ETL (Extract-Transform-Load) processes are an essential component of any data analytics program. This typically involves loading data from disparate sources, transforming or enriching it, and storing the curated data in a data warehouse for consumption by different users or systems. An example of this would be taking customer data from operational databases, joining it with data from Salesforce and Google Analytics, and writing it to an OLAP database or BI engine.
In this post, we’ll take an honest look at building an ETL pipeline on GCP using Google-managed services. This will primarily be geared towards people who may be familiar with SQL but may feel less comfortable writing code or building a solution that requires a significant amount of engineering effort. This might include data analysts, data scientists, or perhaps more technical-oriented business roles. That is to say, we’re mainly looking at low-code/no-code solutions, but we’ll also touch briefly on more code-heavy options towards the end. Specifically, we’ll compare and contrast Data Fusion and Cloud Dataprep. As part of this, we will walk through the high-level architecture of an ETL pipeline and discuss common patterns like data lakes and data warehouses.
General Architecture
It makes sense to approach ETL in two phases. First, we need a place to land raw, unprocessed data. This is commonly referred to as a data lake. The data lake’s job is to serve as a landing zone for all of our business data, even if the purpose of some of that data is not yet clear. The data lake is also where we can de-identify or redact sensitive data before it moves further downstream.
The second phase is processing the raw data and storing it for particular use cases. This is referred to as a data warehouse. The data here feeds end-user queries and reports for business analysts, BI tools, dashboards, spreadsheets, ML models, and other business activities. The data warehouse structures the data in a way suitable for these specific needs.
On GCP, our data lake is implemented using Cloud Storage, a low-cost, exabyte-scale object store. This is an ideal place to land massive amounts of raw data. We can also use Cloud Data Loss Prevention (DLP) to alert on or redact any sensitive data such as PII or PHI. Once use cases have been identified for the data, we then transform it and move it into our curated data warehouse implemented with BigQuery.
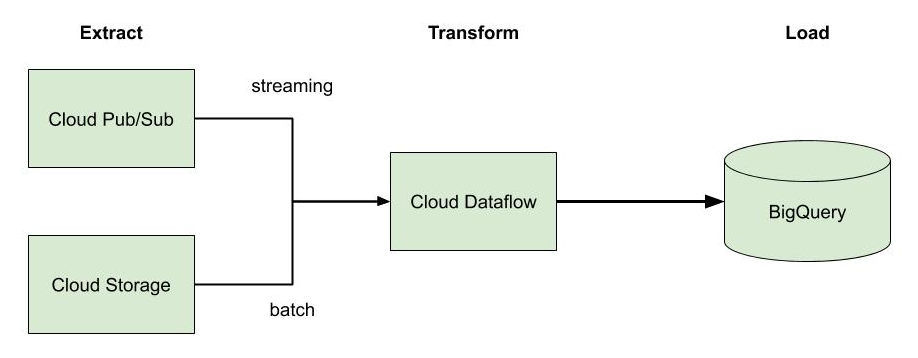
At a high level, our analytics pipeline architecture looks something like the following. The components in green are pieces implemented on GCP.
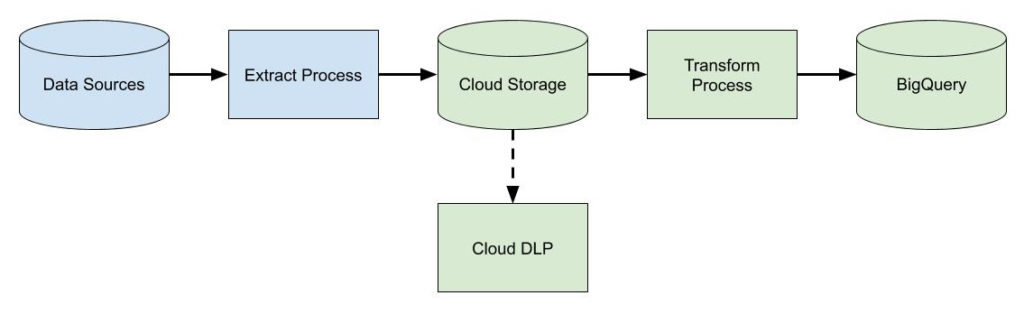
We won’t cover how data gets ingested into the data warehouse. This might be a data-integration tool like Mulesoft or Informatica if we’re moving data from on-prem. It might be an automated batch process using gsutil, a Python script, or Transfer Service. Alternatively, it might be a more real-time push process that streams data in via Cloud Pub/Sub. Either way, we’ll assume we have some kind of mechanism to load our data into Cloud Storage.
We will focus our time discussing the “Transform Process” step in the diagram above. This is where Data Fusion and Cloud Dataprep fit in.
Data Fusion
Data Fusion is a code-free data integration tool that runs on top of Hadoop. The user is intended to define ETL pipelines using a graphical plug-and-play UI with preconfigured connectors and transformations. Data Fusion is actually a managed version of an open source system called Cask Data Analytics Platform (CDAP) which Google acquired in 2018. It’s a relatively new product in GCP, and it shows. The UX is rough and there are a lot of sharp edges. For example, when an instance starts up, you can occasionally hit cryptic errors because the instance has not actually initialized fully. Case in point, try deciphering what this error means:

The theory of letting users with no programming experience implement and run ETL pipelines is appealing. However, the reality is that you will end up trying to understand Hadoop debug logs and opaque error messages when things go wrong, which happens frequently.
The pipelines created in Data Fusion run on Cloud Dataproc. This means every time you run a pipeline, you first need to wait for a Dataproc cluster to spin up—which is slow. Google’s recommendation to speed this up is to configure a runtime profile that uses a pre-existing Dataproc cluster. This has several downsides, one of which is simply the cost of keeping a Dataproc cluster running in addition to your Data Fusion instance. But what is the point of keeping a cluster running that only gets used for nightly batch processes or ad hoc pipeline development? The other is the technical and operations overhead required to configure and manage a cluster. This requires provisioning an appropriately sized cluster, creating an SSH key for it, and adding the key to the cluster so that Data Fusion can connect to it. For a product designed to allow relatively non-technical people to build out pipelines, this is a tall order. You’ll also quickly see how rough the UX is when walking through these steps.
The other downside of Data Fusion is that it’s actually pretty expensive. CDAP consists of a whole bunch of components. When you start a Data Fusion instance, it creates an internal GKE cluster to run all of these components. In addition to this, it relies on Cloud Storage, Cloud SQL, Persistent Disks, Elasticsearch, and Cloud KMS. The net result is that instances take approximately 10-20 minutes to start (now closer to 10 with recent improvements) and, for many, they’re not something you run and forget about.
A Basic Edition instance costs about $1,100 per month, while an Enterprise Edition instance costs $3,000 per month. For larger organizations, that might be a nominal cost, but it stings a bit when you realize that is just the cost to run the pipeline editor. The pipelines themselves run on Dataproc, which is an entirely separate—and significant—line item. What’s worse is that you have to keep the Data Fusion instance running in order to actually execute the ETL pipelines you develop in it. Additionally, the Basic Edition will only let you run pipelines on demand. In order to schedule pipelines or trigger them in a more streaming fashion, you have to use the Enterprise Edition. As a result, I often encounter teams wanting to schedule startup and shutdown for both the Dataproc clusters and Data Fusion instances to avoid unnecessary spend. This has to be done with code.
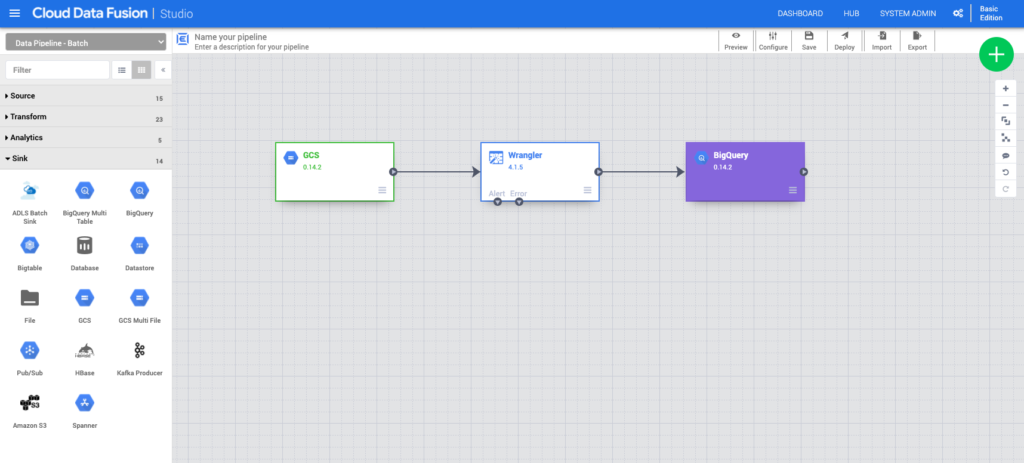
Pipelines are immutable, which means every time you need to tweak a pipeline, you first have to make a copy of it. Immutability sounds nice in theory, but in practice it means you end up with dozens of pipeline iterations as you build out your process. And in order to save your pipeline when a Data Fusion instance is deleted—say because you’re shutting it down nightly to save on costs—you have to export it to a file and then import it to the new instance. Recycling instances will still lose the job information for previous pipeline runs, however. There is no way to “pause” an instance, which makes pipeline management a pain.
Data Fusion itself is fairly robust in what you can do with it. It can extract data from a broad set of sources, including Cloud Storage, perform a variety of transformations, and load results into an assortment of destinations such as BigQuery. That said, I’m still a bit skeptical about no-code solutions for non-technical users. I still often find myself dropping in a JavaScript transform in order to actually do the manipulations on the data that I need versus trying to do it with a combination of preconfigured drag-and-drop widgets. Most of the analysts I’ve seen using it also just want to use SQL to do their transformations. Trying to join two data sources using a UI is frankly just more difficult than writing a SQL join. The data wrangler uses a goofy scripting language called JEXL that is poorly documented and inconsistently implemented. To put it bluntly, the UI and UX in Data Fusion (technically CDAP) is painful, and I often find myself wishing I could just write some Python. It just feels like an open source product that doesn’t see much investment.
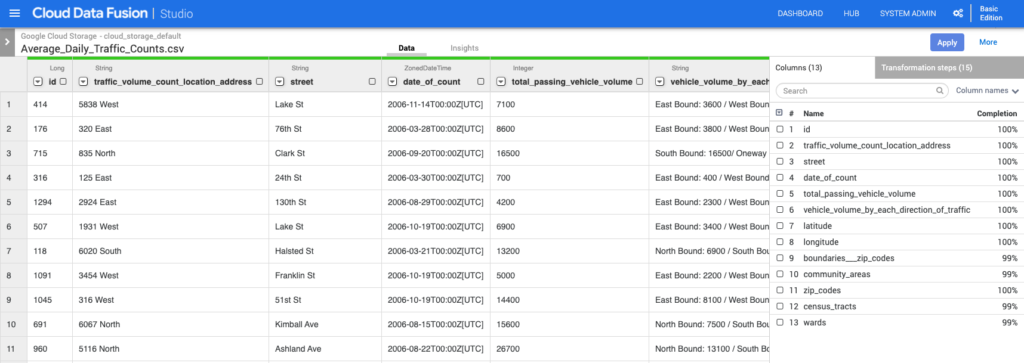
Data Fusion is a bit of an oddball when viewed in the context of how GCP normally approaches services until you realize it was an acquisition of a company built around an open source framework. In that light, it feels very similar to Cloud Composer, another product built around an open source framework, Apache Airflow, which feels equally kludgy. Most of Google’s data products are highly refined with an emphasis on serverless and developer experience. Services like BigQuery, Dataflow, and Cloud Pub/Sub come to mind here. Data Fusion is the polar opposite. It’s clunky, the CDAP infrastructure is heavy and expensive, and it still requires low-level operations like when you’re configuring a Dataproc cluster.
Dataproc itself feels like a service for handling legacy Hadoop workloads since it has a lot of operations overhead. For newer workloads, I would target Dataflow which is closer to a “serverless” experience like BigQuery and is evidently on the roadmap as a runtime target for Data Fusion.
The CDAP UX is quirky, confusing, inconsistent, and generally unpleasant. The moment anything goes awry, which is often and unwittingly the case, you’re thrust into the world of Hadoop to divine what went wrong. I’m a raving fan of much of GCP’s managed services. On the whole, I find them to be better engineered, better thought-out, and better from a developer experience perspective compared to other cloud platforms. Data Fusion ain’t it.
Cloud Dataprep
Cloud Dataprep is actually a third-party application offered by Trifacta through GCP. In fact, it’s really just a GCP-specific SKU of Trifacta’s Wrangler product. The downside of this is that you have to agree to a third-party vendor’s terms and conditions. For some, this will likely trigger a whole separate sourcing process. This is a challenge for a lot of enterprise organizations.
If you can get past the procurement conundrum, you’ll find Dataprep to be a highly polished and refined product. In comparison to Data Fusion, it’s a breath of fresh air and is superior in nearly every aspect. The UI is pleasant, the UX is—for the most part—coherent and intuitive, it’s cheaper, and it’s a proper serverless product. Dataprep feels like what I would expect from a first-class managed service on GCP.
Dataprep is similar to Data Fusion in the sense that it allows you to build out pipelines with a graphical interface which then target an underlying runtime. In the case of Dataprep, it targets Dataflow rather than Dataproc. This means we benefit from the features of Dataflow, namely auto-provisioning and scaling of infrastructure. Jobs tend to run much more quickly and reliably than with Data Fusion. Another key difference is that, unlike Data Fusion, Dataprep doesn’t require an “instance” to develop pipelines. It is more like a SaaS application that relies on Dataflow. Today, using the app to develop pipelines is free of charge. You only incur charges from Dataflow resource usage. Unfortunately, this is changing as Trifacta is switching to a tiered monthly subscription model later this year. This will put base costs more in-line with Data Fusion, but I suspect the reliance on Dataflow will bring overall costs down.
The pipeline management in Dataprep is simpler than in Data Fusion. Pipelines in Dataprep are called “flows.” These are mutable and private by default but can be shared with other users. Because Dataprep is a SaaS product, you don’t need to worry about exporting and persisting your pipelines, and job data from previous flow executions is retained.
Dataprep has some drawbacks though. Broadly speaking, it’s not as feature-rich as Data Fusion. It can only integrate with Cloud Storage and BigQuery, while Data Fusion supports a wide array of data sources and sinks. You can do more with Data Fusion, while with Dataprep, you’re more or less confined to the wrangler. Because of this, Dataprep is well-suited to lighter weight processes and data cleansing—joining data sources, standardizing formats, identifying missing or mismatched values, deduplicating rows, and other things like that. It also works well for data exploration and slicing and dicing.
I often find teams using both Data Fusion and Dataprep. Data Fusion gets used for more advanced ETL processes and Dataprep for, well, data preparation. If it’s available to them, teams usually start with Dataprep and then switch to Data Fusion if they hit a wall with what it can do.
Alternatives
Data Fusion and Dataprep attempt to provide a managed solution that lets users with little-to-no programming experience build out ETL pipelines. Dataprep definitely comes closer to realizing that goal due to its more refined UX and reliance on Dataflow rather than Dataproc. However, I tend to dislike managed “workflow engines” like these. Cloud Composer and AWS Glue, which is Amazon’s managed ETL service, are other examples that fall under this category.
These types of services usually sit in a weird in-between position of trying to provide low-code solutions with GUIs but needing to understand how to debug complex and sophisticated distributed computing systems. It seems like every time you try something to make building systems easier, you wind up needing to understand the “easier” thing plus the “hard” stuff it was trying to make easy. This is what Joel Spolsky refers to as the Law of Leaky Abstractions. It’s why I prefer to write code to solve problems versus relying on low-code interfaces. The abstractions can work okay in some cases, but it’s when things go wrong or you need a little bit more flexibility where you run into problems. It can be a touchy subject, but I’ve found that the most effective data programs within organizations are the ones that have software engineers or significant programming and systems development skill sets. This is especially true if you’re on AWS where there’s more operations and networking knowledge required.
With that said, there are some alternative approaches to implementing ETL processes on GCP that move away from the more low/no-code options. If your team consists mostly of software engineers or folks with a development background, these might be a better option.
My go-to for building data processing pipelines is Cloud Dataflow, which is a serverless system for implementing stream and batch pipelines. With Dataflow, you don’t need to think about capacity and resource provisioning and, unlike Data Fusion and Dataproc, you don’t need to keep a standby cluster running as there is no “cluster.” The compute is automatically provisioned and autoscaled for you based on the job. You can use code to do your transformations or use SQL to join different data sources.
For batch ETL, I like a combination of Cloud Scheduler, Cloud Functions, and Dataflow. Cloud Scheduler can kick off the ETL process by hitting a Cloud Function which can then trigger your Dataflow template. Alternatively, you could use a streaming Dataflow pipeline in combination with Cloud Scheduler and Pub/Sub to launch your batch ETL pipelines. Google has an example of this here.
For streaming ETL, data can be fed into a streaming Dataflow pipeline from Cloud Pub/Sub and processed as usual. This data can even be joined with files in Cloud Storage or tables in BigQuery using SQL. This is what I found myself and many of the clients I’ve worked with wanting to do in Data Fusion and Dataprep. Sometimes you just want to write SQL, which leads to another solution.
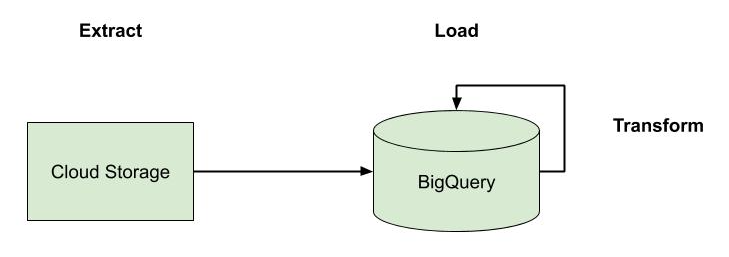
BigQuery provides a good mechanism for ELT—that is extracting the data from its sources, loading it into BigQuery, and then performing the transformations on it. This is a good option if you’re dealing with primarily batch-driven processes and you have a SQL-heavy team as the transformations are expressed purely through SQL. The transformation queries can either be scheduled directly in BigQuery or triggered in an automated way using the API, such as running the transformations after data loading completes.
I mentioned earlier that I’m not a huge fan of managed workflow engines. This is speaking to high-level abstractions and heavy, monolithic frameworks specifically. However, I am a fan of lightweight, composable abstractions that make it easy to build scalable and fault-tolerant workflows. Examples of this include AWS Step Functions and Google Cloud Tasks. On GCP, Cloud Tasks can be a great alternative to Dataflow for building more code-heavy ETL processes if you’re not tied in to Apache Beam. In combination with Cloud Run, you can build out highly elastic workflows that are entirely serverless. While it’s not the obvious choice for implementing ETL on GCP, it’s definitely worth a mention.
Conclusion
There are several options when it comes to implementing ETL processes on GCP. What the right fit is depends on your team’s skill set, the use cases, and your affinity for certain tools. Cost and operational complexity are also important considerations. In practice, however, it’s likely you’ll end up using a combination of different solutions.
For low/no-code solutions, Data Fusion and Cloud Dataprep are your only real options. While Data Fusion is rough from a usability perspective and generally more expensive, it’s likely where Google is putting significant investment. Dataprep is more refined and cost-effective but limited in capability, and it brings a third-party vendor into the mix. Using BigQuery itself for ELT is also an option for SQL-minded teams. But for teams with a strong engineering background, my recommended starting point is Cloud Dataflow or even Cloud Tasks for certain types of processing work.
Together with Cloud Pub/Sub, Cloud Data Loss Prevention, Cloud Storage, BigQuery, and GCP’s other managed services, these solutions provide a great way to implement analytics pipelines that require minimal operations investment.
Follow @tyler_treat
Great information on ETL pipeline on GCP. I have been using Sarasanalytics Daton for my clients it has been very helpful, easy and cost effective too. Sarasanalytics Daton
Great, insightful, comprehensive information on the various ETL, ELT options we have on Google Cloud Platform.