Cloud Identity-Aware Proxy (Cloud IAP) is a free service which can be used to implement authentication and authorization for applications running in Google Cloud Platform (GCP). This includes Google App Engine applications as well as workloads running on Compute Engine (GCE) VMs and Google Kubernetes Engine (GKE) by way of Google Cloud Load Balancers.
When enabled, IAP requires users accessing a web application to login using their Google account and ensure they have the appropriate role to access the resource. This can be used to provide secure access to web applications without the need for a VPN. This is part of what Google now calls BeyondCorp, which is an enterprise security model designed to enable employees to work from untrusted networks without a VPN. At Real Kinetic, we frequently bump into companies practicing Death-Star security, which is basically relying on a hard outer shell to protect a soft, gooey interior. It’s simple and easy to administer, but it’s also vulnerable. That’s why we always approach security from a perspective of defense in depth.
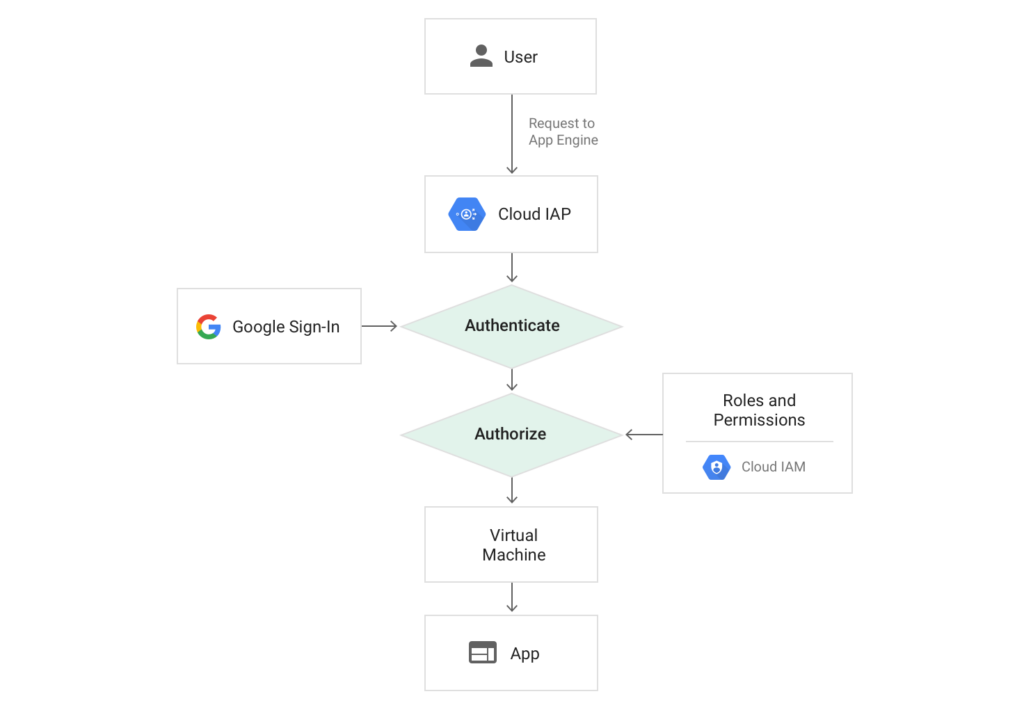
However, in this post I want to explore how we can use Cloud IAP to implement authentication and authorization for APIs in GCP. Specifically, I will use App Engine, but the same applies to resources behind an HTTPS load balancer. The goal is to provide a way to securely expose APIs in GCP which can be accessed programmatically.
Configuring Identity-Aware Proxy
Cloud IAP supports authenticating service accounts using OpenID Connect (OIDC). A service account belongs to an application instead of an individual user. You authenticate a service account when you want to allow an application to access your IAP-secured resources. A GCP service account can either have GCP-managed keys (for systems that reside within GCP) or user-managed keys (for systems that reside outside of GCP). GCP-managed keys cannot be downloaded and are automatically rotated and used for signing for a maximum of two weeks. User-managed keys are created, downloaded, and managed by users and expire 10 years from creation. As such, key rotation must be managed by the user as appropriate. In either case, access using a service account can be revoked either by revoking a particular key or removing the service account itself.
An IAP is associated with an App Engine application or HTTPS Load Balancer. One or more service accounts can then be added to an IAP to allow programmatic authentication. When the IAP is off, the resource is accessible to anyone with the URL. When it’s on, it’s only accessible to members who have been granted access. This can include specific Google accounts, groups, service accounts, or a general G Suite domain.
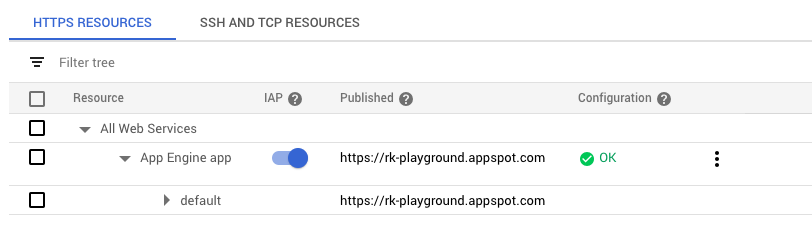
IAP will create an OAuth2 client ID for OIDC authentication which can be used by service accounts. But in order to access our API using a service account, we first need to add it to IAP with the appropriate role. We’ll add it as an IAP-secured Web App User, which allows access to HTTPS resources protected by IAP. In this case, my service account is called “IAP Auth Test,” and the email associated with it is iap-auth-test@rk-playground.iam.gserviceaccount.com.
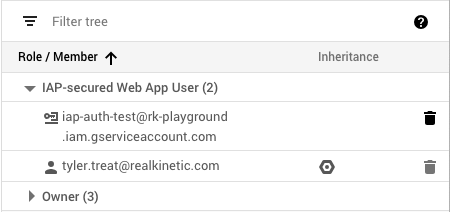
As you can see, both the service account and my user account are IAP-secured Web App Users. This means I can access the application using my Google login or using the service account credentials. Next, we’ll look at how to properly authenticate using the service account.
Authenticating API Consumers
When you create a service account key in the GCP console, it downloads a JSON credentials file to your machine. The API consumer needs the service account credentials to authenticate. The diagram below illustrates the general architecture of how IAP authenticates API calls to App Engine services using service accounts.
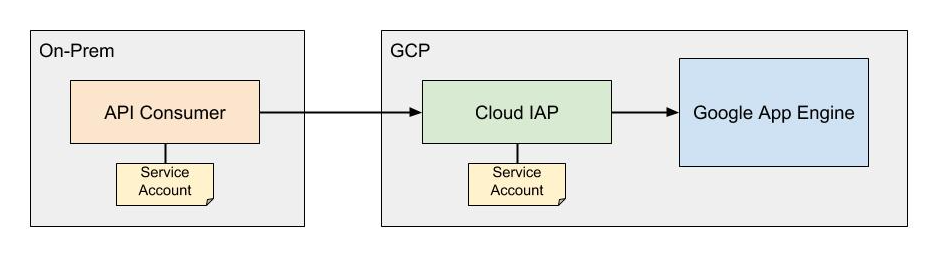
In order to make a request to the IAP-authenticated resource, the consumer generates a JWT signed using the service account credentials. The JWT contains an additional target_audience claim containing the OAuth2 client ID from the IAP. To find the client ID, click on the options menu next to the IAP resource and select “Edit OAuth client.” The client ID will be listed on the resulting page. My code to generate this JWT looks like the following:
This assumes you have access to the service account’s private key. If you don’t have access to the private key, e.g. because you’re running on GCE or Cloud Functions and using a service account from the metadata server, you’ll have to use the IAM signBlob API. We’ll cover this in a follow-up post.
This JWT is then exchanged for a Google-signed OIDC token for the client ID specified in the JWT claims. This token has a one-hour expiration and must be renewed by the consumer as needed. To retrieve a Google-signed token, we make a POST request containing the JWT and grant type to https://www.googleapis.com/oauth2/v4/token.
This returns a Google-signed JWT which is good for about an hour. The “exp” claim can be used to check the expiration of the token. Authenticated requests are then made by setting the bearer token in the Authorization header of the HTTP request:
Authorization: Bearer <token>
Below is a sequence diagram showing the process of making an OIDC-authenticated request to an IAP-protected resource.
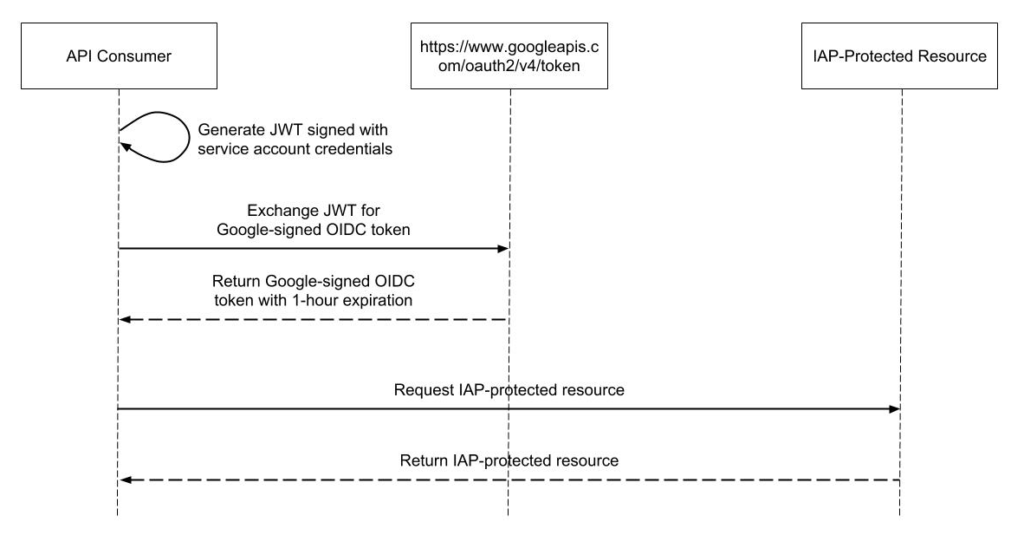
Because this is quite a bit of code and complexity, I’ve implemented the process flow in Java as a Spring RestTemplate interceptor. This transparently authenticates API calls, caches the OIDC token, and handles automatically renewing it. Google has also provided examples of authenticating from a service account for other languages.
With IAP, we’re able to authenticate and authorize requests at the edge before they even reach our application. And with Cloud Audit Logging, we can monitor who is accessing protected resources. Be aware, however, that if you’re using GCE or GKE, users who can access the application-serving port of the VM can bypass IAP authentication. GCE and GKE firewall rules can’t protect against access from processes running on the same VM as the IAP-secured application. They can protect against access from another VM, but only if properly configured. This does not apply for App Engine since all traffic goes through the IAP infrastructure.
Alternative Solutions
There are some alternatives to IAP for implementing authentication and authorization for APIs. Apigee is one option, which Google acquired not too long ago. This is a more robust API-management solution which will do a lot more than just secure APIs, but it’s also more expensive. Another option is Google Cloud Endpoints, which is an NGINX-based proxy that provides mechanisms to secure and monitor APIs. This is free up to two million API calls per month.
Lastly, you can also simply implement authentication and authorization directly in your application instead of with an API proxy, e.g. using OAuth2. This has downsides in that it can introduce complexity and room for mistakes, but it gives you full control over your application’s security. Following our model of defense in depth, we often encourage clients to implement authentication both at the edge (e.g. by ensuring requests have a valid token) and in the application (e.g. by validating the token on a request). This way, we avoid implementing a Death-Star security model.