supports Node.js, Python, Go
Summary
Going serverless can provide a lot of efficiencies by freeing up resources and investment to focus on things that are more strategic and differentiating for a business rather than commodity infrastructure. There are trade-offs when using managed services and serverless solutions. We lose some control and visibility. At certain usage levels there can be a premium, so eventually renting VMs might be the more cost-effective solution once you crack that barrier. However, it’s important to consider not just operational costs involved in managing infrastructure, but also opportunity costs. These trade-offs have to be weighed carefully against the benefits they bring to the business.
One thing worth pointing out is that it’s often easier to move down a level of abstraction than up. That is, there’s typically less friction involved in moving from a more opinionated platform to a less opinionated one than vice versa. This is why we usually suggest starting with the highest level of abstraction possible and dropping down if and when needed.
Follow @tyler_treat