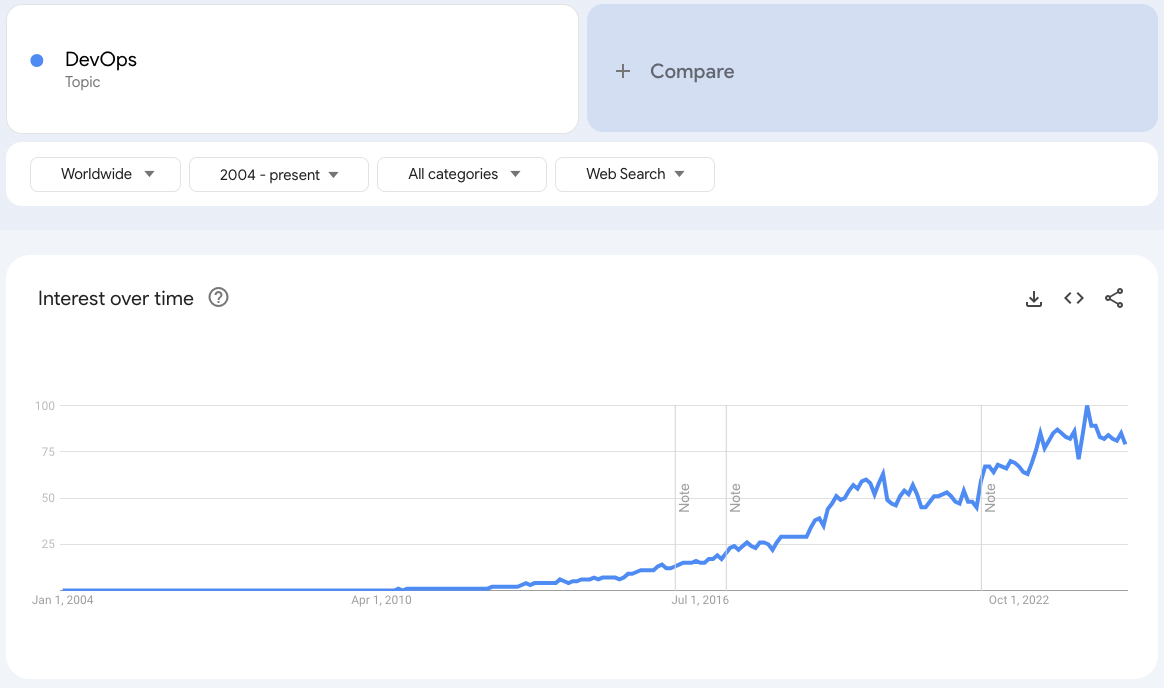
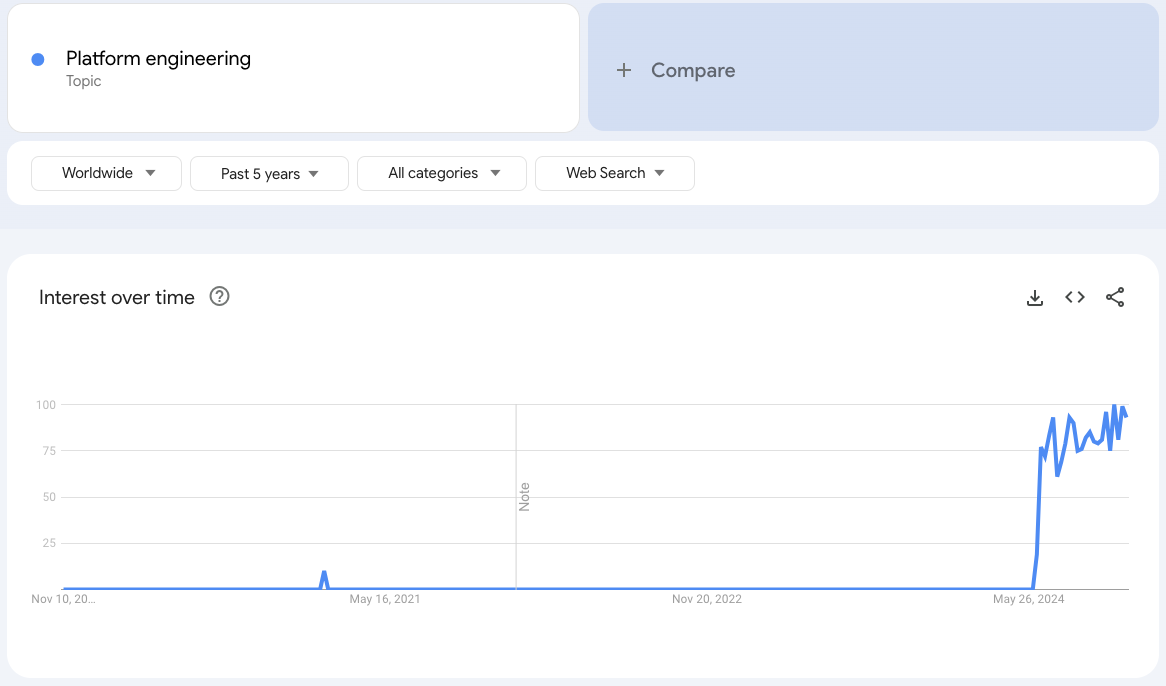
More and more established businesses are attempting to reinvent themselves as technology companies. At the heart of this is the digital transformation, a journey many organizations are undertaking in order to better compete and serve their customers. As a result, companies are pouring tons of cash into digital transformation strategies. For some, this means broader adoption of agile or DevOps practices. For others, it’s modernizing product offerings or moving to the cloud. Regardless of the changes, many are struggling to find success transforming themselves due to low throughput, quality issues, or failing to deliver the right thing at the right time. In a few cases, digital transformation has ended in outright disaster.
What is it that these companies are really after? To solve new problems in new ways through innovation? To more rapidly adapt to the changing market? To protect existing revenue? Any leader worth their salt will say all of these are important outcomes, so how do you even begin to make a “digital transformation” actionable? What are we transforming to? How do we know when we’ve arrived?
The reason so many digital transformations fail has to do with how IT is usually positioned within mature, established businesses. I believe what these companies are really after is not a digital transformation—whatever that might be—but rather an organizational one that radically changes the way the business operates. One that redefines what IT means in the context of building software. The technology is incidental to this cultural shift which involves the intersection of people, processes, and innovation. In order to be successful, these organizations need to become technology product companies.
The Genesis of IT
There is an inertia within organizations to overvalue tactics and undervalue strategy. This is true not just of mature, established businesses but really all businesses, startups included. In fact, it’s this exact reason most startups fail. A lack of clear strategy and guiding vision precludes even the best execution from delivering success outside of the odd unicorn (after all, someone has to win the Powerball). Established businesses, however, already have a reliable cash flow engine to fall back on. There is much more margin for error when it comes to both strategy and execution, but this peacetime mentality leads to disruption. Many leaders have begun to recognize this and act on it, falling right back to what they know best—tactics.
Why do companies and managers tend to bias towards tactics over strategy in software development? It comes back to the genesis of IT. Historically, IT was about managing computers, networks, email, phone systems, and other technical areas of the business. While this is still true today, the result of software eating the world has caused that scope to broaden significantly. But for mature, established businesses, IT has long been viewed as a cost center, and the mandate for an IT leader is cost minimization. This is in spite of the fact that the business has shifted away from humans, paper forms, and telephones to automation and software-based solutions. IT has always existed to support business operations, first by managing the technology the business depended on, now by building it. The only real change was IT transforming from a servant of the business to a partner of it.
Consequently, there are two key directives for a traditional IT organization: carry out the orders of the business and minimize cost. These goals inherently lead to a project mindset that is output- and task-oriented. Thus, IT has always been tactical and execution-minded in nature.
A Spotter’s Guide to Project-Minded IT
There are three ways to identify a project-minded IT organization. First, if both software engineers and more traditional IT roles like hardware support or help desk report up to a CIO, it’s likely a project-minded organization. In this case, it’s all just lumped into one group called “IT.”
This contrasts with product-minded companies which place IT responsibilities under a CIO, whose directive is still cost minimization, and product development responsibilities under a CTO and/or CPO (Chief Product Officer), whose directive is strategic investment. There are two distinct groups, IT and Product Development or R&D. It’s more common to see CTOs or CPOs at newer, technology-first companies than it is at mature, established businesses since this requires a major realignment. This alignment, however, is why we see many of the execution issues at companies attempting to “digitally transform” themselves.
Second, if there is a clear separation between IT or development and the business, there’s a good chance it’s a project-minded organization. This might be signaled by business partners, business analysts, or product owners who provide teams with implementation requirements and act as a backlog administrator. Developers might not have a good understanding of who their customers are or they view the business partner as the customer. This can also be signaled by frequently changing priorities, an ever-growing backlog of tasks, or unaddressed tech debt piling up. The team is typically not cross-functional, consisting only of developers and a business partner. Marty Cagan refers to these as delivery teams, and they are purely output-driven.
Alternatively, the team may be cross-functional with some form of designer (often oriented more towards UI than UX) and product manager, but it’s still governed by outputs. The product manager’s role is closer to that of a project manager armed with a product roadmap, and the closest thing developers have to product discovery is design and usability testing. Cagan refers to these as feature teams. Both delivery and feature teams exist to serve the business. These are the teams you’ll find at most companies building software.
At product-minded companies, teams are cross-functional with designers, UX, engineers, and product, and they are measured by outcomes, not outputs. This focus on outcomes means that the team is empowered to figure out the best way to solve the problems they’ve been asked to solve rather than being fed a list of features to build. These teams have an intimate understanding of their customers and interact with them regularly to perform product discovery and validate solutions. These are product teams in the truest sense but also quite rare.
The last way to spot a project-minded organization might be the most obvious. If the roadmap has a clear end point, it’s a project. Here, an IT organization treats building a software solution the same way it treats installing a new phone system. When the project is completed, teams or resources are reallocated to new projects and one of two things happen: it’s either dumped on another team to maintain and extend or no one sticks around to support it. The finished project languishes or former developers are told to context switch to it reactively and at the whims of the business. Engineers are treated as interchangeable and teams are not particularly durable or mission-driven but rather task-driven.
Product-minded companies instead embrace the virtues of minimum viable product, shipping incremental value, validating ideas, and iteration. The product manager provides a vision that unites the team in a common mission. Products are not “completed,” rather they grow and evolve. There is an emphasis on business outcomes over task outputs. Managers understand that teams are composed of people with diverse skills who are not easily fungible but who might be better suited to different phases of a product’s lifecycle. Members of a team might shift focus to other areas and priorities over time, but always in support of the team’s mission.
The Philosophical Dilemma of the Stoplight
A tactics-first mindset results in a propensity to treat software development like an assembly line. We can see this with the recent adoption of ideas from the Toyota Production System and lean manufacturing as it’s applied to software development. This emphasis on tactics causes managers to view product development as an optimization problem—if we just optimize the right set of tactics and practices, we can significantly improve throughput and quality at scale. This has led to the rise in packaged frameworks and processes like SAFe, LeSS, DAD, and Nexus as well as tactics like agile, pair programming, and test-driven development at large organizations.
The assembly-line mindset aims to take developers of arbitrary skill and background, run them through a prescribed process, and get high-quality, high-output results on the other end. I’ve never seen this deliver the desired outcomes in practice, at least not to the degree most leaders hope.
On the surface, mass production and software development share a lot of similarities. Both require quality standards, collaboration between groups of specialized workers, and repeatability. However, the reality is they are quite different from each other. A manufacturing assembly line is optimized to produce the exact same product over and over again, efficiently and reliably. Software products, especially Software as a Service, are heterogeneous. While we seek a process that produces consistent results, each product and situation is unique. Too prescriptive, and we end up with a rigid process that yields poor results and low-throughput. Too unstructured, and we end up with inconsistent and unreliable output.
Our Head of Client Experience Mike Taylor refers to this as the Stoplight Problem. To demonstrate, ask a roomful of people what to do at each phase of a stoplight. On green, everyone says “Go.” On red, “Stop.” And on yellow? The answers vary—even more so with the introduction of flashing yellow lights. How close are we to the light? How fast are we traveling? Are the roads icy? What are the cars in front or behind us doing? What happens at a yellow light is entirely context-dependent and situational. It comes down to making informed choices in the moment without an authoritative, black-and-white determination.
Execution and delivery issues invariably come down to one thing: the yellow light. The green and red lights are binary indicators. There are clear right and wrong actions to take. These are things that can be taught and learned—where tactics matter—but the yellow light comes down to making good decisions. This is something organizations struggle with at scale. How do you trust your teams to make good decisions? As a result, they end up making those decisions top-down in a command-and-control or assembly-line fashion. This is how organizations end up with delivery and feature teams. What’s needed is a sort of meta process or process for encouraging good decision making.
Empowered Product Teams
The emphasis on tactics isn’t limited to traditional project-minded IT organizations. Tactics are more visible and measurable. To a manager, tactics feel like work is happening, but they are rarely the difference maker for a company.
To illustrate, imagine handing out a bunch of axes to a group of people and telling them to go collect some wood. You might even teach them the proper technique for chopping down a tree. What happens next? Chaos. Confusion. A general sense of wandering in the woods. What kind of timber do we need? How much? What is it used for? How do we move it? Watching an army of people swinging axes is going to look like a lot of work is going on, but is it work that matters? You might follow people around, directing them where to go, which trees to cut down, and where to move them, but this won’t scale very well.
Without a guiding vision, we’re left with a bunch of people wandering in the woods swinging axes. Work happens, things get done—maybe even things that matter—but it’s haphazard and inefficient. More often than not, though, we’re always two weeks from completion because there isn’t clarity on where we’re trying to be. In agile terminology, we’re iterating to nowhere.
Our response might be to micromanage or implement the assembly-line process, turning our teams into feature factories. In my experience, this creates new challenges. In the first case, by grinding throughput to a halt, and in the second case, by failing to address the Stoplight Problem. The solution is a combination of vision, strategy, and execution.
A vision is a mental image of what the future could be like. It’s a grand and idealistic state, not something that can be achieved in a short amount of time. A shared vision empowers teams to make better decisions independently.
Strategy consists of a plan with decreasing fidelity. Some organizations attempt to plan 12 to 18 months out in a very waterfall-like fashion, and unless you’re sending a rocket into space, it just doesn’t work. A strategy is really a series of goals that get progressively fuzzier the further you go out. While a vision usually isn’t directly actionable, goals are both actionable and attainable in support of the overarching vision. We can break our strategy down into sets of three-month goals, which allows us to adjust course as needed. This is important since our goals are increasingly fuzzy. The key here is that strategy and goals are not dictated to teams. There needs to be give and take and dialog. OKRs can be a good tool for facilitating this.
At Real Kinetic, we hold quarterly leadership offsites to revisit our vision and strategy, course-correct, and ensure we have a general sense of alignment. We help our clients do the same within their product development organizations. The challenge with strategy is it looks like talking, while tactics look like working, even if it’s work that doesn’t truly move the needle. This is a cognitive bias leaders and managers should be aware of because it can trap us into focusing on tactics that aren’t framed by a clear vision and strategy.
Execution is all about hitting the goals we lay out in our strategy. This is where tactics come into play, but rather than providing teams with a list of features to implement or tasks to perform, we empower them to make good decisions. This is made possible by our guiding vision and cross-functional, mission-driven product teams. Our product manager is figuring out what lies ahead and helping plan the best course of action for realizing our vision. They are looking at value and business viability risks for the product. Our designer is looking at usability risks, and our tech lead is looking at feasibility, making estimations, and contributing to the strategy in order to avoid potential obstacles. You’ll notice that nowhere have we mentioned agile or scrum because these are specific tactics for managing execution. Together, the team is determining execution and discovering a solution that moves the business towards the ideal state set forth by its leadership.
Becoming a Technology Product Company
The struggle with digital transformation is it doesn’t get at the heart of the issue. It’s a tactical response to a tangible, yet ultimately inconsequential, part of the problem. The problem is not due to technology or innovation or particular tactics, it’s due to organizational alignment and execution deficiencies. Unfortunately, the former is more visible and more easily acted on than the latter.
The transformation that organizations are actually after is becoming a technology product company. This requires empowered product teams in combination with vision, strategy, and execution. Most companies focus on the execution because it’s easier, but it’s not sufficient. Empowered product teams require a shared vision that enables them to make good decisions without the need for an overly regimented or top-down process. This is the only effective way I’ve seen software companies scale throughput and quality. Don’t let your organization think it’s building a boulevard when it’s actually planting perennials next to potholes.
Real Kinetic helps clients build great product development organizations. Learn more about working with us.