Go is decidedly polarizing. While many are touting their transition to Go, it has become equally fashionable to criticize and mock the language. As Bjarne Stroustrup so eloquently put it, “There are only two kinds of programming languages: those people always bitch about and those nobody uses.” This adage couldn’t be more true. I apologize in advance for what appears to be just another in a long line of diatribes. I’m not really sorry, though.
I normally don’t advocate promoting or condemning a particular programming language or pontificate on why it is or isn’t used within an organization. They’re just tools for a job.
Today I’m going to be a hypocrite. The truth is we should care about what language and technologies we use to build and standardize on, but those decisions should be local to an organization. We shouldn’t choose a technology because it worked for someone else. Chances are they had a very different problem, different set of requirements, different engineering culture. There are so many factors that go into “success”—technology is probably the least impactful. Someone else’s success doesn’t translate to your success. It’s not the technology that makes or breaks us, it’s how the technology is appropriated, among many other conflating elements.
Now that I’ve prefaced why you shouldn’t choose a technology because it’s trendy, I’m going to talk about why we use Go where I work—yes, that’s meant to be ironic. However, I’m also going to describe why the language is essentially flawed. As I’ve alluded to, there are countless blog posts and articles which describe the shortcomings of Go. On the one hand, I’m apprehensive this doesn’t contribute anything meaningful to the dialogue. On the other hand, I feel the dialogue is important and, when framed in the right context, constructive.
Simplicity Through Indignity
Go is refreshingly simple. It’s what drew me to the language in the first place, and I suspect others feel the same way. There’s a popular quote from Rob Pike which I think is worth reiterating:
The key point here is our programmers are Googlers, they’re not researchers. They’re typically, fairly young, fresh out of school, probably learned Java, maybe learned C or C++, probably learned Python. They’re not capable of understanding a brilliant language but we want to use them to build good software. So, the language that we give them has to be easy for them to understand and easy to adopt.
Granted, it’s taken out of context, but on the surface this kind of does sound like Go is a disservice to intelligent programmers. However, there is value in pursuing a simple, yet powerful, lingua franca of backend systems. Any engineer, regardless of experience, can dive into virtually any codebase and quickly understand how something works. Unfortunately, the notion of programmers not understanding a “brilliant language” is a philosophy carried throughout Go, and it hinders productivity more than it helps.
We use Go because it’s boring. Previously, we worked almost exclusively with Python, and after a certain point, it becomes a nightmare. You can bend Python to your will. You can hack it, you can monkey patch it, and you can write remarkably expressive, terse code. It’s also remarkably difficult to maintain and slow. I think this is characteristic of statically and dynamically typed languages in general. Dynamic typing allows you to quickly build and iterate but lacks the static-analysis tooling needed for larger codebases and performance characteristics required for more real-time systems. In my mind, the curve tends to look something like this:
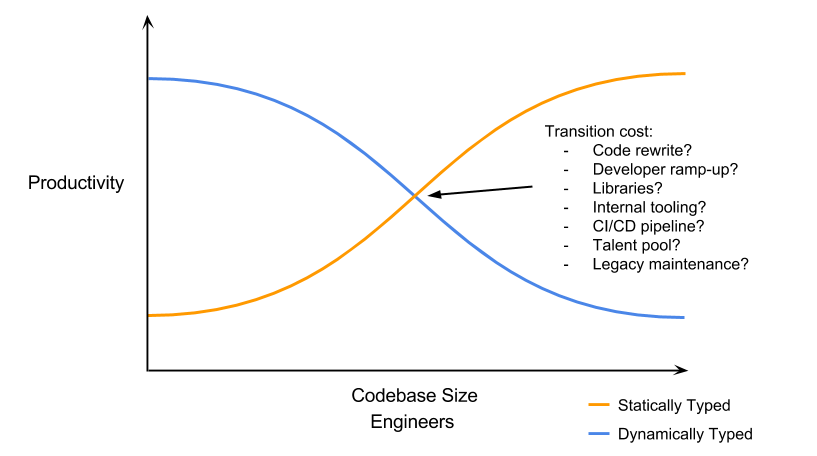
Of course, this isn’t particular to Go or Python. As highlighted above, there are a lot of questions you must ask when considering such a transition. Like I mentioned, languages are tools for a job. One might argue, then, why would a company settle on a single language? Use the right tool for the job! This is true in principle, but the reality is there are other factors to consider, the largest of which is momentum. When you commit to a language, you produce reusable libraries, APIs, tooling, and knowledge. If you “use the right tool for the job,” you end up pulling yourself in different directions and throwing away those things. If you’re Google scale, this is less of an issue. Most organizations aren’t Google scale. It’s a delicate balance when choosing a technology.
Go makes it easy to write code that is understandable. There’s no “magic” like many enterprise Java frameworks and none of the cute tricks you’ll find in most Python or Ruby codebases. The code is verbose but readable, unsophisticated but intelligible, tedious but predictable. But the pendulum swings too far. So far, in fact, that it sacrifices one of software development’s most sacred doctrines, Don’t Repeat Yourself, and it does so unapologetically.
The Untype System
To put it mildly, Go’s type system is impaired. It does not lend itself to writing quality, maintainable code at a large scale, which seems to be in stark contrast to the language’s ambitions. The type system is noble in theory, but in practice it falls apart rather quickly. Without generics, programmers are forced to either copy and paste code for each type, rely on code generation which is often clumsy and laborious, or subvert the type system altogether through reflection. Passing around interface{} harks back to the Java-pre-generics days of doing the same with Object. The code gets downright dopey if you want to write a reusable library.
The argument there, I suppose, is to rely on interfaces to specify the behavior needed in a function. In passing, this sounds reasonable, but again, it quickly falls apart for even the most trivial situations. Further, you can’t add methods to types from a different (or standard library) package. Instead, you must effectively alias or wrap the type with a new type, resulting in more boilerplate and code that generally takes longer to grok. You start to realize that Go isn’t actually all that great at what it sets out to accomplish in terms of fostering maintainable, large-scale codebases—boilerplate and code duplication abound. It’s 2015, why in the world are we still writing code like this:
Now repeat for uint32, uint64, int32, etc. In any other modern programming language, this would get you laughed out of a code review. In Go, no one seems to bat an eye, and the alternatives aren’t much better.
Interfaces in Go are interesting because they are implicitly implemented. There are advantages, such as implementing mocks and generally dealing with code you don’t own. They also can cause some subtle problems like accidental implementation. Just because a type matches the signature of an interface doesn’t mean it was intended to implement its contract. Not to mention the confusion caused by storing nil in an interface:
This is a common source of confusion. The basic answer is to never store something in an interface if you don’t expect the methods to be called on it. The language may allow it, but that violates the semantics of the interface. To expound, a nil value should usually not be stored in an interface unless it is of a type that has explicitly handled that case in its pointer-valued methods and has no value-receiver methods.
Go is designed to be simple, but that behavior isn’t simple to me. I know it’s tripped up many others. Another lurking danger to newcomers is the behavior around variable declarations and shadowing. It can cause some nasty bugs if you’re not careful.
Rules Are Meant to Be Broken, Just Not by You
Python relies on a notion of “we’re all consenting adults here.” This is great and all, but it starts to break down when you have to scale your organization. Go takes a very different approach which aligns itself with large development teams. Great! But it’s taken to the extreme, and the language seems to break many of its own rules, which can be both confusing and frustrating.
Go sort of supports generic functions as evidenced by its built-ins. You just can’t implement your own. Go sort of supports generic types as evidenced by slices, maps, and channels. You just can’t implement your own. Go sort of supports function overloading as evidenced again by its built-ins. You just can’t implement your own. Go sort of supports exceptions as evidenced by panic and recover. You just can’t implement your own. Go sort of supports iterators as evidenced by ranging on slices, maps, and channels. You just can’t implement your own.
There are other peculiar idiosyncrasies. Error handling is generally done by returning error values. This is fine, and I can certainly see the motivation coming from the abomination of C++ exceptions, but there are cases where Go doesn’t follow its own rule. For example, map lookups return two values: the value itself (or zero-value/nil if it doesn’t exist) and a boolean indicating if the key was in the map. Interestingly, we can choose to ignore the boolean value altogether—a syntax reserved for certain blessed types in the standard library. Type assertions and channel receives have equally curious behavior.
Another idiosyncrasy is adding an item to a channel which is closed. Instead of returning an error, or a boolean, or whatever, it panics. Perhaps because it’s considered a programmer error? I’m not sure. Either way, these behaviors seem inconsistent to me. I often find myself asking what the “idiomatic” approach would be when designing an API. Go could really use proper algebraic data types.
One of Go’s philosophies is “Share memory by communicating; don’t communicate by sharing memory.” This is another rule the standard library seems to break often. There are roughly 60 channels created in the standard library, excluding tests. If you look through the code, you’ll see that mutexes tend to be preferred and often perform better—more on this in a moment.
By the same token, Go actively discourages the use of the sync/atomic and unsafe packages. In fact, there have been indications sync/atomic would be removed if it weren’t for backward-compatibility requirements:
We want sync to be clearly documented and used when appropriate. We generally don’t want sync/atomic to be used at all…Experience has shown us again and again that very very few people are capable of writing correct code that uses atomic operations…If we had thought of internal packages when we added the sync/atomic package, perhaps we would have used that. Now we can’t remove the package because of the Go 1 guarantee.
Frankly, I’m not sure how you write performant data structures and algorithms without those packages. Performance is relative of course, but you need these primitives if you want to write anything which is lock-free. The irony is once you start writing highly concurrent things, which Go is generally considered good at, mutexes and channels tend to fall short performance-wise.
In actuality, to write high-performance Go, you end up throwing away many of the language’s niceties. Defers add overhead, interface indirection is expensive (granted, this is not unique to Go), and channels are, generally speaking, on the slowish side.
For being one of Go’s hallmarks, channels are a bit disappointing. As I already mentioned, the behavior of panicking on puts to a closed channel is problematic. What about cases where we have producers blocked on a put to a channel and another goroutine calls close on it? They panic. Other annoyances include not being able to peek into the channel or get more than one item from it, common operations on most blocking queues. I can live with that, but what’s harder to stomach are the performance implications, which I hinted at earlier. For this, I turn to my colleague and our resident performance nut, Dustin Hiatt:
Rarely do the Golang devs discuss channel performance, although rumblings were heard last time I was at Gophercon about not using defers or channels. You see, when Rob Pike makes the claim that you can use channels instead of locks, he’s not being entirely honest. Behind the scenes, channels are using locks to serialize access and provide threadsafety. So by using channels to synchronize access to memory, you are, in fact, using locks; locks wrapped in a threadsafe queue. So how do Go’s fancy locks compare to just using mutex’s from their standard library “sync” package? The following numbers were obtained by using Go’s builtin benchmarking functionality to serially call Put on a single set of their respective types.
BenchmarkSimpleSet-8 3000000 391 ns/op
BenchmarkSimpleChannelSet-8 1000000 1699 ns/op
This is with a buffered channel, what happens if we use unbuffered?
BenchmarkSimpleChannelSet-8 1000000 2252 ns/op
Yikes, with light or no multithreading, putting using the mutex is quite a bit faster (go version go1.4 linux/amd64). How well does it do in a multithreaded environment. The following numbers were obtained by inserting the same number of items, but doing so in 4 separate Goroutines to test how well channels do under contention.
BenchmarkSimpleSet-8 2000000 645 ns/op
BenchmarkChannelSimpleSet-8 2000000 913 ns/op
BenchmarkChannelSimpleSet-8 2000000 901 ns/op
Better, but the mutex is still almost 30% faster. Clearly, some of the channel magic is costing us here, and that’s without the extra mental overhead to prevent memory leaks. Golang felt the same way, I think, and that’s why in their standard libraries that get benchmarked, like “net/http,” you’ll almost never find channels, always mutexes.
Clearly, channels are not particularly great for workload throughput, and you’re typically better off using a lock-free ring buffer or even a synchronized queue. Channels as a unit of composition tend to fall short as well. Instead, they are better suited as a coordination pattern, a mechanism for signaling and timing-related code. Ultimately, you must use channels judiciously if you are sensitive to performance.
There are a lot of things in Go that sound great in theory and look neat in demos, but then you start writing real systems and go, “oh wait, that doesn’t actually work.” Once again, channels are a good example of this. The range keyword, which allows you to iterate over a data structure, is reserved to slices, maps, and channels. At first glance, it appears channels provide an elegant way to build your own iterators:
But upon closer inspection, we realize this approach is subtly broken. While it works, if we stop iterating, the loop adding items to the channel will block—the goroutine is leaked. Instead, we must push the onus onto the user to signal the iteration is finished. It’s far less elegant and prone to leaks if not used correctly—so much for channels and goroutines.
Goroutines are nice. They make it incredibly easy to spin off concurrent workers. They also make it incredibly easy to leak things. This shouldn’t be a problem for the intelligent programmer, but for Rob Pike’s beloved Googlers, they can be a double-edged sword.
Dependency Management in Practice
For being a language geared towards Google-sized projects, Go’s approach to managing dependencies is effectively nonexistent. For small projects with little-to-no dependencies, go get works great. But Go is a server language, and we typically have many dependencies which must be pinned to different versions. Go’s package structure and go get do not support this. Reproducible builds and dependency management continue to be a source of frustration for folks trying to build real software with it.
In fairness, dependency management is not an issue with the language per se, but to me, tooling is equally important as the language itself. Go doesn’t actually take an official stance on versioning:
“Go get” does not have any explicit concept of package versions. Versioning is a source of significant complexity, especially in large code bases, and we are unaware of any approach that works well at scale in a large enough variety of situations to be appropriate to force on all Go users. What “go get” and the larger Go toolchain do provide is isolation of packages with different import paths.
Fortunately, the tooling in this area is actively improving. I’m confident this problem can be solved in better ways, but the current state of the art will leave newcomers feeling uneasy.
A Community or a Carousel
Go has an increasingly vibrant community, but it’s profoundly stubborn. My biggest gripe is not with the language itself, but with the community’s seemingly us-versus-them mentality. You’re either with us or against us. It’s almost comical because it seems every criticism of the language, mine included, is prefixed with “I really like Go, but…” to ostensibly diffuse the situation. Parts of the community can seem religious, almost cult-like. The sheer mention of generics is now met with a hearty dismissal. It’s not the Go way.
The attitude of the decision making around the language is unfortunate, and I think Go could really take a page from Rust’s book with respect to its governance model. I agree entirely with the sentiment of “it is a poor craftsman who blames their tools,” but it is an even poorer craftsman who doesn’t choose the best tools at their disposal. I’m not partial to any of my tools. They’re a means to an end, but we should aim to improve them and make them more effective. Community should not breed complacency. With Go, I fear both are thriving.
Despite your hand wringing over the effrontery of Go’s designers to not include your prerequisite features, interest in Go is sky rocketing. Rather than finding new ways to hate a language for reasons that will not change, why not invest that time and join the growing number of programmers who are using the language to write real software today.
This is dangerous reasoning, and it hinders progress. Yes, programmers are using Go to write real software today. They were also writing real software with Java circa 2004. I write Go every day for a living. I work with smart people who do the same. Most of my open-source projects on GitHub are written in Go. I have invested countless hours into the language, so I feel qualified to point out its shortcomings. They are not irreparable, but let’s not just brush them off as people toying with Go and “finding ways to hate it”—it’s insulting and unproductive.
The Good Parts
Alas, Go is not beyond reproach. But at the same time, the language gets a lot of things right. The advantages of a single, self-contained binary are real, and compilation is fast. Coming from C or C++, the compilation speed is a big deal. Cross-compile allows you to target other platforms, and it’s getting even better with Go 1.5.
The garbage collector, while currently a pain point for performance-critical systems, is the focus of a lot of ongoing effort. Go 1.5 will bring about an improved garbage collector, and more enhancements—including generational techniques—are planned for the future. Compared to current cutting-edge garbage collectors like HotSpot, Go’s is still quite young—lots of room for improvement here.
Over the last couple of months, I dipped my toes back in Java. Along with C#, Java used to be my modus operandi. Going back gave me a newfound appreciation for Go’s composability. In Go, the language and libraries are designed to be composable, à la Unix. In Java, everyone brings their own walled garden of classes.
Java is really a ghastly language in retrospect. Even the simplest of tasks, like reading a file, require a wildly absurd amount of hoop-jumping. This is where Go’s simplicity nails it. Building a web application in Java generally requires an application server, which often puts you in J2EE-land. It’s not a place I recommend you visit. In contrast, building a web server in Go takes a couple lines of code using the standard library—no overhead whatsoever. I just wish Java shared some of its generics Kool-Aid. C# does generics even better, implementing them all the way down to the byte-code level without type erasure.
Beyond go get, Go’s toolchain is actually pretty good. Testing and benchmarking are built in, and the data-race detector is super handy for debugging race conditions in your myriad of goroutines. The gofmt command is brilliant—every language needs something like this—as are vet and godoc. Lastly, Go provides a solid set of profiling tools for analyzing memory, CPU utilization, and other runtime behavior. Sadly, CPU profiling doesn’t work on OSX due to a kernel bug.
Although channels and goroutines are not without their problems, Go is easily the best “concurrent” programming language I’ve used. Admittedly, I haven’t used Erlang, so I suspect that statement made some Erlangers groan. Combined with the select statement, channels allow you to solve some problems which would otherwise be solved in a much more crude manner.
Go fits into your stack as a language for backend services. With the work being done by Docker, CoreOS, HashiCorp, Google, and others, it clearly is becoming the language of Infrastructure as a Service, cloud orchestration, and DevOps as well. Go is not a replacement for C/C++ but a replacement for Java, Python, and the like—that much is clear.
Moving Forward
Ultimately, we use Go because it’s boring. We don’t use it because Google uses it. We don’t use it because it’s trendy. We use it because it’s no-frills and, hey, it usually gets the job done assuming you’ve found the right nail. But Go is still in its infancy and has a lot of room for growth and improvement.
I’m cautiously optimistic about Go’s future. I don’t consider myself a hater, I consider myself a hopeful. As it continues to gain a critical mass, I’m hopeful that the language will continue to improve but fearful of its relentless dogma. Go needs to let go of this attitude of “you don’t need that” or “it’s too complicated” or “programmers won’t know how to use it.” It’s toxic. It’s not all that different from your users requesting features after you release a product and telling those users they aren’t smart enough to use them. It’s not on your users, it’s on you to make the UX good.
A language can have considerable depth while still retaining its simplicity. I wish this were the ideal Go embraced, not one of negativity, of pessimism, of “no.” The question is not how can we protect developers from themselves, it’s how can we make them more productive? How can we enable them to solve problems? But just because people are solving problems with Go today does not mean we can’t do better. There is always room for improvement. There is never room for complacency.
My thanks to Dustin Hiatt for reviewing this and his efforts in benchmarking and profiling various parts of the Go runtime. It’s largely Dustin’s work that has helped pave the way for building performance-critical systems in Go.