I recently wrote about the importance of understanding decision impact and why it’s important for building an empathetic engineering culture. I presented the distinction between pain displacement and pain deferral, and this was something I wanted to expand on a bit.
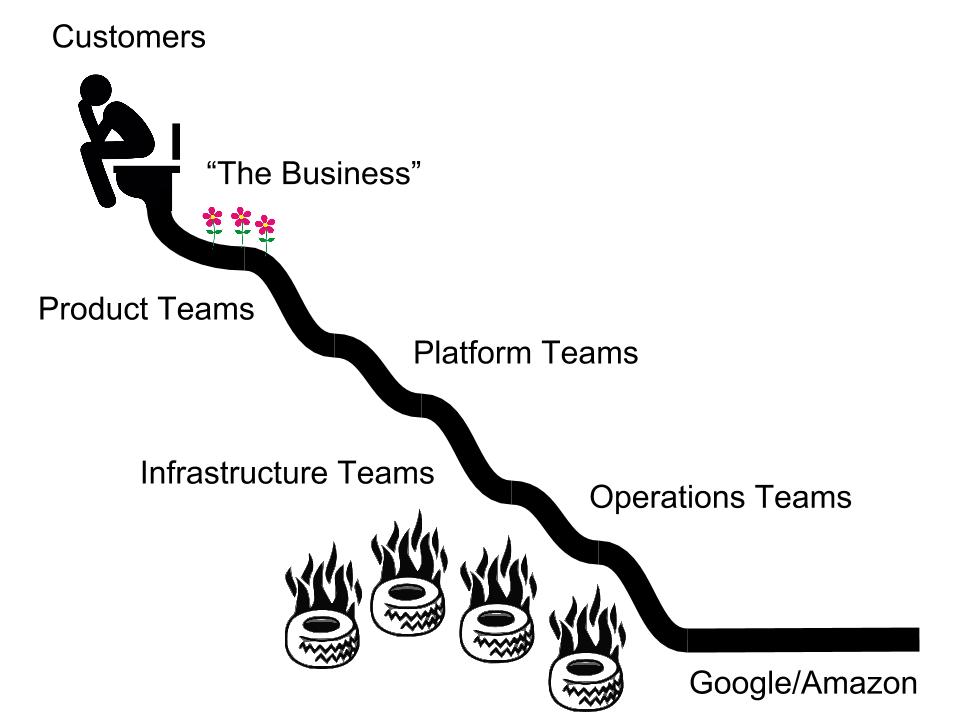
When you distill it down, I think what’s at the heart of a lot of engineering orgs is this idea of “pain-driven development.” When a company grows to a certain size, it develops limbs, and each of these limbs has its own pain receptors. This is when empathy becomes important because it becomes harder and less natural. These limbs of course are teams or, more generally speaking, silos. Teams have a natural tendency to operate in a way that minimizes the amount of pain they feel.
It’s time for some game theory: pain is a zero-sum game. By always following the path of least resistance, we end up displacing pain instead of feeling it. This is literally just instinct. In other words, by making locally optimal choices, we run the risk of losing out on a globally optimal solution. Sometimes this is an explicit business decision, but many times it’s not.
Tech debt is a common example of when pain displacement is a deliberate business decision. It’s pain deferral—there’s pain we need to feel, but we can choose to feel it later and in the meantime provide incremental value to the business. This is usually a team choosing to apply a bandaid and coming back to fix it later. “We have this large batch job that has a five-minute timeout, and we’re sporadically seeing this timeout getting hit. Why don’t we just bump up the timeout to 10 minutes?” This is a bandaid, and a particularly poor one at that because, by Parkinson’s law, as soon as you bump up the timeout to 10 minutes, you’ll start seeing 11-minute jobs, and we’ll be having the same discussion over again. I see the exact same types of discussions happening with resource provisioning: “we’re hitting memory limits—can we just provision our instances with more RAM?” “We’re pegging CPU. Obviously we just need more cores.” Throwing hardware at the problem is the path of least resistance for the developers. They have a deliverable in front of them, they have a lot of pressure to ship, this is how they do it. It’s a greedy algorithm. It minimizes pain.
Where things become really problematic is when the pain displacement involves multiple teams. This is why understanding decision impact is so key. Pain displacement doesn’t just involve engineering teams, it also involves customers and other stakeholders in the organization. This is something I see quite a bit: displacing pain away from customers onto various teams within the org by setting unrealistic expectations up front.
For example, we build a product MVP and run it on a single, high-memory instance, and we don’t actually write data out to disk to keep it fast. We then put this product in front of sales folks, marketing, or even customers and say “hey, look at this cool thing we built.” Then the customers say “wow, this is great! I don’t feel any pain at all using this!” That’s because the pain has been moved elsewhere.
This MVP isn’t fault tolerant because it’s running on a single machine. This MVP isn’t horizontally scalable because we keep all the state in memory on one instance. This MVP isn’t safe because the data isn’t durably stored to disk. The problem is we weren’t testing at scale, so we never felt any pain until it was too late. So we start working backward to address these issues after the fact. We need to run multiple instances so we can have failover. But wait, now we need stateful request routing to maintain our performance expectations. Does our infrastructure support that? We need a mechanism to split and merge units of work that plays nicely with our autoscaling system to give us a better scale story, avoid hot instances, and reduce excess capacity. But wait, how long will that take to build? We need to attach persistent disks so we can durably store data and keep things fast. But wait, does our cluster provisioning allow for that? Does that even meet our compliance requirements?
The only way you reach this point is by making local decisions without thinking about the trade-offs involved or the fact that what you’ve actually done is simply displaced the pain.
If someone doesn’t feel pain, they have a harder time developing a sense of empathy. For instance, the goal of any good operations team is to effectively put itself out of a job by empowering developers to self-service through tooling and automation. One example of this is infrastructure as code, so an ops team adds a process requiring developers to provision their own infrastructure using CloudFormation scripts. For the ops folks, this is a boon—now they no longer have to labor through countless UIs and AWS consoles to provision databases, queues, and the like for each environment. Developers, on the other hand, were never exposed to that pain, so to them, writing CloudFormation scripts is a new hoop to jump through—setting up infrastructure is ops’ job! They might feel pain now, but they don’t necessarily see the immediate payoff.
A coworker of mine recently posed an interesting question: why do product teams often overlook the need for tools required to support their product in production until after they’ve deployed to production? And while the answer he posits is good, and one I very much agree with—solving a problem and solving the problem of solving problems are two very different problems—my answer is this: pain-driven development. In this case, you’re deferring the pain by hooking up debuggers or SSHing into the box and poking about instead of relying on instrumentation which is what we’re limited to in the field. As long as you’re cognizant of this and know that at some point you will have to feel some pain, it can be okay. But if you’re just displacing pain thinking it’s actually disappearing, you’ll be in for a rude awakening. Remember, it’s a zero-sum game.
I’m looking at this through an infrastructure or operations lens, but this applies everywhere and it cuts both ways. Understanding the why behind something rather than just the how is critical to building empathy. It’s being able to look at a problem through someone else’s perspective and applying that to your own work. Changing your perspective is a powerful way to deepen your relationships. Pain-driven development is intoxicating because it allows us to move fast. It’s a greedy algorithm, but it provides a poor global approximation for large engineering organizations. Thinking holistically is important.
Follow @tyler_treat