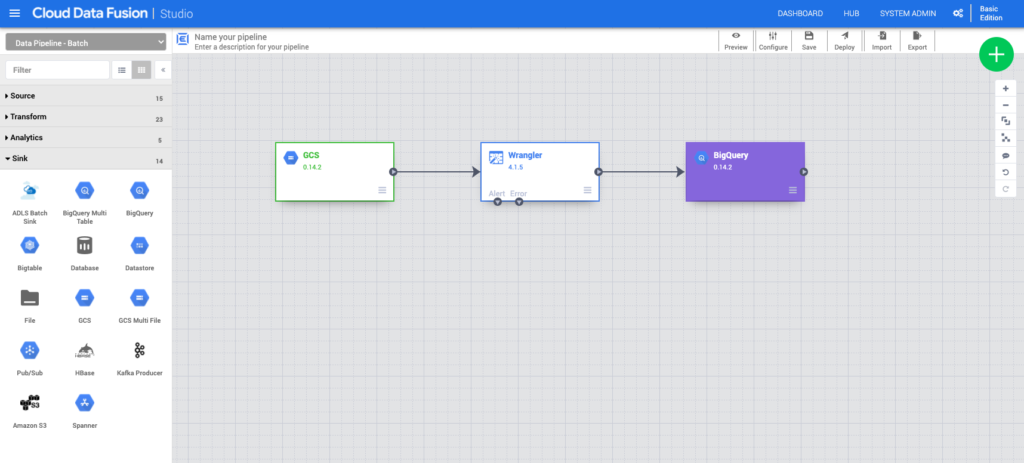
Part of what we do at Real Kinetic is give companies confidence to ship software in the cloud. Many of our clients are large organizations that have been around for a long time but who don’t always have much experience when it comes to cloud. Others are startups and mid-sized companies who may have some experience, but might just want another set of eyes or are looking to mature some of their practices. Whatever the case, one of the things we frequently talk to our clients about is the value of both serverless and managed services. We have found that these are critical to getting big wins with small teams on tight deadlines in the cloud. Serverless in particular has been key to helping clients get some big wins in ways others didn’t think possible.
We often get pulled into a company to help them develop and launch new products in the cloud. These are typically high-profile projects with tight deadlines. These deadlines are almost always in terms of months, usually less than six. As a result, many of the executives and managers we talk to in these situations are skeptical of their team’s ability to execute on these types of timeframes. Whether it’s lack of cloud experience, operations and security concerns, compliance issues, staffing constraints, or some combination thereof, there’s always a reason as to why it can’t be done.
And then, some months later, it gets done.
Mental Model of the Cloud
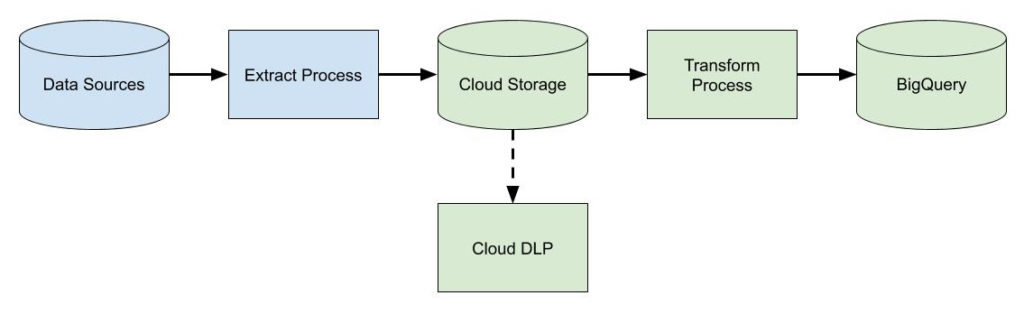
The skepticism is valid. Often people’s mental model of the cloud is something like this:
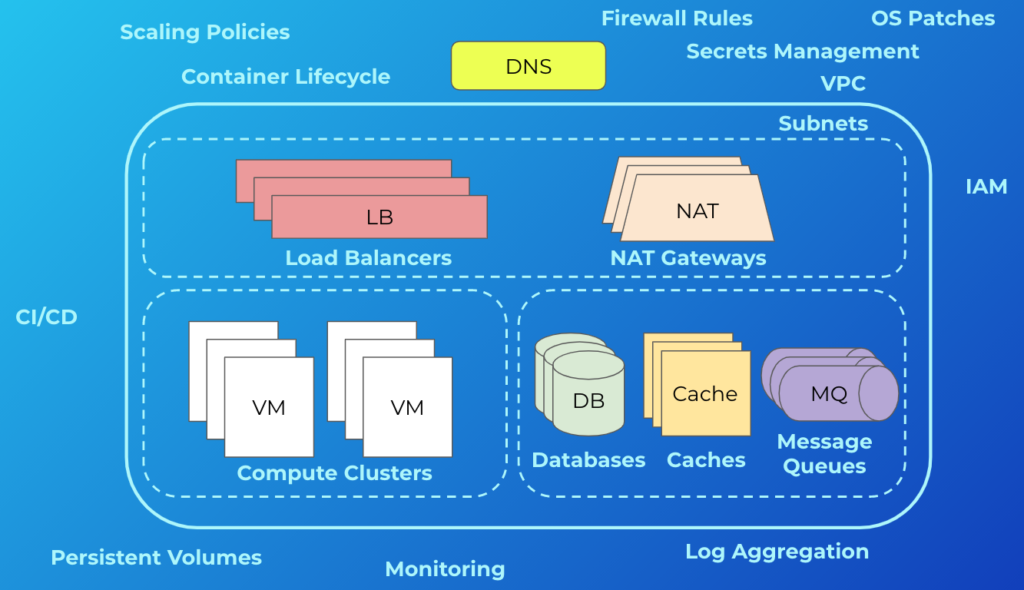
More often than not, this is what cloud infrastructure looks like. In addition to what’s shown, there are other concerns. These include things like managing backups and disaster recovery, multi-zone or regional deployments, VM images, and reserved instances. It can be deceiving because simply getting an app running in this environment isn’t terribly difficult, and most engineers will tell you that—these are the “day-one” costs. But engineers don’t tend to be the best at giving estimates while still undervaluing their own time. The minds of most seasoned managers, however, will usually go to the “day-two” costs—what are the ongoing maintenance and operations costs, the security and compliance considerations, and the staffing requirements? This is why we consistently see so much skepticism. If this is also your initial foray into the cloud, that’s a lot of uncertainty! A manager’s job, after all, is to reduce uncertainty.
We’ve been there. We’ve also had to manage those day-two costs. I’ve personally gone through the phases of building a complex piece of software in the cloud, having to maintain one, having to manage a team responsible for one, and having to help a team go through the same process as an outside consultant. Getting that perspective has helped me develop an appreciation for what it really means to ship software. It’s why we like to take a different tack at Real Kinetic when it comes to cloud.
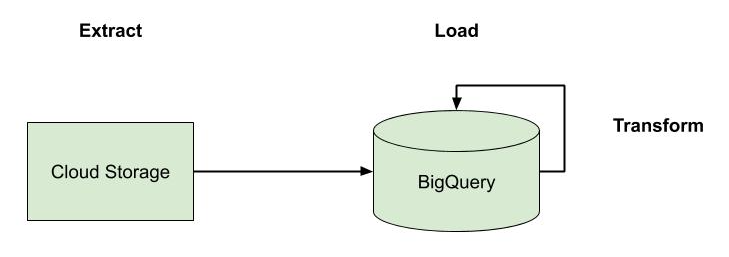
We are big on picking a cloud platform and going all-in on it. Whether it’s AWS, GCP, or Azure—pick your platform, embrace its capabilities, and move on. That doesn’t mean there isn’t room to use multiple clouds. Some platforms are better than others in different areas, such as data analytics or machine learning, so it’s wise to leverage the strengths of each platform where it makes sense. This is especially true for larger organizations who will inevitably span multiple clouds. What we mean by going “all-in” on a platform, particularly as it relates to application development, is sidestepping the trap that so many organizations fall into—hedging their bets. For a variety of reasons, many companies will take a half measure when adopting a cloud platform by avoiding things like managed services and serverless. Vendor lock-in is usually at the top of their list of concerns. Instead, they end up with something akin to the diagram above, and in doing so, lose out on the differentiated benefits of the platform. They also incur significantly more day-two costs.
The Value and Cost of Serverless
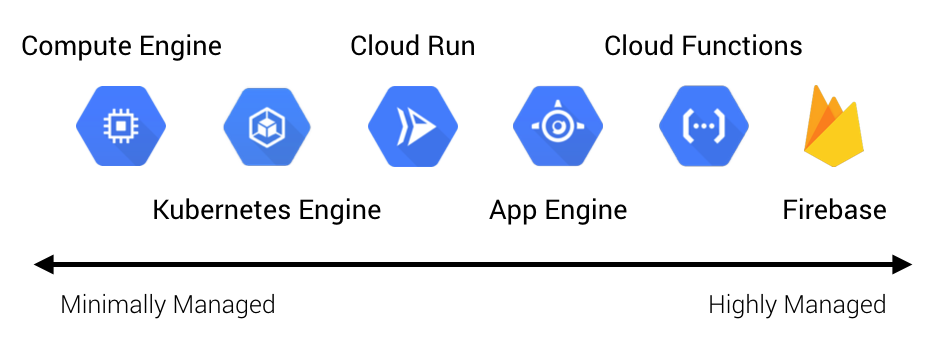
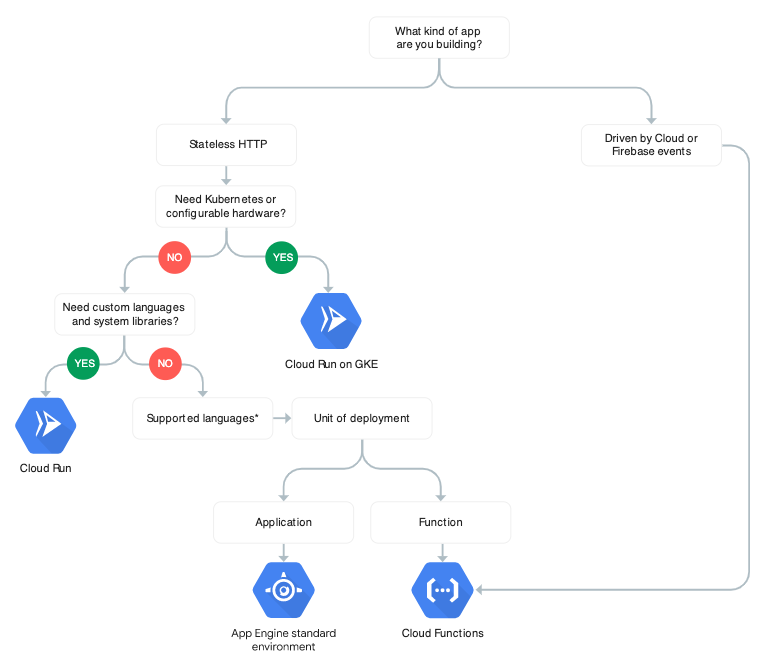
We spend a lot of time talking to our clients about this trade-off. With managers, it usually resonates when we ask if they want their people focusing on shipping business value or doing commodity work. With engineers, architects, or operations folks, it can be more contentious. On more than a few occasions, we’ve talked clients out of using Kubernetes for things that were well-suited to serverless platforms. Serverless is not the right fit for everything, but the reality is many of the workloads we encounter are primarily CRUD-based microservices. These can be a good fit for platforms like AWS Lambda, Google App Engine, or Google Cloud Run. The organizations we’ve seen that have adopted these services for the correct use cases have found reduced operations investment, increased focus on shipping things that matter to the business, accelerated delivery of new products, and better cost efficiency in terms of infrastructure utilization.
If vendor lock-in is your concern, it’s important to understand both the constraints and the trade-offs. Not all serverless platforms are created equal. Some are highly opinionated, others are not. In the early days, Google App Engine was highly opinionated, requiring you to use its own APIs to build your application. This meant moving an application built on App Engine was no small feat. Today, that is no longer the case; the new App Engine runtimes allow you to run just about any application. Cloud Run, a serverless container platform, allows you to deploy a container that can run anywhere. The costs are even less. On the other hand, using a serverless database like Cloud Firestore or DynamoDB requires using a proprietary API, but APIs can be abstracted.
In order to decide if the trade-off makes sense, you need to determine three things:
- What is the honest likelihood you’ll need to move in the future?
- What are the switching costs—the amount of time and effort needed to move?
- What is the value you get using the solution?
These are not always easy things to determine, but the general rule is this: if the value you’re getting offsets the switching costs times the probability of switching—and it often does—then it’s not worth trying to hedge your bet. There can be a lot of hidden considerations, namely operations and development overhead and opportunity costs. It can be easy to forget about these when making a decision. In practice, vendor lock-in tends to be less about code portability and more about capability lock-in—think things like user management, Identity and Access Management, data management, cloud-specific features and services, and so forth. These are what make switching hard, not code.
Another concern we commonly hear with serverless is cost. In our experience, however, this is rarely an issue for appropriate use cases. While serverless can be more expensive in terms of cloud spend for some situations, this cost is normally offset by the reduced engineering and ongoing operations costs. Using serverless and managed services for the right things can be quite cost-effective. This may not always hold true, such as for large organizations who can negotiate with providers for committed cloud spend, but for many cases it makes sense.
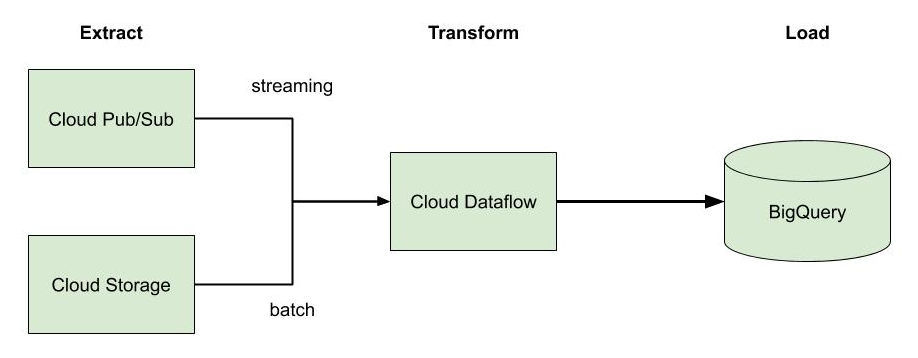
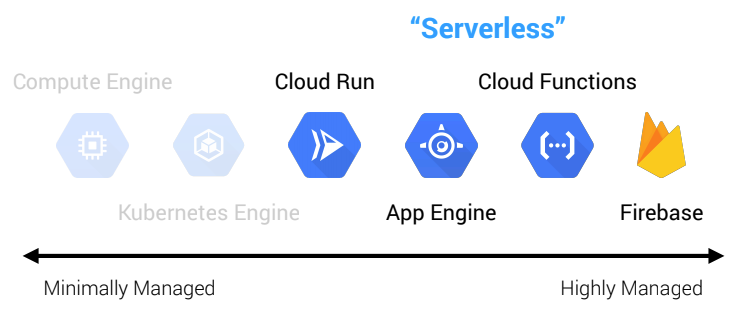
Serverless isn’t just about compute. While people typically associate serverless with things like Lambda or Cloud Functions, it actually extends far beyond this. For example, in addition to its serverless compute offerings (Cloud Run, Cloud Functions, and App Engine), GCP has serverless storage (Cloud Storage, Firestore, and Datastore), serverless integration components (Cloud Tasks, Pub/Sub, and Scheduler), and serverless data and machine learning services (BigQuery, AutoML, and Dataflow). While each of these services individually offers a lot of value, it’s not until we start to compose them together in different ways where we really see the value of serverless appear.
Serverless vs. Managed Services
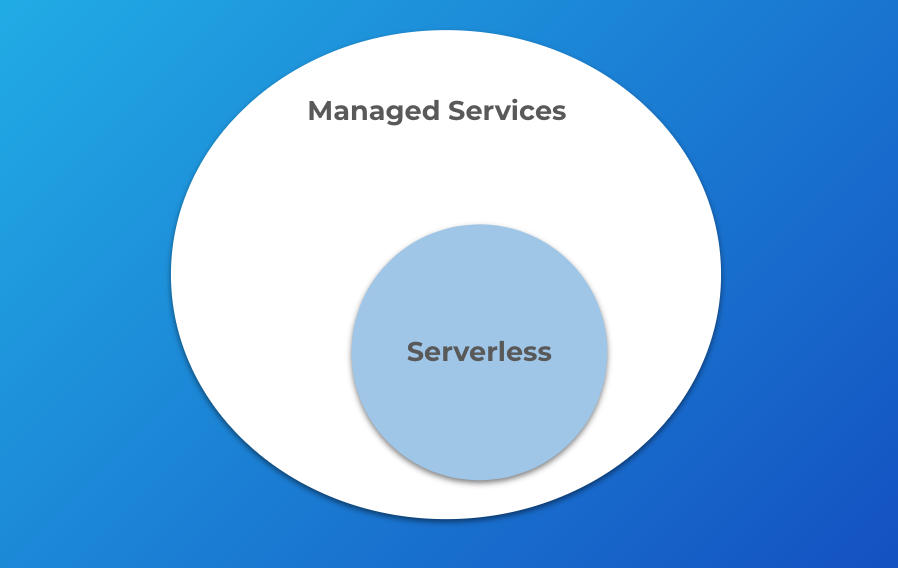
Some might consider the services I mentioned above “managed services”, so let me clarify that. We generally talk about “serverless” being the idea that the cloud provider fully manages and maintains the server infrastructure. This means the notion of “managed services” and “serverless” are closely related, but they are also distinct.
A serverless product is also managed, but not all managed services are serverless. That is to say, serverless is a subset of managed services.
Serverless means you stop thinking about the concept of servers in your architecture. This broadly encompasses words like “servers”, “instances”, “nodes”, and “clusters.” Continuing with our GCP example, these words would be associated with products like GKE, Dataproc, Bigtable, Cloud SQL, and Spanner. These services are decidedly not serverless because they entail some degree of managing and configuring servers or clusters, even though they are managed services.
Instead, you start thinking in terms of APIs and services. This would be things like Cloud Functions, Dataflow, BigQuery, Cloud Run, and Firestore. These have no servers or clusters. They are simply APIs that you interact with to build your applications. They are more specialized managed services.
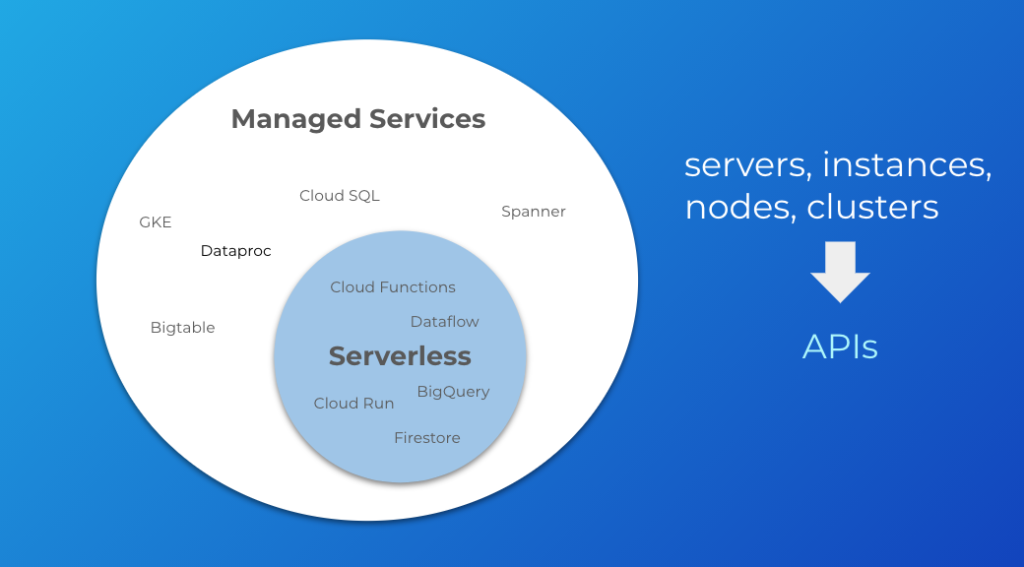
Why does this distinction matter? It matters because of the ramifications it has for where we invest our time. Managing servers and clusters is going to involve a lot more operations effort, even if the base infrastructure is managed by the cloud provider. Much of this work can be considered “commodity.” It is not work that differentiates the business. This is the trade-off of getting more control—we take on more responsibility. In rough terms, the managed services that live outside of the serverless circle are going to be more in the direction of “DevOps”, meaning they will involve more operations overhead. The managed services inside the serverless circle are going to be more in the direction of “NoOps”. There is still work involved in using them, but the line of responsibility has moved upwards with the cloud provider responsible for more. We get less control over the infrastructure, but that means we can focus more on the business outcomes we develop on top of that infrastructure.
In fairness, it’s not always a black-and-white determination. Things can get a little blurry since serverless might still provide some degree of control over runtime parameters like memory or CPU, but this tends to be limited in comparison to managing a full server. There might also be some notion of “instances”, as in the case of App Engine, but that notion is much more abstract. Finally, some services appear to straddle the line between managed service and serverless. App Engine Flex, for instance, allows you to SSH into its VMs, but you have no real control over them. It’s a heavily sandboxed environment.
Why Serverless?
Serverless enables focusing on business outcomes. By leveraging serverless offerings across cloud platforms, we’ve seen product launches go from years to months (and often single-digit months). We’ve seen release cycles go from weeks to hours. We’ve seen development team sizes go from double digits to a few people. We’ve seen ops teams go from dozens of people to just one or two. It’s allowed these people to focus on more differentiated work. It’s given small teams of people a significant amount of leverage.
It’s no secret. Serverless is how we’ve helped many of our clients at Real Kinetic get big wins with small teams on tight deadlines. It’s not always the right fit and there are always trade-offs to consider. But if you’re not at least considering serverless—and more broadly, managed services—then you’re not getting the value you should be getting out of your cloud platform. Keep in mind that it doesn’t have to be all or nothing. Find the places where you can leverage serverless in combination with managed services or more traditional infrastructure. You too will be surprising and impressing your managers and leadership.
Follow @tyler_treat