We encounter a lot of organizations talking about or attempting to implement SRE as part of our consulting at Real Kinetic. We’ve even discussed and debated ourselves, ad nauseam, how we can apply it at our own product company, Witful. There’s a brief, unassuming section in the SRE book tucked away towards the tail end of chapter 32, “The Evolving SRE Engagement Model.” Between the SLIs and SLOs, the error budgets, alerting, and strategies for handling change management, it’s probably one of the most overlooked parts of the book. It’s also, in my opinion, one of the most important.
Chapter 32 starts by discussing the “classic” SRE model and then, towards the end, how Google has been evolving beyond this model. “External Factors Affecting SRE”, under the “Evolving Services Development: Frameworks and SRE Platform” heading, is the section I’m referring to specifically. This part of the book details challenges and approaches for scaling the SRE model described in the preceding chapters. This section describes Google’s own shift towards the industry trend of microservices, the difficulties that have resulted, and what it means for SRE. Google implements a robust site reliability program which employs a small army of SREs who support some of the company’s most critical systems and engage with engineering teams to improve the reliability of their products and services. The model described in the book has proven to be highly effective for Google but is also quite resource-intensive. Microservices only serve to multiply this problem. The organizations we see attempting to adopt microservices along with SRE, particularly those who are doing it as a part of a move to cloud, frequently underestimate just how much it’s about to ruin their day in terms of thinking about software development and operations.
It is not going from a monolith to a handful of microservices. It ends up being hundreds of services or more, even for the smaller companies. This happens every single time. And that move to microservices—in combination with cloud—unleashes a whole new level of autonomy and empowerment for developers who, often coming from a more restrictive ops-controlled environment on prem, introduce all sorts of new programming languages, compute platforms, databases, and other technologies. The move to microservices and cloud is nothing short of a Cambrian Explosion for just about every organization that attempts it. I have never seen this not play out to some degree, and it tends to be highly disruptive. Some groups handle it well—others do not. Usually, however, this brings an organization’s delivery to a grinding halt as they try to get a handle on the situation. In some cases, I’ve seen it take a year or more for a company to actually start delivering products in the cloud after declaring they are “all in” on it. And that’s just the process of starting to deliver, not actually delivering them.
How does this relate to SRE? In the book, Google says a result of moving towards microservices is that both the number of requests for SRE support and the cardinality of services to support have increased dramatically. Because each service has a base fixed operational cost, even simple services demand more staffing. Additionally, microservices almost always imply an expectation of lower lead time for deployment. This is invariably one of the reasons we see organizations adopting them in the first place. This reduced lead time was not possible with the Production Readiness Review model they describe earlier in chapter 32 because it had a lead time of months. For many of the organizations we work with, a lead time of months to deliver new products and capabilities to their customers is simply not viable. It would be like rewinding the clock to when they were still operating on prem and completely defeat the purpose of microservices and cloud.
But here’s the key excerpt from the book: “Hiring experienced, qualified SREs is difficult and costly. Despite enormous effort from the recruiting organization, there are never enough SREs to support all the services that need their expertise.” The authors conclude, “the SRE organization is responsible for serving the needs of the large and growing number of development teams that do not already enjoy direct SRE support. This mandate calls for extending the SRE support model far beyond the original concept and engagement model.”
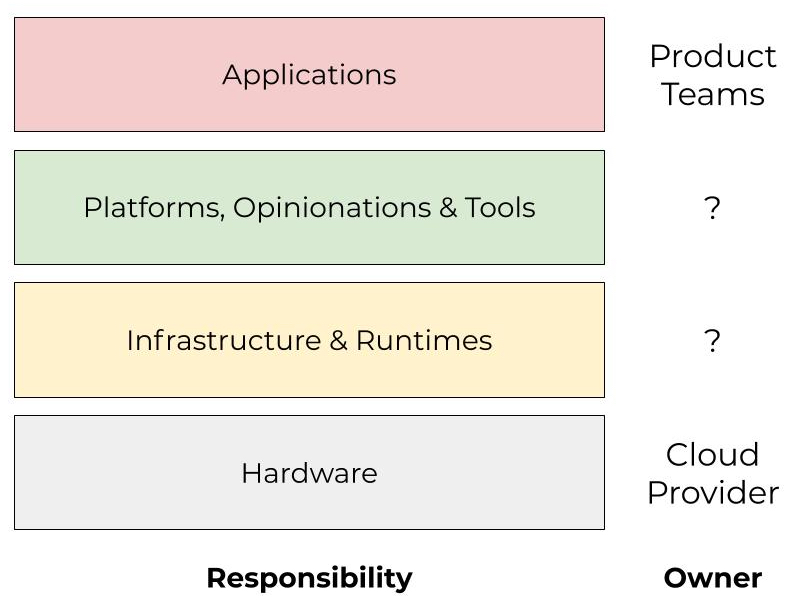
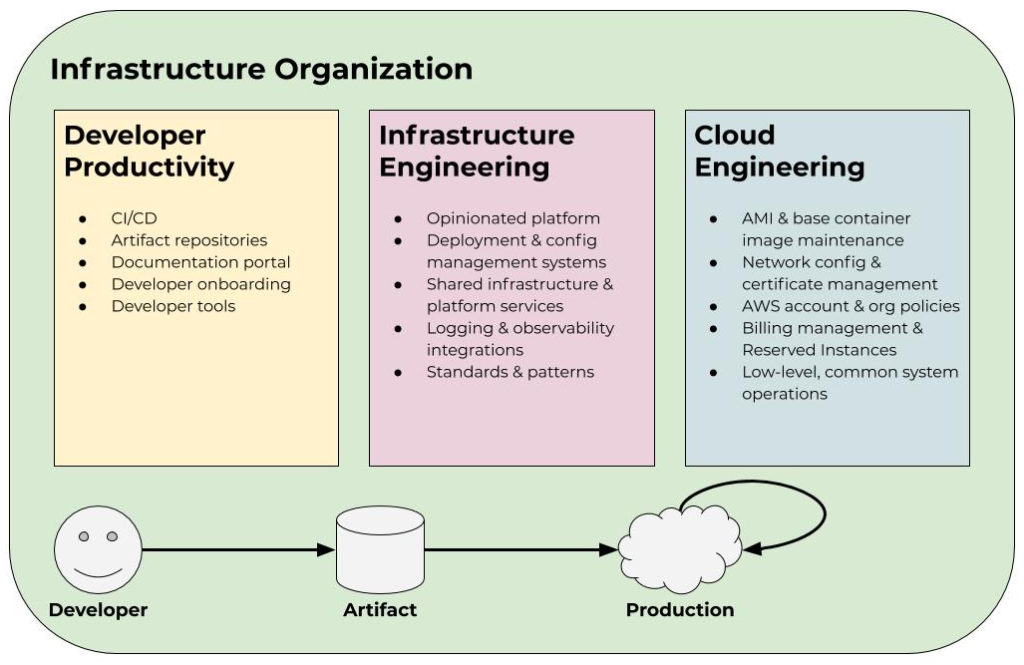
Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
Google enforces standards and opinions around things like programming languages, instrumentation and metrics, logging, and control systems surrounding traffic and load management. The alternative to this is the Cambrian Explosion I described earlier. The authors enumerate the benefits of this approach such as significantly lower operational overhead, universal support by design, faster and lower overhead SRE engagements, and a new engagement model based on shared responsibility rather than either full SRE support or no SRE support. As the authors put it, “This model represents a significant departure from the way service management was originally conceived in two major ways: it entails a new relationship model for the interaction between SRE and development teams, and a new staffing model for SRE-supported service management.”
For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
With microservices, which again almost always hit you with a near-exponential growth rate once you adopt them, you simply cannot expect to have a handful of individuals who are tasked with understanding the entirety of a microservice-based platform and be responsible for it. SRE does not mean developers get to just go back to thinking about code and features. Microservices necessitate developers having skin in the game, and even Google has talked about the challenges of scaling a traditional SRE model and why a different tack is needed.
“The constant growth in the number of services at Google means that most of these services can neither warrant SRE engagement nor be maintained by SREs. Regardless, services that don’t receive full SRE support can be built to use production features that are developed and maintained by SREs. This practice effectively breaks the SRE staffing barrier. Enabling SRE-supported production standards and tools for all teams improves the overall service quality across Google.”
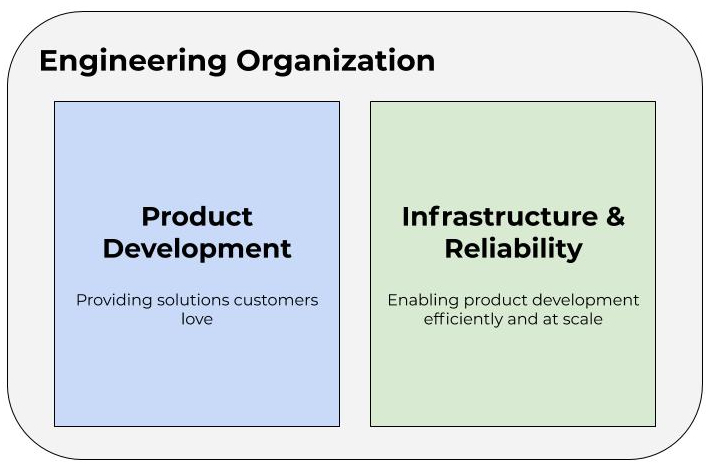
My advice is to stop thinking about SRE as an implementation specifically and instead think about the problems it’s solving a bit more abstractly. It’s unlikely your organization has Google-level resources, so you need to consider the constraints. You need to think about the roles and responsibilities of developers as well as your ops folks. They will change significantly with microservices and cloud out of necessity. You’ll need to think about how to scale DevOps within your organization and, as part of that, what “DevOps” actually means to your organization. In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords. For most mid-to-large-sized companies, some sort of framework- and platform- oriented model is usually needed, similar to what Google describes.
I’ve seen it over and over. This hits companies like a ton of bricks. It requires looking at some hard org problems. A lot of self-reflection that many companies find uncomfortable or just difficult to do. But it has to be done. It’s also an important piece of context when applying the SRE book. Don’t skip over chapter 32. It might just be the most important part of the book.
Real Kinetic helps clients build great engineering organizations. Learn more about working with us.
Follow @tyler_treat