A classical problem presented within the field of distributed systems is the Byzantine Generals Problem. In it, we observe two allied armies positioned on either side of a valley. Within the valley is a fortified city. Each army has a general with one acting as commander. Both armies must attack at the same time or face defeat by the city’s defenders. In order to come to an agreement on when to attack, messengers must be sent through the valley, risking capture by the city’s patrols. Consider the diagram below illustrating this problem.
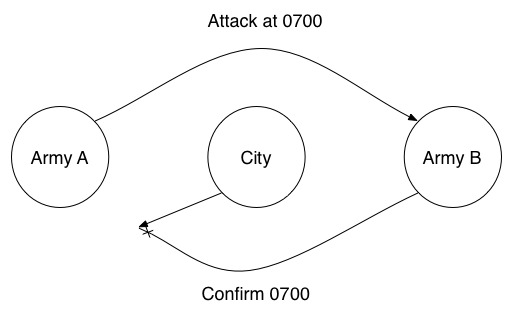
In the above scenario, Army A has sent a messenger to Army B with a message saying “Attack at 0700.” Army B receives this message and dispatches a messenger carrying an acknowledgement of the attack plans; however, our ill-fated messenger has been intercepted by the city’s defenders.
How do our armies come to an agreement on when to attack? Perhaps Army A sends 100 messengers and attacks regardless. Unfortunately, if all of the messengers are captured, this would result in a swift defeat because A would attack without B. What if, instead, A sends 100 messengers, waits for acknowledgements of those messages, and only attacks if it reaches a certain level of confidence, say receiving 75 or more confirmations? Yet again, this could very well end in defeat, this time with B attacking without A.
We also need to bear in mind that sending messages has a certain amount of overhead. We can’t, in good conscience, send a million messengers to their potential demise. Or maybe we can, but it’s more than the number of soldiers in our army.
In fact, we can’t reliably make a decision. It’s provenly impossible. In the face of a Byzantine failure, it becomes even more complicated by the possibility of traitors or forged messages.
Now replace two generals with N generals. Coming to a perfectly reliable agreement between two generals was already impossible but becomes dramatically more complicated. It’s a problem more commonly referred to as distributed consensus, and it’s the focus of an army of researchers.
The problem of consensus is blissfully simple, but the solution is far from trivial. Consensus is the basis of distributed coordination services, locking protocols, and databases. A monolithic system (think a MySQL server) can enforce ACID constraints with consistent reads but exhibits generally poor availability and fault tolerance. The original Google App Engine datastore relied on a master/slave architecture where a single data center held the primary copy of data which was replicated to backup sites asynchronously. This offered applications strong consistency and low latency with the implied trade-off of availability. The health of an application was directly tied to the health of a data center. Beyond transient losses, it also meant periods of planned unavailability and read-only access while Google performed data center maintenance. App Engine has since transitioned to a high-replication datastore which relies on distributed consensus to replicate data across sites. This allows the datastore to continue operating in the presence of failures and at greater availability. In agreement with CAP, this naturally means higher latency on writes.
There are a number of solutions to distributed consensus, but most of them tend to be pretty characteristic of each other. We will look at some of these solutions, including multi-phase commit and state-replication approaches.
Two-Phase Commit
Two-phase commit (2PC) is the simplest multi-phase commit protocol. In two-phase commit, all transactions go through a coordinator who is responsible for ensuring a transaction occurs across one or more remote sites (cohorts).

When the coordinator receives a request, it asks each of its cohorts to vote yes or no. During this phase, each cohort performs the transaction up to the point of committing it. The coordinator then waits for all votes. If the vote is unanimously “yes,” it sends a message to its cohorts to commit the transaction. If one or more vote is “no,” a message is sent to rollback. The cohorts then acknowledge whether the transaction was committed or rolled back and the process is complete.
Two-phase commit is a blocking protocol. The coordinator blocks waiting for votes from its cohorts, and cohorts block waiting for a commit/rollback message from the coordinator. Unfortunately, this means 2PC can, in some circumstances, result in a deadlock, e.g. the coordinator dies while cohorts wait or a cohort dies while the coordinator waits. Another problematic scenario is when a coordinator and cohort simultaneously fail. Even if another coordinator takes its place, it won’t be able to determine whether to commit or rollback.
Three-Phase Commit
Three-phase commit (3PC) is designed to solve the problems identified in two-phase by implementing a non-blocking protocol with an added “prepare” phase. Like 2PC, it relies on a coordinator which relays messages to its cohorts.

Unlike 2PC, cohorts do not execute a transaction during the voting phase. Rather, they simply indicate if they are prepared to perform the transaction. If cohorts timeout during this phase or there is one or more “no” vote, the transaction is aborted. If the vote is unanimously “yes,” the coordinator moves on to the “prepare” phase, sending a message to its cohorts to acknowledge the transaction will be committed. Again, if an ack times out, the transaction is aborted. Once all cohorts have acknowledged the commit, we are guaranteed to be in a state where all cohorts have agreed to commit. At this point, if the commit message from the coordinator is not received in the third phase, the cohort will go ahead and commit anyway. This solves the deadlocking problems described earlier. However, 3PC is still susceptible to network partitions. If a partition occurs, the coordinator will timeout and progress will not be made.
State Replication
Protocols like Raft, Paxos, and Zab are popular and widely used solutions to the problem of distributed consensus. These implement state replication or primary-backup using leaders, quorums, and replicas of operation logs or incremental delta states.


These protocols work by electing a leader (coordinator). Like multi-phase commit, all changes must go through that leader, who then broadcasts the changes to the group. Changes occur by appending a log entry, and each node has its own log replica. Where multi-phase commit falls down in the face of network partitions, these protocols are able to continue working by relying on a quorum (majority). The leader commits the change once the quorum has acknowledged it.
The use of quorums provide partition tolerance by fencing minority partitions while the majority continues to operate. This is the pessimistic approach to solving split-brain, so it comes with an inherent availability trade-off. This problem is mitigated by the fact that each node hosts a replicated state machine which can be rebuilt or reconciled once the partition is healed.
Google relies on Paxos for its high-replication datastore in App Engine as well as its Chubby lock service. The distributed key-value store etcd uses Raft to manage highly available replicated logs. Zab, which differentiates itself from the former by implementing a primary-backup protocol, was designed for the ZooKeeper coordination service. In general, there are several different implementations of these protocols, such as the Go implementation of Raft.
Distributed consensus is a difficult thing to get right, but it’s important to frame it within the context of CAP. We can ensure stronger consistency at the cost of higher latency and lower availability. On the other hand, we can achieve higher availability with decreased latency while giving up strong consistency. The trade-offs really depend on what your needs are.
Comments
Comments are from this blog's WordPress era and are preserved read-only.
Sorry, but I did not get how do you start from “concensus is not possible (and even more impossible in of > 2 parties)” and you cure it with multiple replicas.
Same applies to you pingback. You claim that there is no such thing as exacly-once semantics but “you can emulate it using idempotency”. Your conclusions contradict to your thesis.
What the author means is that distributed consensus — consensus involving an asynchronous system of processes — is impossible, which has been mathematically proven (google “FLP theorem”, or read the paper here: https://groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf).
However, that does not mean that it is impossible in practice. It’s even stated at the end of the paper:
“We have shown that a natural and important problem of fault-tolerant cooperative computing cannot be solved in a totally asynchronous model of computation. These results do not show that such problems cannot be “solved” in practice; rather, they point up the need for more refined models of distributed computing that better reflect realistic assumptions about processor and communication timings, and for less stringent requirements on the solution to such problems. (For example, termination might be required only with probability 1.) Subsequent to the original announcement of these results [12], progress has been made along both of these lines [1-4, 9, 10, 20, 25].”
“The original Google App Engine datastore relied on a master/slave architecture where a single data center held the primary copy of data which was replicated to backup sites asynchronously. This offered applications strong consistency and low latency with the implied trade-off of availability. ”
I am kind of confused by this. If the replication to backup sites is asynchronous and those sites are used as read replicas, how does it provide strong consistency? I am considering strong consistency here means atomic consistency (linearizability). Even in google i/o talk on distributed transaction mentions master-slave as eventual consistent system.