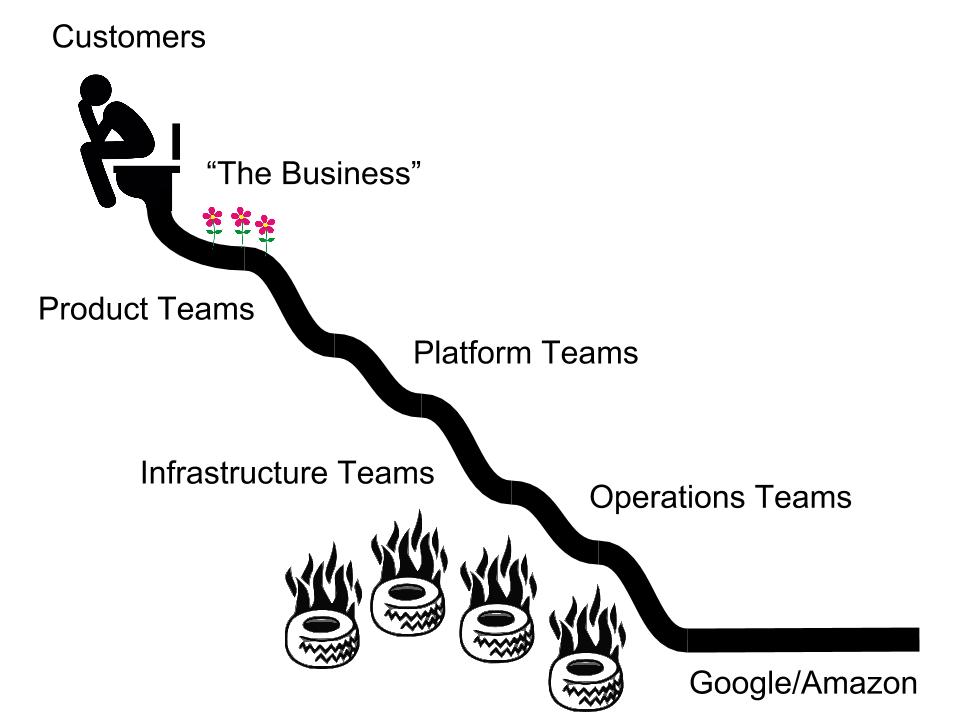
Traditional Operations isn’t going away, it’s just retooling. The move from on-premise to cloud means Ops, in the classical sense, is largely being outsourced to cloud providers. This is the buzzword-compliant NoOps movement, of which many call the “successor” to DevOps, though that word has become pretty diluted these days. What this leaves is a thin but crucial slice between Amazon and the products built by development teams, encompassing infrastructure automation, deployment automation, configuration management, log management, and monitoring and instrumentation.
The future of Operations is actually, in many ways, much like the future of QA. Traditional QA roles are shifting away from test-focused to tools-focused. Engineers write code, unit tests, and integration tests. The tests run in CI and the code moves to production through a CD pipeline and canary rollouts. QA teams are shrinking, but what’s growing are the teams building the tools—the test frameworks, the CI environments, the CD pipelines. QA capabilities are now embedded within development teams. The SDET (Software Development Engineer in Test) model, popularized by companies like Microsoft and Amazon, was the first step in this direction. In 2014, Microsoft moved to a Combined Engineering model, merging SDET and SDE (Software Development Engineer) into one role, Software Engineer, who is responsible for product code, test code, and tools code.
Did you notice that QA roles seem to quietly start going away? So many dev organizations I worked with or know seem to do fine without QA.
— Gwen (Chen) Shapira (@gwenshap) April 6, 2017
The same is quickly becoming true for Ops. In my time with Workiva’s Infrastructure and Reliability group, we combined our Operations and Infrastructure Engineering teams into a single team effectively consisting of Site Reliability Engineers. This team is responsible for building and maintaining infrastructure services, configuration management, log management, container management, monitoring, etc.
I am a big proponent of leadership through vision. A compelling vision is what enables alignment between teams, minimizes the effects of functional and organizational silos, and intrinsically motivates and mobilizes people. It enables highly aligned and loosely coupled teams. It enables decision making. My vision for the future of Operations as an organizational competency is essentially taking Combined Engineering to its logical conclusion. Just as with QA, Ops capabilities should be embedded within development teams. The fact is, you can’t be an effective software engineer in a modern organization without Ops skills. Ops teams, as they exist today, should be redefining their vision.
The future of Ops is enabling developers to self-service through tooling, automation, and processes and empowering them to deploy and operate their services with minimal Ops intervention. Every role should be working towards automating itself out of a job.
The model of ops as service providers (cluster admins) is terminal and outmoded. Devs will always out-demand their capacity to supply.
— ✕✕✕✕✕ (@peterbourgon) April 5, 2017
The correct model is ops as force multipliers: building automation to let d provision their own clusters and base infrastructure.
— ✕✕✕✕✕ (@peterbourgon) April 5, 2017
Dev: My cluster is broken!
Op: OK, this is my problem now—please wait while I fix it.
—The wrong model :(— ✕✕✕✕✕ (@peterbourgon) April 5, 2017
Dev: My cluster is broken!
Op: OK, I’m your domain expert, to help you fix it yourself; or, you can use this tooling to reprovision it.
— :)— ✕✕✕✕✕ (@peterbourgon) April 5, 2017
If you asked an old-school Ops person to draw out the entire stack, from bare metal to customer, and circle what they care about, they would draw a circle around the entire thing. Then they would complain about the shitty products dev teams are shipping for which they get paged in the middle of the night. This is broadly an outdated and broken way of thinking that leads to the self-loathing, chainsmoking Ops stereotype. It’s a cop out and a bitterness resulting from a lack of empathy. If a service is throwing out-of-memory exceptions at 2AM, does it make sense to alert the Ops folks who have no insight or power to fix the problem? Or should we alert the developers who are intimately familiar with the system? The latter seems obvious, but the key is they need to be empowered to be notified of the situation, debug it, and resolve it autonomously.
The NewOps model instead should essentially treat Ops like a product team whose product is the infrastructure. Much like the way developers provide APIs for their services, Ops provide APIs for their infrastructure in the form of tools, UIs, automation, infrastructure as code, observability and alerting, etc.
@peterbourgon I have many thoughts on this subject, the tweet version is: ops as we know it is dead, anyone doing infra has 5 years to move to product.
— Dαve Cheney (@davecheney) April 5, 2017
In many ways, DevOps was about getting developers to empathize with Ops. NewOps is the opposite. Overly martyrlike and self-righteous Ops teams simply haven’t done enough to empower and offload responsibility onto dev teams. With this new Combined Engineering approach, we force developers to apply systems thinking in a holistic fashion. It’s often said: the only way engineers will build truly reliable systems is when they are directly accountable for them—meaning they are on call, not some other operator.
With this move, the old-school, wild-west-style of Operations needs to die. Ops is commonly the gatekeeper, and they view themselves as such. Old-school Ops is building in as much process as possible, slowing down development so that when they reach production, the developers have a near-perfectly reliable system. Old-school Ops then takes responsibility for operating that system once it’s run the gauntlet and reached production through painstaking effort.
Ops lock-in: When your organization cannot innovate faster than your ops team will allow or willing to support.
— Kelsey Hightower (@kelseyhightower) April 4, 2017
Old-school Ops are often hypocrites. They advocate for rigorous SDLC and then bypass the same SDLC when it comes to maintaining infrastructure. NewOps means infrastructure is code. Config changes are code. Neither of which are exempt from the same SDLC to which developers must adhere. We codify change requests. We use immutable infrastructure and AMIs. We don’t push changes to a live environment without going through the process. Similarly, we need to encode compliance and other SDLC requirements which developers will not empathize with into tooling and process. Processes document and codify values.
Old-school Ops is constantly at odds with the Lean mentality. It’s purely interrupt-driven—putting out fires and fixing one problem after another. At the same time, it’s important to have balance. Will enabling dev teams to SSH into boxes or attach debuggers to containers in integration environments discourage them from properly instrumenting their applications? Will it promote pain displacement? It’s imperative to balance the Ops mentality with the Dev mentality.
Development teams often hold Ops responsible for being an innovation or delivery bottleneck. There needs to be empathy in both directions. It’s easy to vilify Ops but oftentimes they are just trying to keep up. You can innovate without having to adopt every bleeding-edge technology that hits Hacker News. On the other hand, modern Ops organizations need to realize they will almost never be able to meet the demand placed upon them. The sustainable approach—and the approach that instills empathy—is to break down the silos and share the responsibility. This is the future of Ops. With the move to cloud, Ops needs to reinvent itself by empowering and entrusting development teams, not trying to protect them from themselves.
Ops is dead, long live Ops!
Follow @tyler_treat