Transitioning from an on-prem environment to a cloud environment involves a lot of major shifts for organizations. One of those shifts is often around how we monitor the overall health of systems. The typical way to measure things like the availability, reliability, and performance of systems is with SLIs or Service Level Indicators. SLIs are a valuable tool both on-prem and in the cloud, but when it comes to the latter, I often see organizations carrying over some operational anti-patterns from their data center environment.
Unlike public clouds, data centers are often resource-constrained. Services run on dedicated sets of VMs and it can take days or weeks for new physical servers to be provisioned. Consequently, it’s common for organizations to closely monitor metrics such as CPU utilization, memory consumption, disk space, and so forth since these are all precious resources within a data center.
Often what happens is that ops teams get really good at identifying and pattern-matching the common issues that arise in their on-prem environment. For instance, certain applications may be prone to latency issues. Each time we dig into a latency issue we find that the problem is due to excessive garbage collection pauses. As a result, we define a metric around garbage collection because it is often an indicator of performance problems in the application. In practice, this becomes an SLI, whether it’s explicitly defined as such or not, because there is some sort of threshold beyond which garbage collection is considered “excessive.” We begin watching this metric closely to gauge whether the service is healthy or not and alerting on it.
The cloud is a very different environment than on-prem. Whether we’re using an orchestrator such as Kubernetes or a serverless platform, containers are usually ephemeral and instances autoscale up and down. If an instance runs out of memory, it will just get recycled. This is why we sometimes say you can “pay your way out” of a problem in these environments because autoscaling and autohealing can hide a lot of application issues such as a slow memory leak. In an on-prem environment, these can be significantly more impactful. The performance profile of applications often looks quite differently in the cloud than on-prem as well. Underlying hardware, tenancy, and networking characteristics differ considerably. All this is to say, things look and behave quite differently between the two environments, so it’s important to reevaluate operational practices as well. With SLIs and monitoring, it’s easy to bias toward specific indicators from on-prem, but they might not translate to more cloud-native environments.
User-centric monitoring
So how do we choose good SLIs? The key question to ask is: what is the customer’s experience like? Everything should be driven from this. Is the application responding slowly? Is it returning errors to the user? Is it returning bad or incorrect results? These are all things that directly impact the customer’s experience. Conversely, things that do not directly impact the customer’s experience are questions such as what is the CPU utilization of the service? The memory consumption? The rate of garbage collection cycles? These are all things that could impact the customer’s experience, but without actually looking from the user’s perspective, we simply don’t know whether they are or not. Rather, they are diagnostic tools that—once an issue is identified—can help us to better understand the underlying cause.
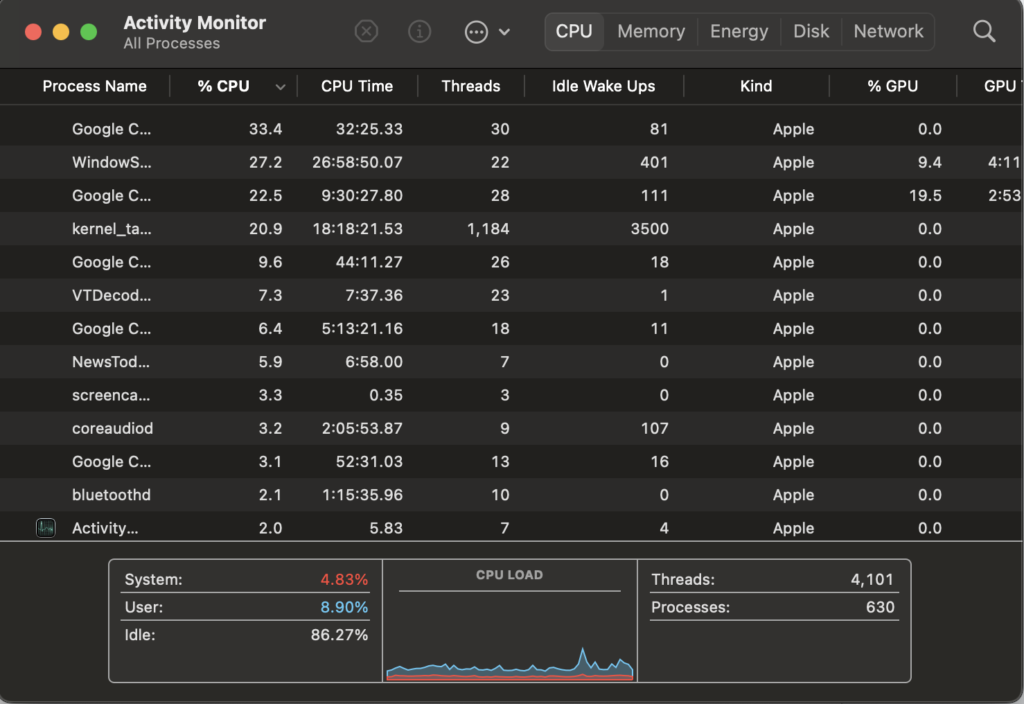
Take, for example, the CPU and memory utilization of processes on your computer. Most people probably are not constantly watching the Activity Monitor on their MacBook. Instead, they might open it up when they notice their machine is responding slowly to see what might be causing the slowness.
Three key metrics
When it comes to monitoring services, there are really three key metrics that matter: traffic rate, error rate, and latency. These three things all directly impact the user’s experience.
Traffic Rate
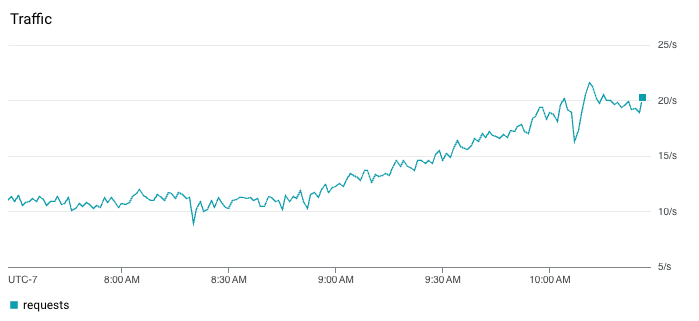
Traffic rate, which is usually measured in requests or queries per second (qps), is important because it tells us if something is wrong upstream of us. For instance, our service might not be throwing any errors, but if it’s suddenly handling 0 qps when it ordinarily is handling 80-100 qps, then something happened upstream that we should know about. Perhaps there is a misconfiguration that is preventing traffic from reaching our service, which almost certainly impacts the user experience.
Error Rate
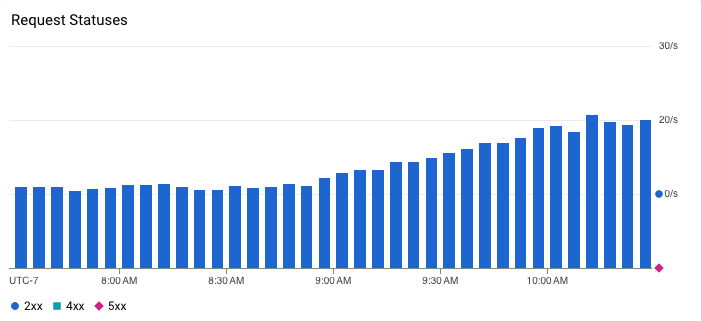
Error rate simply tells us the rate in which the service is returning errors to the client. If our service normally returns 200 responses but suddenly starts returning 500 errors, we know something is wrong. This requires good status code hygiene to be effective. I’ve encountered codebases where various types of error codes are used to indicate non-error conditions which can add a lot of noise to this type of SLI. Additionally, this metric might be more fine-grained than just “error” or “not error”, since—depending on the application—we might care about the rate of specific 2xx, 4xx, or 5xx responses, for example.
It’s common for teams to rely on certain error logs rather than response status codes for monitoring. This can provide even more granularity around types of error conditions, but in my experience, it usually works better to rely on fairly coarse-grained signals such as HTTP status codes for the purposes of aggregate monitoring and SLIs. Instead, use this logging for diagnostics and troubleshooting once you have identified there is a problem (I am, however, a fan of structured logging and log-based metrics for instrumentation but this is for another blog post).
Latency
Combined with error rate, latency tells us what the customer’s experience is really like. This is an important metric for synchronous, user-facing APIs but might be less critical for asynchronous processes such as services that consume events from a message queue. It’s important to point out that when looking at latency, you cannot use averages. This is a common trap I see ops teams and engineers fall into. Latency rarely follows a normal distribution, so relying on averages or medians to provide a summarized view of how a system is performing is folly.
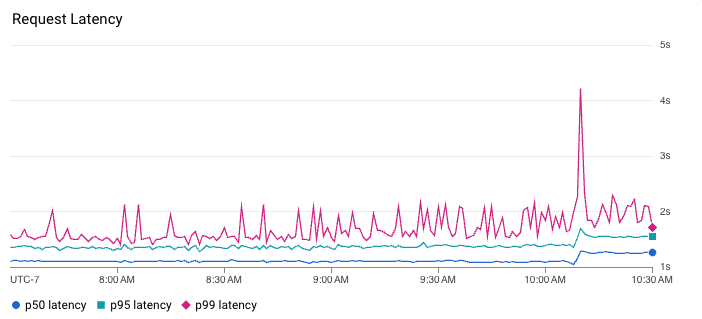
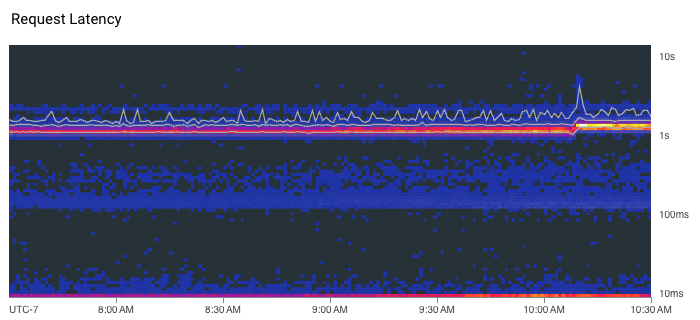
Instead, we have to look at percentiles to get a better understanding of what the latency distribution looks like. Similarly, you cannot average percentiles either. It mathematically makes no sense, meaning you can’t, for instance, look at the average 90th percentile over some period of time. To summarize latency, we can plot multiple percentiles on a graph. Alternatively, heatmaps can be an effective way to visualize latency because they can reveal useful details like distribution modes and outliers. For example, the heatmap below shows that the latency for this service is actually bimodal. Requests usually either respond in approximately 10 milliseconds or 1 second. This modality is not apparent in the line chart above the heatmap where we are only plotting the 50th, 95th, and 99th percentiles. The line chart does, however, show that latency ticked up a tiny bit around 10:10 AM following a severe spike in tail latency where the 99th percentile momentarily jumped over 4 seconds…curious.
Identifying other SLIs
While these three metrics are what I consider the critical baseline metrics, there may be other SLIs that are important to a service. For example, if our service is a cache, we might care about the freshness of data we’re serving as something that impacts the customer experience. If our service is queue-based, we might care about the time messages spend sitting in the queue.
Whatever the SLIs are, they should be things that directly matter to the user’s experience. If they aren’t, then at best they are a useful diagnostic or debugging tool and at worst they are just dashboard window dressing. Usually, though, they’re no use for proactive monitoring because it’s too much noise, and they’re no use for reactive debugging because it’s typically pre-aggregated data.
What’s worse is that when we focus on the wrong SLIs, it can lead us to take steps that actively harm the customer’s experience or simply waste our own time. A real-world example of this is when I saw a team that was actively monitoring garbage collection time for a service. They noticed one instance in particular appeared to be running more garbage collections than the others. While it appeared there were no obvious indicators of latency issues, timeouts, or out-of-memory errors that would actually impact the client, the team decided to redeploy the service in order to force instances to be recycled. This redeploy ended up having a much greater impact on the user experience than any of the garbage collection behavior ever did. The team also spent a considerable amount of time tuning various JVM parameters and other runtime settings, which ultimately had minimal impact.
Where lower-level metrics can provide value is with optimizing resource utilization and cloud spend. While the elastic nature of cloud may allow us to pay our way out of certain types of problems such as a memory leak, this can lead to inefficiency and waste long term. If we see that our service only utilizes 20% of its allocated CPU, we are likely overprovisioned and could save money. If we notice memory consumption consistently creeping up and up before hitting an out-of-memory error, we likely have a memory leak. However, it’s important to understand this distinction in use cases: SLIs are about gauging customer experience while these system metrics are for identifying optimizations and understanding long-term resource characteristics of your system. At any rate, I think it’s preferable to get a system to production with good monitoring in place, put real traffic on it, and then start to fine-tune its performance and resource utilization versus trying to optimize it beforehand through synthetic means.
Transitioning from an on-prem environment to the cloud necessitates a shift in how we monitor the health of systems. It’s essential to recognize and discard operational anti-patterns from traditional data center environments, where resource constraints often lead to a focus on specific metrics and behaviors. This can frequently lead to a sort of “overfitting” when monitoring cloud-based systems. The key to choosing good SLIs is by aligning them with the customer’s experience. Metrics such as traffic rate, error rate, and latency directly impact the user and provide meaningful insights into the health of services. By emphasizing these critical baseline metrics and avoiding distractions with irrelevant indicators, organizations can proactively monitor and improve the customer experience. Focusing on the right SLIs ensures that efforts are directed toward resolving actual issues that matter to users, avoiding pitfalls that can inadvertently harm user experience or waste valuable time. As organizations navigate the complexities of migrating to a cloud-native environment, a user-centric approach to monitoring remains fundamental to successful and efficient operations.
Need help making the transition?
Real Kinetic helps organizations with their cloud migrations and implementing effective operations. If you have questions or need help getting started, we’d love to hear from you. These emails come directly to us, and we respond to every one.
Follow @tyler_treat