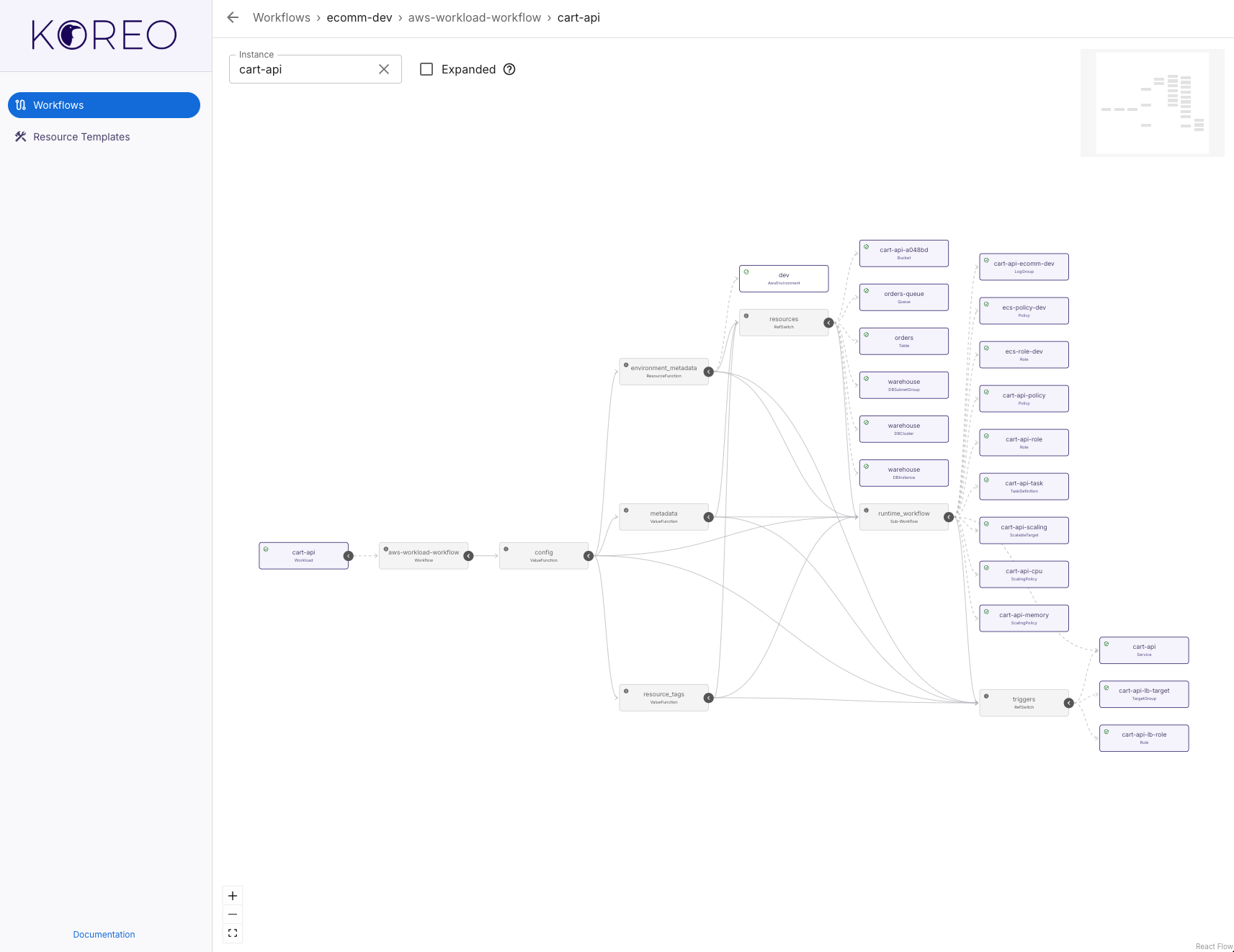
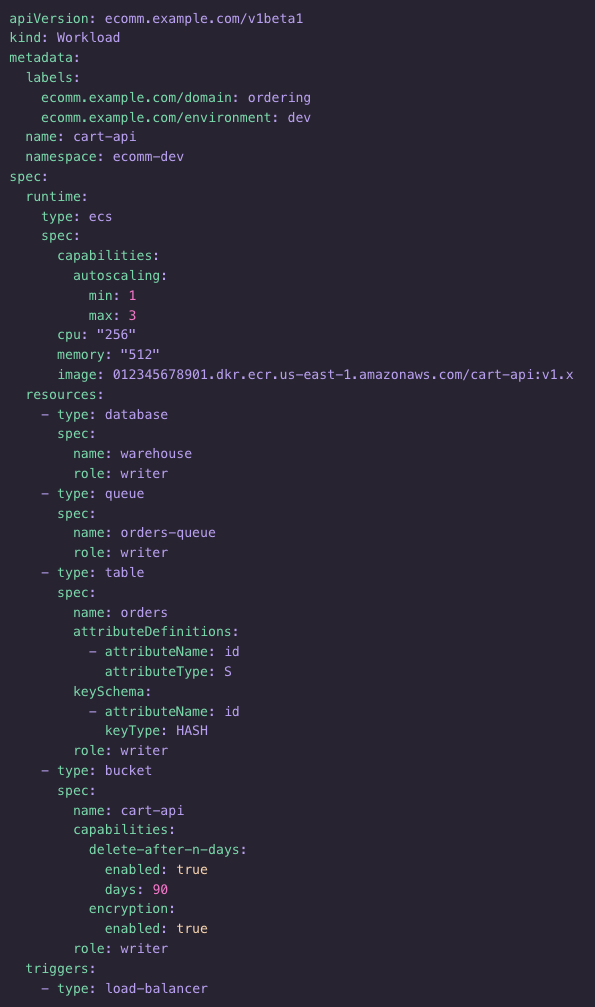
Last month we open sourced Koreo, our “platform engineering toolkit for Kubernetes.” Since then, we’ve seen a lot of interest from folks in the platform engineering and DevOps space. We’ve also gotten a lot of questions from people trying to better understand how Koreo fits into an already crowded landscape of Kubernetes tools. Koreo is a fairly complex tool, so it can be difficult to quickly grasp just what exactly it is, what problems it’s designed to solve, and how it compares to other, similar tools. In this post, I want to dive into these topics and also discuss the original motivation behind Koreo.
If you’ve read the Koreo website, you’ll know that we refer to it as “a new approach to Kubernetes configuration management and resource orchestration,” but what does this really mean? There are two parts to unpack here: configuration management and resource orchestration.
By far, the most common approach to configuration management in Kubernetes is Helm. Helm charts provide a convenient way to templatize and package up Kubernetes resources and make them configurable via values files. There are some challenges and limitations with Helm though. One is around how it works as a templating system. We talked about this in depth here so I won’t go into a ton of detail, but a challenge with Helm is when charts begin to grow beyond basic templating. Once you start to introduce logic and nested conditionals into your templates, they quickly become difficult to understand, maintain, and evolve. Helm is actually a pretty rudimentary approach because it really just treats configuration management as YAML string templating.
Kustomize can handle some of these cases better by letting you specify base resource manifests and then customize them through overlays and patches that are more structurally aware. However, this largely assumes that the configuration variations are static and don’t rely on computed values or business logic. In other words, as deployments grow in complexity, Kustomize’s reliance on static overlays can become cumbersome and limiting.
Helm and Kustomize are not resource orchestrators—they’re templating tools. If your resources have non-deterministic dependencies on each other, you’ll need to handle this sequencing yourself. For example, to create a VPC and then a Kubernetes cluster in AWS, you must first apply the VPC and then use something like Helm’s lookup function to retrieve its outputs (e.g. subnets) for use in templating the cluster. There are a lot of situations where the inputs of a resource require the outputs of a different resource. Some of these might be deterministic, perhaps like a CIDR block, but many are not. This dependency between resources is what I mean by resource orchestration. Most tools treat configuration management and resource orchestration as separate concerns: tools like Helm, Kustomize, Jsonnet, and Cue handle configuration management, while tools like Crossplane, Argo, and Kro address resource orchestration. But in practice, these responsibilities are often deeply intertwined. Especially in platform engineering, configuring resources almost always requires orchestrating them.
The Motivation Behind Koreo
Koreo was built to make platform engineers’ lives easier. We originally developed it out of a need to both configure and orchestrate cloud resources across GCP and AWS—using Config Connector and ACK—and integrate them cleanly into a broader internal developer platform. Helm wasn’t viable due to its lack of orchestration capabilities. Crossplane, while powerful, proved overly complex but also had several key limitations, namely it’s tightly coupled to Provider APIs and it offers limited support for multitenancy. Kro didn’t exist at the time, but even today it remains too rigid and inflexible for our needs. We also required a way to define standard, base configurations for resources, expose only certain configuration knobs to application teams, and give developers the ability to safely customize what they needed.
Additionally, we felt that much of the innovation in platform engineering and DevOps has thrown away a lot of the learnings and developments that have occurred in software engineering over the last several decades. In particular, many modern infrastructure and platform tools lack robust mechanisms for testing configuration and orchestration logic. Unlike application code, which benefits from well-established practices around unit testing, integration testing, and CI workflows, platform code is often fragile, opaque, and difficult to validate. There’s no easy way to test a change to a Helm chart or a Crossplane composition without applying it to the cluster and hoping for the best. This leads to brittle platforms, longer feedback cycles, and a higher risk of outages. With Koreo, we wanted to bring the rigor of software development—testable components, reproducible workflows, clear interfaces—into the platform space.
We initially built platforms using custom controllers implemented in Go and Python, which allowed us to move quickly. However, extending and iterating on the platform became increasingly difficult and time-consuming. In order to make it easier to implement new capabilities quickly, one of our developers built a lightweight framework to orchestrate workflows by mapping values between steps. Another developer sought to make our existing system more flexible with a simple approach to configuration templating. When we saw these two ideas, which were in two different code bases in two different parts of the system, we realized that they could work well together, and the idea for Koreo was born.
Koreo’s Approach
At the heart of Koreo are functions and workflows. Functions are small, reusable logic units that can either be pure and computational (we call these ValueFunctions) or side-effectful and capable of interacting with the Kubernetes API to create, modify, or read resources (ResourceFunctions). These are then composed into workflows, which define a graph of steps, conditions, and dependencies—kind of like a programmable controller but defined entirely in YAML.
We chose YAML deliberately because it doesn’t abstract what is actually being configured: Kubernetes resource manifests. We’ve found keeping the tool “true” to the underlying thing it manages reduces mental overhead for developers and makes it easier to reason about what is happening. This choice also brings some practical benefits. It’s easy to take an existing Kubernetes resource definition and use it as the basis for a ResourceFunction or ResourceTemplate. It also allows us to very cleanly test materialized resources. With FunctionTests, we can ensure resources are configured as expected based on inputs to the function. And by using ResourceTemplates, we can define standard base configurations and then overlay dynamic values on top. This approach to resource materialization allows us to decompose configuration into small, reusable components that can be tested both in isolation and as part of a larger workflow.
Koreo provides a unified approach to configuration management and resource orchestration. Workflows allow us to connect resources together by mapping the outputs of a resource to the inputs of another resource. For instance, let’s say you want to provision a GKE cluster, configure network policies, and deploy an application—all based on some higher-level spec like a tenant definition. With Koreo, you can define a workflow that reads the spec, provisions the GKE cluster, waits for it to be ready, extracts its outputs (e.g. endpoint, credentials), and passes them downstream to subsequent steps. Each step is explicit, composable, and testable.
In effect, Koreo lets you seamlessly integrate Kubernetes controllers and off-the-shelf operators like Config Connector and ACK into a cohesive platform. With this, you can build your own platform controllers without actually needing to implement a custom operator. Any resource in Kubernetes can be connected, and we can use Koreo’s control-flow primitives to implement workflows that are as simple as provisioning a few resources or as complex as automating an entire internal developer platform.
Why Koreo Matters
What makes Koreo different is that it treats platform engineering not as an afterthought to infrastructure management or application deployment, but as a discipline in its own right—one that deserves the same principles of clarity, testability, and modularity that we apply to software engineering. It’s not just about making YAML more bearable or chaining together a few CLI commands. It’s about enabling platform teams to build robust, composable, and predictable automation that supports developers without hiding important details or creating layers of abstraction that become liabilities over time.
Koreo lets you define your platform architecture as code, test it like code, and evolve it like code. It’s declarative, but programmable. It’s simple to start with, but powerful enough to scale across teams, environments, and cloud providers. It gives you a model for thinking about how platform components fit together and the control to manage that complexity as your needs grow.
What’s Next
Since open sourcing Koreo, we’ve been actively working on improving documentation, adding more examples, and expanding support for new use cases. We’re especially excited about adding support for managing resources in other Kubernetes clusters. This enables running Koreo as a centralized control plane in addition to a federated model. We’re also investing in better tooling around developer experience, like improved type checking, workflow debugging, and enhanced UI capabilities to visualize workflow executions.
If you’re a platform engineer, SRE, or DevOps practitioner struggling to manage the growing complexity of Kubernetes-based platforms, we’d love for you to give Koreo a shot. We’re just getting started, and we’d love your feedback.
Harnessing the Kubernetes Resource Model for modern infrastructure management
Infrastructure as Code (IaC) revolutionized how we manage infrastructure, enabling developers to define resources declaratively and automate their deployment. However, tools like Terraform and CloudFormation, despite their declarative configuration, rely on an operation-centric model, where resources are created or updated through one-shot commands.
The evolution of IaC: From operations to controllers
In contrast, Kubernetes introduced a new paradigm with its controller pattern and the Kubernetes Resource Model (KRM). This resource-centric approach to APIs redefines infrastructure management by focusing on desired state rather than discrete operations. Kubernetes controllers continuously monitor resources, ensuring they conform to their declarative configurations by performing actions to move the actual state closer to the desired state, much like a human operator would. This is known as a control loop.
Kubernetes also demonstrated the value of providing architectural building blocks that encapsulate standard patterns, such as a Deployment. These can then be composed and combined to provide impressive capabilities with little effort—HorizontalPodAutoscaler is an example of this. Through extensibility, Kubernetes allows developers to define new resource types and controllers, making it a natural fit for managing not just application workloads but infrastructure of any kind. This enables you to actually provide a clean API for common architectural needs that encapsulates a lot of routine business logic. Extending this model to IaC is something we call Controller-Driven IaC.
Building on the Kubernetes controller model
Controller-Driven IaC builds upon the Kubernetes foundation, leveraging its controllers to reconcile cloud resources and maintain continuous alignment between desired and actual states. By extending Kubernetes’ principles of declarative configuration and control loops to IaC, this approach offers a resilient and scalable way to manage modern infrastructure. Integrating cloud and external system APIs into Kubernetes controllers enables continuous state reconciliation beyond Kubernetes itself, ensuring consistency, eliminating configuration drift, and reducing operational complexity. It results in an IaC solution that is capable of working correctly with modern, dynamic infrastructure. Additionally, it brings many of the other benefits of Kubernetes—such as RBAC, policy enforcement, and observability—to infrastructure and systems outside the cluster, creating a unified and flexible management framework. In essence, Kubernetes becomes the control plane for your entire developer platform. That means you can offer developers a self-service experience within defined bounds, and this can further be scoped to specific application domains.
This concept isn’t entirely new. Kubernetes introduced Custom Resource Definitions (CRDs) in 2017, enabling the creation of Operators, or custom controllers, to extend its functionality. Today, countless Operators exist to manage diverse applications and infrastructure, both within and outside of Kubernetes, including those from major cloud providers. For instance, GCP’s Config Connector, AWS’s ACK, and Azure’s ASO offer controllers for managing their respective platform’s infrastructure. However, just as operationalizing Kubernetes requires tooling and investment to build an effective platform, so too does implementing Controller-Driven IaC. Integrating these various controllers into a cohesive platform requires its own kind of orchestration. We need a way to program control loops—whether built-in Kubernetes controllers (like Deployments or Jobs), off-the-shelf controllers (like ACK or Config Connector), or custom controllers we’ve built ourselves.
Introducing Koreo: Programming control loops for modern platforms
There are tools such as Crossplane that take a controller-oriented approach to infrastructure, but they have their own challenges and limitations. In particular, we really need the ability to compose arbitrary Kubernetes resources and controllers, not just specific provider APIs. What if we could treat anything in Kubernetes as a referenceable object capable of acting as the input or output to an automated workflow, and without the need for building tons of CRDs or custom Operators? Additionally, it’s critical that resources can be namespaced rather than cluster-scoped to support multi-tenant environments and that the corresponding infrastructure can live in cloud projects or accounts separate from where the control plane itself lives.
To address these needs and deliver the full potential of Controller-Driven IaC, we’ve developed and open-sourced Koreo, a platform engineering toolkit for Kubernetes. Koreo is a new approach to Kubernetes configuration management and resource orchestration empowering developers through programmable workflows and structured data. It enables seamless integration and automation around the Kubernetes Resource Model, supporting a wide range of use cases centered on Controller-Driven IaC. Koreo serves as a meta-controller programming language and runtime that allows you to compose control loops into powerful abstractions.
The Koreo UI showing a workflow for a custom AWS workload abstraction
Koreo is specifically built to empower platform engineering teams and DevOps engineers by allowing them to provide Architecture-as-Code building blocks to the teams they support. With Koreo, you can easily leverage existing Kubernetes Operators or create your own specialized Operators, then expose them through powerful, high-level abstractions aligned with your organization’s needs. For example, you can develop a “StatelessCrudApp” that allows development teams to enable company-standard databases and caches with minimal effort. Similarly, you can build flexible automations that combine and orchestrate various Kubernetes primitives.
An instance of the custom AWS workload abstraction
Where Koreo really shines, however, is making it fast and safe to add new capabilities to your internal developer platform. Existing configuration management tools like Helm and Kustomize, while useful for simpler configurations, become unwieldy when dealing with the intricacies of modern Kubernetes deployments. They ultimately treat configuration as static data, and this becomes problematic as configuration evolves in complexity.
Koreo instead embraces configuration as code by providing a programming language and runtime with robust developer tooling. This allows platform engineers to define and manage Kubernetes configurations and resource orchestration in a way that is better suited to modern infrastructure challenges. It offers a solution that scales with complexity. A built-in testing framework makes it easy to quickly validate configuration and iterate on infrastructure, and IDE integration gives developers a familiar programming-like experience.
The future of infrastructure management is controller-driven
By harnessing the power of Kubernetes controllers for Infrastructure as Code, Koreo bridges the gap between declarative configuration and dynamic infrastructure management. It moves beyond the limitations of traditional IaC, offering a truly Kubernetes-native approach that brings the benefits of control loops, composability, and continuous reconciliation to your entire platform. With Koreo, you’re not just managing resources; you’re composing Kubernetes controllers to do powerful things like building internal developer platforms, managing multi-cloud infrastructure, or orchestrating application deployments and other complex workflows.
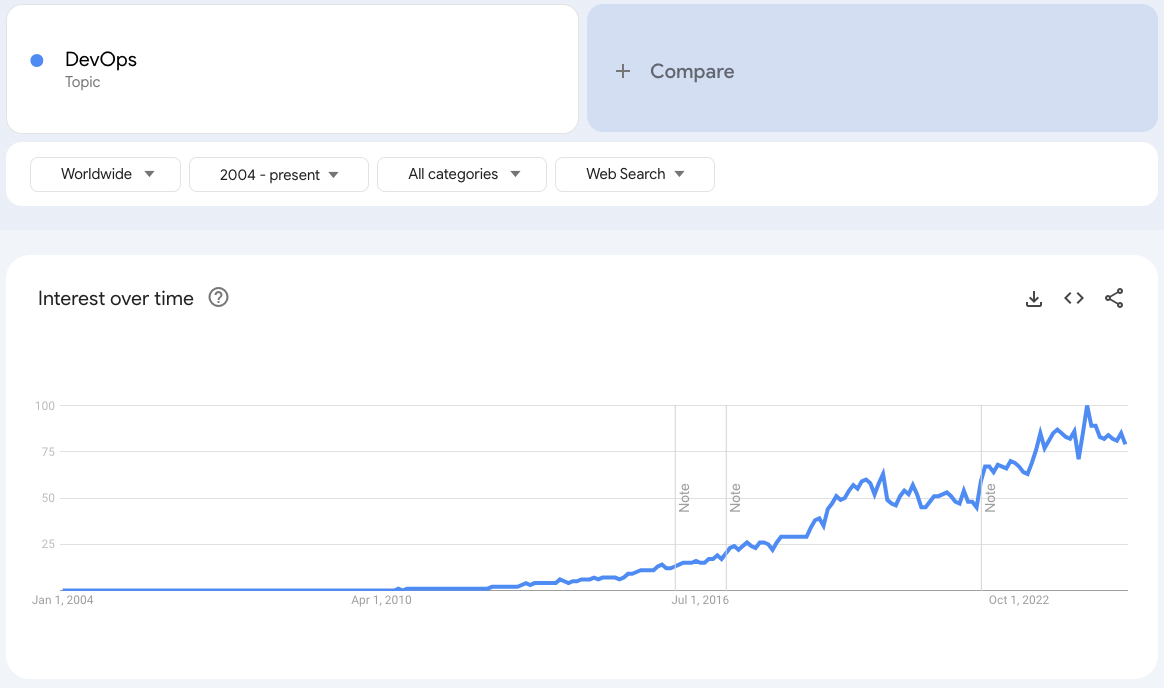
Like most industry jargon, “DevOps” means a lot of things to a lot of different people. While many folks view it as specific to certain tooling or practices, such as CI/CD or Infrastructure as Code (IaC), I’ve always viewed it as an organizational model for how software is built and delivered. In particular, my interpretation is that DevOps is about shifting more responsibilities “left” onto developers, moving away from the more traditional “throw it over the wall” approach to IT operations. No doubt this encompasses tooling or practices like CI/CD and IaC, which are responsibilities that developers now shoulder, perhaps with the support of dev tools, productivity, or enablement teams—some companies just call this the “DevOps” team.
While many organizations still operate with the traditional silos, DevOps has established itself as an industry norm. But as organizations push the boundaries of software development, the limitations of DevOps are becoming increasingly apparent. The problem is that DevOps, in its pursuit of speed and autonomy, often results in chaos and inefficiency. Teams end up reinventing the wheel, creating bespoke solutions for the same problems, and struggling with inconsistent tooling and practices across the organization. The outcome? Technical debt, fragmented processes, and wasted effort. Many of the teams we work with at Real Kinetic spend significantly more time on the “DevOps work” than they do on actual product work.
Google Trends for “DevOps”
The Rise of Platform Engineering
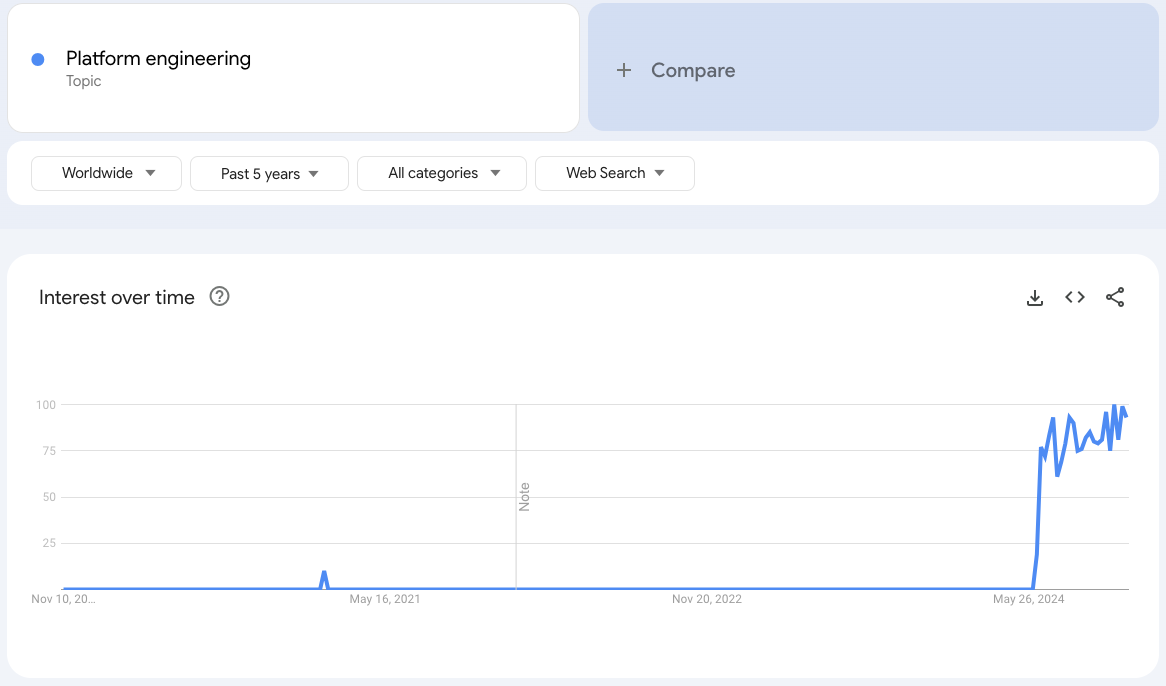
This is where Platform Engineering comes in. Rather than having each development team own their entire infrastructure stack, platform engineering provides a centralized, productized approach to infrastructure and developer tools. It’s about creating reusable, self-service platforms that development teams can leverage to build, deploy, and scale their applications efficiently. These platforms abstract away the complexities of cloud infrastructure, CI/CD pipelines, and security, enabling developers to focus on writing code rather than managing infrastructure or “glue”.
Platform engineering brings structure to the chaos of DevOps by creating a standardized, cohesive platform that empowers development teams while maintaining best practices and governance. It’s a solution to the growing complexity and sprawl that comes with scaling software delivery and scaling DevOps. Platform engineering is very much in its infancy as DevOps was circa 2012, but there’s growing interest in it as organizations hit the ceiling of DevOps.
Google Trends for “Platform Engineering”
But There’s a Catch: The Investment Barrier
Implementing platform engineering isn’t without its challenges. Building a robust, scalable platform requires significant time, resources, and expertise. It demands a deep understanding of your organization’s technology stack, development workflows, and business objectives. And importantly, it diverts valuable resources away from core product development efforts.
Many organizations are hesitant to make this level of investment, especially if it’s not their core competency. They either end up doing it poorly—leading to a half-baked platform that doesn’t deliver the promised efficiencies—or they avoid it altogether, sticking to the DevOps status quo. This often leaves them with the worst of both worlds: the overhead of DevOps without the benefits of a streamlined, developer-friendly platform.
What we most often see are dev tools teams masquerading as platform engineering.As Camille Fournier puts it, they build scripts or tools around configuration management and infrastructure provisioning, not products. Usually it’s because they either don’t want to have skin in the game or they don’t have a mandate from leadership. “Not having skin in the game” means some combination of these things: a) they don’t want to build their own software, b) they don’t want to be on the hook for operations, or c) they don’t want to be in the critical path for production or become a bottleneck. Instead, they provide “blueprints” for these things and the burden and responsibility ultimately falls on the product teams—this is just DevOps.
Another issue is that organizations don’t want to allocate the headcount to do real platform engineering. They’re not wrong to be hesitant because it takes real investment to actually do it. As a result, however, they take half measures. We frequently see companies take an InnerSource approach as an attempt to basically socialize platform engineering. I have never seen this approach work well in practice unless there’s clear ownership and the team has a clear mandate. And just as before, this approach pushes scripts, not products. Without ownership and directive, it just reverts back to DevOps which leads to inefficiency and sprawl.
The Solution: Platform Engineering as a Service
This is where Platform Engineering as a Service (PEaaS) comes in. Unlike traditional Platform as a Service (PaaS) offerings, which provide a rigid, one-size-fits-all platform that abstracts away the underlying infrastructure, PEaaS is designed to be flexible and tailored to your unique requirements. It doesn’t hide the infrastructure but rather empowers your teams by providing the tools, automation, and best practices needed to build and operate cloud-native applications efficiently for your organization.
Instead of building and maintaining a custom platform internally, organizations can partner with experts who specialize in platform engineering and bring deep, hands-on experience to the table. With PEaaS, you get all the benefits of a mature, scalable platform without the heavy upfront investment or the distraction from your core product development. This means that a robust, enterprise-grade platform can be implemented in a fraction of the time, and managed for a fraction of the cost. What typically takes companies 6 months or more to build can be accomplished in days or weeks. And, what typically takes a team of 5 – 10 engineers working full-time to manage can be handled by 1 engineer, often on a part-time basis.
At Real Kinetic, we’ve been helping organizations accelerate their software delivery for years. In fact, we’ve been doing platform engineering long before it was called platform engineering. We bring our extensive expertise in cloud infrastructure, CI/CD, and developer enablement to build platforms that align with your organization’s unique needs and technology stack. By leveraging our Platform Engineering as a Service, you can stay focused on what you do best—building great products—while we take care of the complexities of infrastructure, automation, and developer tooling.
Why Real Kinetic?
Why should you trust us with your platform engineering needs? Because we’ve done it before, time and time again. Real Kinetic has helped numerous organizations—from startups to large enterprises—modernize their software delivery practices, improve developer productivity, and accelerate time to market. Our approach is rooted in real-world experience, not theory. We understand the challenges of scaling platforms because we’ve been there ourselves.
When you partner with Real Kinetic, you’re not just getting a service provider—you’re getting a team of experts who are invested in your success and have skin in the game. We’re here to build a platform that scales with your business, optimizes your development workflows, and ultimately drives more value for your customers.
Ready to Level Up Your Software Delivery?
If you’re tired of the inefficiencies of DevOps and ready to embrace the power of platform engineering, let’s talk. Real Kinetic’s Platform Engineering as a Service is your fast track to a scalable, efficient platform that empowers your developers and accelerates your time to market. And if you’re using AWS or GCP, we’re also looking for a few companies to pilot our batteries-included platform engineering product Konfigurate.
Most people use “DDD” to refer to Domain-Driven Design, which is a useful tool for thinking about API boundaries and system architecture. It provides a way to map a business problem into software. At Real Kinetic, we regularly help our clients utilize Domain-Driven Design as well as other strategies to architect their systems, avoid some of the pitfalls of DDD, and build an effective foundation for designing software. But this DDD only speaks to one small aspect of building and shipping software.
Software architecture is critical to a number of concerns like scalability, adaptability, and speed-to-market for new products and features, but its effects are usually not felt for some time—weeks, months, even years later. These delayed effects are lagging indicators that reveal how “well” a system was architected (I use quotes here because this is really quite subjective and relative to both the short- and long-term needs of the business). Other lagging indicators also highlight problems in software development. For instance, a high number of reported bugs may point to deficiencies in QA and testing processes, while the volume or severity of findings in an audit may signal issues in security, compliance, or SDLC practices. Similarly, accumulated tech debt may reflect deeper systemic issues.
These lagging indicators often result from a delayed and reactive approach to managing concerns like security, compliance, quality, and even architecture. These concerns are frequently deferred to later stages in the development process or left to evolve on their own organically. It’s not uncommon for us to see teams complete the development of a product or feature, only to spend months navigating the hurdles to get it into production. It may be testing or production-readiness processes, integration challenges, infrastructure issues, change-review boards, or a combination of all of these. One way or another, it takes many teams inordinately long to go from idea to in-customer’s-hands.
Through our work consulting with startups, scaleups, and Fortune 500 companies to improve their product delivery, we’ve been building a solution to this problem called Konfigurate. But before diving into that, I want to introduce you to the other DDD—Deployment-Driven Development—and why it’s critical to improving delivery, how it relates to platform engineering, and how it can be implemented.
Shift Left
The act of scaling a product—that is to say, going from prototype to production and beyond—takes focus off the product itself. This is because there is a whole host of undifferentiated work that is needed at various stages of a product’s lifecycle:
Infrastructure configuration and management
CI/CD tooling
Workforce and workload IAM
System security
Compliance
Sprawl and tech debt management
“Shifting left” has become a mantra for high-performing teams, particularly as it relates to software testing. The reality, though, is that much of this undifferentiated work—security, compliance, infrastructure, deployment—is still often treated as a separate concern to be tackled just before the system goes live or, in some cases, after it’s already been deployed to production. Security is a good example of this, where tools like Wiz scan for security issues in the runtime environment or during CI/CD—after the code has been written. Nothing against continuous security, but wouldn’t it be nice if systems could be built the “right” way up front to reduce rework or delays?
Deployment-Driven Development—a different kind of DDD—challenges this approach by flipping the paradigm. Instead of treating deployment as a final milestone, it prioritizes deployment from the start. The idea is simple but powerful: start with a deployment to a real, production-like environment on day one then work your way backwards. Doing this shifts more of these concerns left into the development process.
What is Deployment-Driven Development?
Deployment-Driven Development begins with a live, deployable environment and treats it as the foundation for all development activities that follow. The very first step when a new workload is created, before anything else happens, is deploying it to a real environment. From that point on, every line of code, every change, and every new feature is created and tested in an environment that mirrors production. This approach ensures that from day one, teams are building, testing, and iterating in conditions that match the realities of their live system, giving them the confidence that their application is production-ready at any given moment. As a result, teams avoid the common bottleneck of scrambling to get the application ready for production after development is complete—what I call “running the production gauntlet.”
While early-stage deployment to production-like environments is often considered best practice in modern software development, DDD formalizes this approach by reversing the typical order: start with deployment, then integrate code and configuration into that live setup. Setting up a real environment can be a significant lift for many teams, as provisioning and configuring production-like environments with the right infrastructure and permissions remains a complex task. By making deployment as simple and foundational as possible, Deployment-Driven Development makes it easier for teams to deliver faster with fewer roadblocks.
Shifting left traditionally applies to moving testing earlier in the development lifecycle, but DDD takes this idea further by shifting the deployment process itself to the beginning. Instead of validating code in isolation, the code is deployed in a full, production-ready environment, using automated provisioning to manage resources and integrate infrastructure. By proactively addressing deployment hurdles early, DDD helps reduce surprises and delays later on.
Why Legacy Infrastructure as Code Falls Short
Legacy Infrastructure as Code (IaC) like Terraform or CloudFormation doesn’t enable Deployment-Driven Development because these tools lack opinionation—clear, enforced standards for how infrastructure should be built and configured. They are general-purpose tools designed to solve all problems, much like a general-purpose programming language. For example, “least-privileged access” is widely accepted as a best practice, yet IaC tools don’t inherently enforce this principle. Developers must implement least-privileged access and other standards themselves. These IaC primitives just wrap the cloud provider’s API. The result is that legacy IaC tools don’t facilitate Deployment-Driven Development without a sizable investment into platform engineering.
There are abstractions that can help with this, whether it’s writing Terraform modules or using CDK to abstract CloudFormation and implement reusable constructs, but this goes back to what I said earlier about undifferentiated work: the act of “scaling” a product takes focus off the product itself. Consequently, we often see teams—especially those following a DevOps model—spending a disproportionate amount of time writing IaC versus writing product code.
With Deployment-Driven Development, however, opinionated infrastructure must be baked in from the beginning, automating setup in a way that enforces best practices, such as least-privileged access, as default behavior rather than optional guidance. To make this work with traditional IaC tools, it requires investing in a true platform engineering team to solve these problems for the rest of the organization. I rarely see teams approaching this from the DevOps angle doing this well at scale—it usually results in a great deal of inefficiency and sprawl. People copy/paste and bad patterns quickly proliferate.
Platform Engineering and Golden Paths
Shipping software the right way should be the easy way. At Real Kinetic, our Platform Engineering as a Service empowers organizations to adopt Deployment-Driven Development by creating golden paths for streamlined development. A golden path is an opinionated and supported way of building something within your organization. What it allows us to do is shift more things left into the development process. Rather than relying on policy and security scanners like Checkov or Wiz to detect issues reactively, we make it possible to only ship software that conforms to your organization’s internal controls or standards. While security scanners still play a role, this model significantly reduces the undifferentiated work and removes the guesswork from figuring out your organization’s standards. It lets product teams focus on the stuff that actually matters. Konfigurate, our modern IaC solution, allows organizations to enforce their standards easily—without requiring a substantial platform engineering investment.
Konfigurate was designed and built around the notion of Deployment-Driven Development. The platform’s opinionated IaC approach represents a modern solution to deployment and infrastructure management. By shifting infrastructure, compliance, and security concerns left, Konfigurate ensures that applications are production-ready from day one, enabling faster deployments and reducing time spent on “overhead” work so you can focus more on your actual product. It minimizes this work that otherwise gets deferred or left to evolve organically until it becomes a much bigger problem. This shift-left approach to IaC not only accelerates time-to-production but also provides peace of mind, knowing that infrastructure is secure, compliant, and standardized by design.
Platform engineering offers a scalable approach to DevOps by enabling organizations to codify best practices while providing the tooling and services that empower product teams to work more efficiently. However, this approach requires a dedicated investment in a platform engineering team. For startups and scaleups, this can be particularly challenging as their focus is often on rapid product development rather than internal infrastructure. Even large enterprises, especially those outside the tech industry, face hurdles in adopting platform engineering. IT departments in these organizations are frequently seen as cost centers, making it difficult to justify strategic investments like building a dedicated platform engineering function.
Conclusion
Deployment-Driven Development represents a subtle, yet fundamental, shift in how teams approach software delivery, prioritizing deployment from day one rather than treating it as an afterthought. By starting with a real, production-like environment, teams can build, test, and iterate more effectively, reducing the friction often caused by traditional infrastructure and deployment practices. This shift-left approach ensures that security, compliance, and operational concerns are addressed early, leading to faster, more reliable releases.
At Real Kinetic, we’ve embraced this methodology to help our clients streamline their delivery processes. Tools like Konfigurate embody this philosophy by providing opinionated, ready-to-use infrastructure that automates best practices, eliminating much of the undifferentiated work that slows teams down. By adopting Deployment-Driven Development, organizations can not only accelerate their time-to-market but also reduce tech debt, improve security posture, and focus more on delivering value to their customers.
Ultimately, Deployment-Driven Development is about making deployment the easy and natural part of the development lifecycle, allowing teams to deliver high-quality software with greater agility and confidence. Whether you’re a startup looking to scale quickly or an enterprise aiming to optimize your delivery pipeline, embracing this approach can be a game changer for your organization.
In my last post, I talked about the benefits of an opinionated platform. An opinionated platform allows your engineers to focus on things that matter to your business, such as shipping and improving customer-facing products and services. This is in contrast to engineers spending substantial time on non-differentiating work like platform infrastructure. Rather than infrastructure architecture, developers can focus more on the product architecture. Konfig is an opinionated platform which provides two key value drivers: 1) reducing the investment and total cost of ownership needed to have an enterprise cloud platform and 2) minimizing the time to deliver new software products.
Konfig provides an out-of-the-box, enterprise-grade platform which is built with security and governance at its heart. Building this type of platform normally requires a sizable team of platform engineers which takes constant care, maintenance, and ongoing investment. With Konfig, we can now reallocate these resources to higher-value work, and we only need a small team to manage resource templates used by developers and implement business-specific components. It enables this small team to provide a robust platform within their company with organizational standards and opinions built in. This, in turn, allows an organization’s developers to self-service with a high degree of autonomy while ensuring they work within the bounds of our organization’s standards.
For many organizations, bringing a new software product to market can be a monumental undertaking. Even when the code is written, it can take some companies six months to a year just to get the system to production. Konfig reduces this sunk cost by accelerating the time-to-production. This is possible because it provides an opinionated platform that solves many of the common problems involved with building software in a way that codifies industry best practices. Konfig’s approach encourages deploying to production-like environments from day-1, something we call Deployment-Driven Development.
So what are Konfig’s opinions? What is the motivation behind each of them? And does an opinionated platform mean an organization is constrained or locked in as is often the case with a PaaS? Let’s explore each of these questions.
Opinions and their benefits
GitLab and GCP
Perhaps the most obvious of Konfig’s opinions is that it is centered around Google Cloud Platform and GitLab. While we are actively exploring support for GitHub and AWS, we chose to start with building a white-glove experience around GCP and GitLab for a few reasons.
First, GCP has best-in-class serverless offerings and managed services which lend themselves well to Konfig’s model. This is something we’ve written about extensively before. Services like Cloud Run, Google Kubernetes Engine (GKE), BigQuery, Firestore, and Dataflow are truly differentiators for Google Cloud.
Second, GCP’s Config Connector operator provides, we argue, a better alternative to Terraform for managing infrastructure. We’ll discuss this in more detail later.
Third, we believe GitLab’s CI/CD system is better designed than GitHub Actions. This is something worthy of its own blog post, but it’s a key factor in providing a platform that is both secure and has a great developer experience.
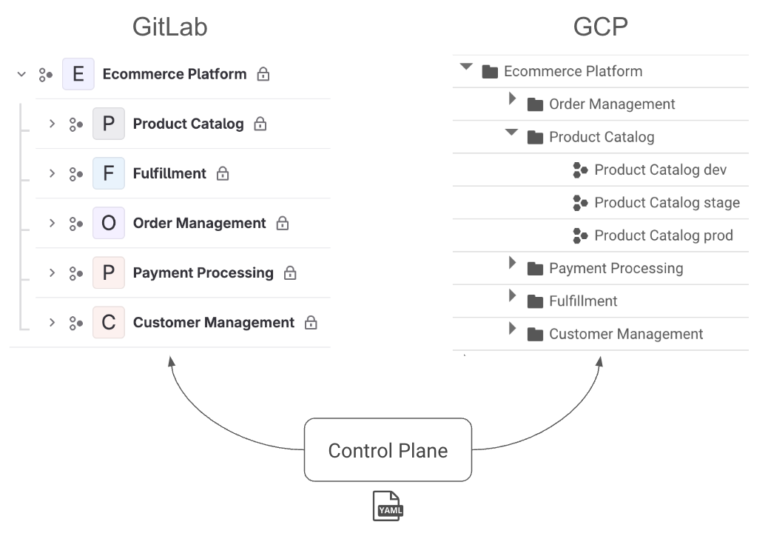
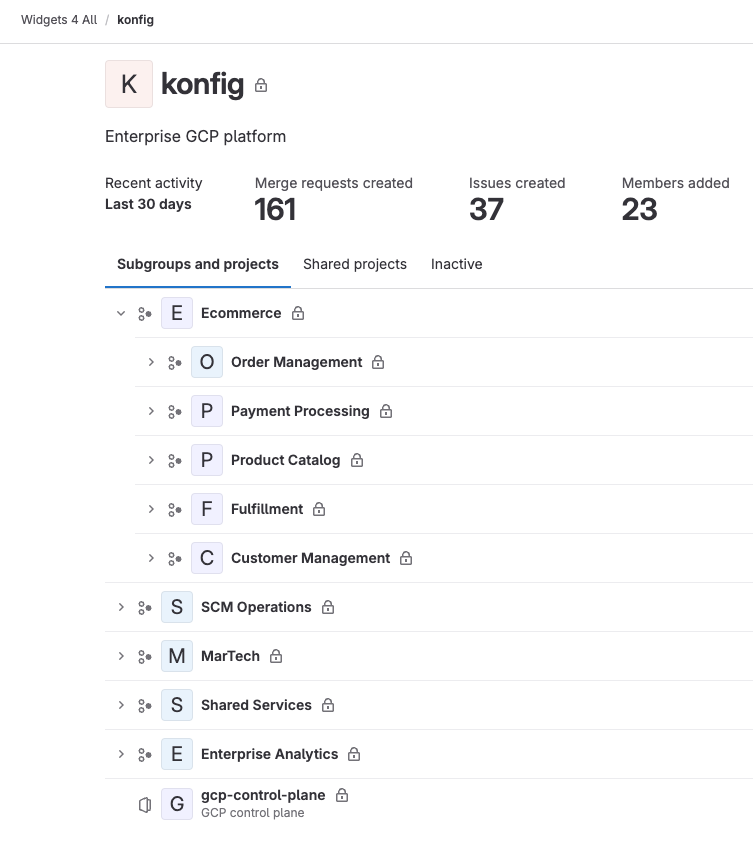
Lastly, GitLab uses a hierarchical structure with groups, subgroups, and projects which maps perfectly to Konfig’s own control plane, platform, domain hierarchy as well as GCP’s resource hierarchy with organizations, folders, and projects. This is a critical component in how Konfig manages governance.
The Konfig model works with any combination of cloud platform and DevOps tooling. We just chose to start with GCP and GitLab because they work so well together. With Konfig, they almost feel as if they are natively integrated.
Service-oriented architecture and domain-driven design
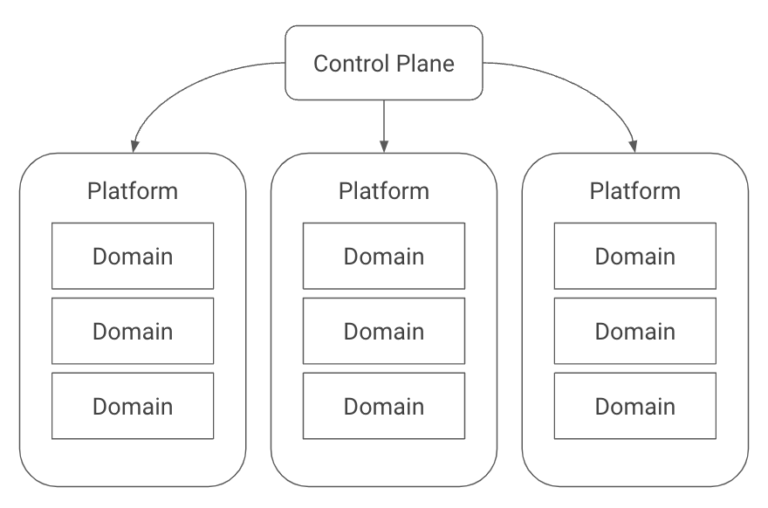
Konfig has a notion of platforms and domains. A platform is intended to map to a coarse-grained organizational boundary such as a product line or business unit. Platforms are further subdivided into domains, which are groupings of related services. This is loosely borrowed from the concept of domain-driven design. While Konfig does not take a particularly strong stance on DDD or how you structure workloads, it does encourage the use of APIs to connect services versus sharing databases between them.
This is a best practice that Konfig embraces because it reduces coupling which makes it easier to evolve services independently. A key aspect of this grouping will make certain tasks harder (though not necessarily impossible), on purpose, such as sharing a database between domains. It also promotes more durable teams who own different parts of a system, which is an organizational best practice we routinely encourage with our clients.
Structuring GitLab and GCP
Konfig maintains a consistent structure between GitLab and GCP based around the control plane, platform, domain hierarchy. Control planes, platforms, and domains are all declaratively defined in YAML. This hierarchy is central to Konfig because it allows it to enforce best practices for access management and cloud governance. It also provides powerful cost visibility because we can easily see the cloud spend and forecasted spend for platforms and domains. This means there is a rigid opinionation to the tiered structuring of folders and projects in GCP and subgroups and projects in GitLab.
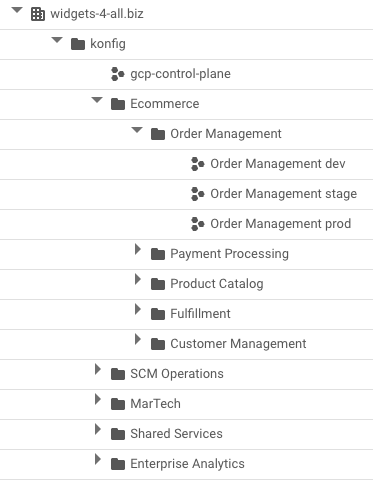
In GCP, a control plane maps to a folder within your GCP organization (either specified by the user during setup or created by the Konfig CLI). Within this folder, there is a control plane project which houses the control plane Kubernetes cluster and a folder for each platform. Within each platform folder, there are folders for each domain which contain a project for each environment (e.g. dev, stage, and prod).
Konfig hierarchy in GCP for a retail business
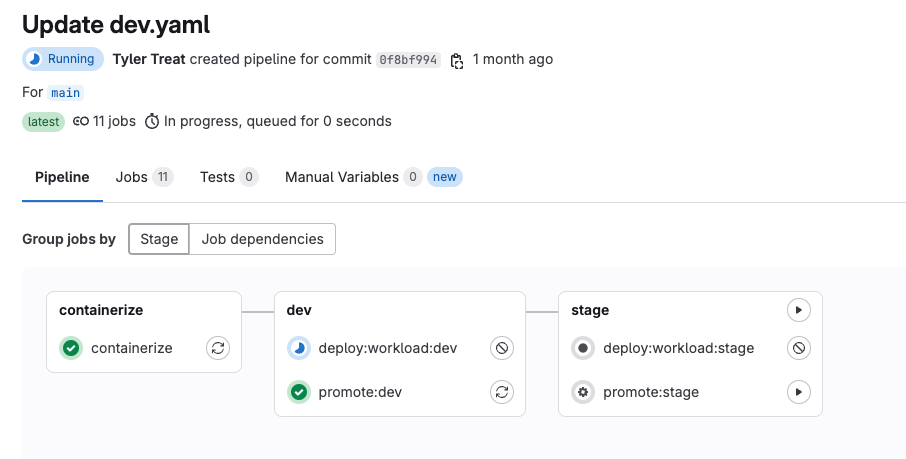
In GitLab, a control plane maps to a subgroup within your organization’s top-level group (again, either specified by the user during setup or created by the CLI). Within this subgroup, there is a control plane project which houses the definitions for the control plane itself as well as the platforms and domains it manages. In addition to the control plane project, the control plane subgroup contains a child subgroup for each platform. Like the GCP structure, these platform subgroups in turn contain subgroups for each of the platform’s domains. It’s in these domain subgroups that our actual workload projects go. Konfig provides a GitLab template for creating new workload projects that includes a fully functional CI/CD pipeline and workload definition for configuring service settings and infrastructure resources.
Corresponding Konfig hierarchy in GitLab
This structure is critical because it allows Konfig to manage access and permissioning for both users as well as service accounts. This enables the platform to enforce strong isolation and security boundaries. The hierarchy also allows us to cascade permissions and governance cleanly.
Group-based access management
Konfig leverages groups to manage permissioning. Groups are managed using a customer’s identity provider, such as Google Cloud Identity or Microsoft Entra ID (formerly Azure AD). These groups are then synced into GitLab using SAML group links and into GCP with Cloud Identity (if using an external IdP). In the control plane, platform, and domain YAML definitions, we can specify what GitLab and GCP permissions a group should have from a single configuration source.
This opinionated model provides a single source of truth for both identity (by relying on a customer’s existing IdP) and access management (via Konfig’s YAML definitions). We’ve often seen organizations assign roles to individual users which is an anti-pattern, so Konfig relies on groups as a best practice. This model also lets us apply SDLC practices to access management.
One of the benefits of Konfig is that it automatically manages IAM for workloads. This means you just specify what resources your application needs, such as databases, storage buckets, or caches, and it not only provisions those resources but also configures the application’s service account to have the minimal set of permissions needed to access them for the role specified.
In Konfig, every workload gets a dedicated service account. This is a best practice that ensures we don’t have overly broad access defined for services. Often what happens otherwise is service accounts get reused across applications, resulting in workload identities that accrue more and more roles. Another common anti-pattern is using the Compute Engine default service account which many GCP services use if a service account is not specified. This service account usually has the Editor role, which is a privileged role that grants broad access. Konfig disables this default service account altogether, preventing this from happening.
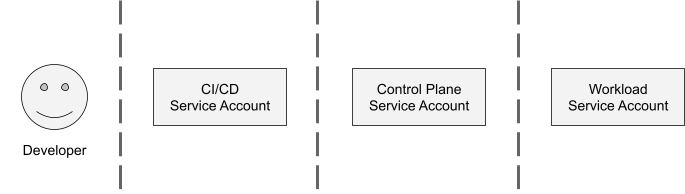
Decoupling IAM for developers, CI/CD, control planes, and workloads
There are four main groups of identities in Konfig: users, CI/CD pipelines, control planes, and workloads. Konfig takes the position that human users should generally not require elevated permissions. Similarly, all modifications to environments should occur via CI/CD pipelines rather than manually or through “ClickOps.” For this reason, Konfig enforces strong separation of developer user accounts, CI/CD service accounts, control plane service accounts, and workload service accounts.
Earlier we saw how Konfig relies on group-based access management rather than assigning roles to individual users. This provides a more uniform approach to access management. These roles provide a limited set of permissions. Instead, developers interact with Konfig through GitLab pipelines. Note, however, that the “owner” group permission, which is illustrated in the example domain.yaml above, provides break-glass access that can be set at the domain, platform, and control plane level to support situations that require emergency remediation.
Konfig maps GCP service accounts to CI/CD pipelines in GitLab using Workload Identity Federation. The service accounts used by the CI/CD system have limited permissions that are scoped by GCP IAM and Kubernetes RBAC. This means that a pipeline for a specific workload in a domain can only apply modifications to its own control plane namespace. This greatly reduces the blast radius of a compromised GitLab credential and also prevents teams from modifying environments that they don’t own.
Additionally, because Konfig relies on Workload Identity Federation, there are no long-lived credentials to begin with. Workload Identity Federation uses OpenID Connect to allow a GitLab pipeline to authenticate with GCP and use a short-lived token to act as a GCP service account. This is in contrast to using service account keys for authenticating between GitLab and GCP, which is a security anti-pattern because it involves long-lived credentials that often do not get rotated. These keys are a common source of security breaches. And because the Konfig control plane is responsible for orchestrating resources, this CI/CD service account needs a very minimal set of permissions. Basically, it just needs permissions to apply Konfig definitions to its control plane namespace. The control plane handles the actual heavy lifting from that point on.
Each domain-environment pair gets its own namespace in the Konfig control plane. This namespace has its own service account that is scoped only to the GCP project associated with this domain environment. This allows the control plane to provision workloads and resources within a domain while having strong isolation between different domains and different environments.
We already discussed how Konfig manages IAM for workloads and implements least-privilege access. It’s important to note that, like the CI/CD service accounts, these workload service accounts have no keys associated with them and thus are never exposed to humans or to the CI/CD system. This means they are fully decoupled and easier to audit and monitor.
GitOps, branching, and release strategies
Konfig uses a GitOps model for managing platforms, domains, workloads, and infrastructure resource templates. These constructs are defined in YAML and deployed or promoted using Git-based workflows like merging a branch into main or tagging a release. This model is a best practice that provides a declarative single source of truth for our infrastructure (which is normally referred to as Infrastructure as Code or IaC), our GitLab and GCP implementations, and our organizational standards (by way of resource templates). For instance, we saw earlier how these declarative configurations are used to manage permissions in GitLab and GCP. This allows us to apply the same SDLC we use for application source code to our enterprise platform. This more comprehensive approach to managing infrastructure, source control, CI/CD, and cloud environment is something we call Platform as Code.
Konfig promotes a trunk-based development workflow with merge requests and code reviews. Releases are done by creating a tag. This GitOps model provides a clear audit trail and approval flow that most developers are already familiar with. This not only lends itself to providing a better developer experience but also a strong governance story. Infrastructure configuration is treated as data stored in source control. This makes it easy to backup and restore, but we’ve also chosen a format that is widely supported and makes writing custom tooling or integrating with existing tools easy.
Image promotion and single container artifact
Workload repositories can only contain a single deployable artifact. This means monorepos are not supported in Konfig, and repositories may only have a single Dockerfile that gets built and deployed. It also means workloads need to be containerized. This allows Konfig to make certain assumptions about CI/CD and SDLC that further improve the developer experience, security, and governance.
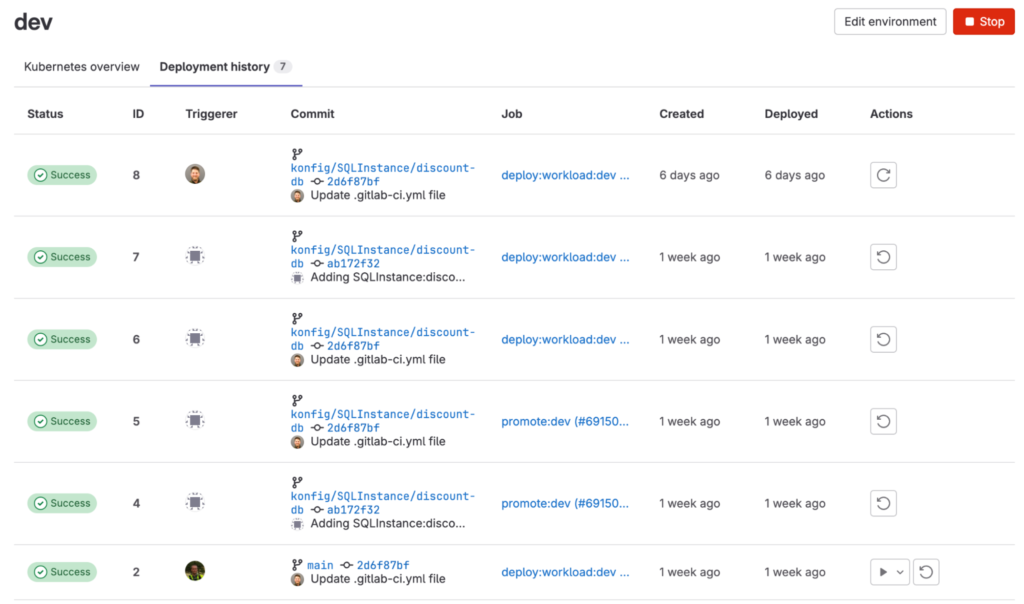
A problem we see regularly at companies is images getting rebuilt for different environments. Konfig’s image promotion model ensures the images used for testing are what is deployed to production without rebuilding containers or copying artifacts from development environments. The use of releases and environments in GitLab ensures there is a clear auditing and tracking of artifacts so that you know exactly what is deployed, by whom, and when.
GitLab’s environment view shows the history of all deployments to an environment
Managed services and serverless over other options when possible
We’ve spoken at length about the benefits of serverless and how, for many businesses, it may be a better fit than Kubernetes. Previously, I mentioned that one of the reasons we chose GCP initially to build an enterprise-ready platform was because of its emphasis on serverless and managed services. In particular, services like Cloud Run, GKE, and Dataflow are truly industry-leading container platforms. For this reason, Konfig supports these runtimes natively. We recommend Cloud Run as the default workload runtime but provide GKE as a supported engine for cases where Cloud Run is just not a good fit. Dataflow provides a fully managed execution environment for unified batch and stream data processing.
Leveraging managed services and serverless greatly reduces operational burden, improves security posture, allows developers to focus on product and feature development, and reduces production lead times. By supporting a smaller set of services, we can provide a great developer experience and security posture by automatically configuring service account permissions, autowiring environment variables in application containers, managing secrets, and a number of other benefits. Reducing options also simplifies architecture, improves maintainability and supportability, and reduces infrastructure sprawl. We’ve said before, we believe organizations should invest their engineers’ creativity and time into differentiating their customer-facing products and services, not infrastructure and other non-differentiating work.
This is similar in nature to PaaS, but where Konfig differs is it provides an “escape hatch.” That is to say, it provides well-supported paths for both working around the platform’s opinions and constraints and for moving off of the platform if needed. I’ll touch on these a bit later.
Resource templates over bespoke configurations
Infrastructure as code is often quite complicated because infrastructure is complicated. If you’ve ever worked with a large Terraform configuration you’ve probably experienced the challenges and pain points. It can be tedious to maintain and every implementation of it is different from company to company or even team to team. Konfig takes a different approach that provides an improved developer experience and stronger governance model. Workload definitions specify important metadata about a service such as the runtime engine, CPU and memory settings, infrastructure resources, and dependencies on other services. These definitions provide a declarative and holistic view of a workload that sits alongside the source code and follows the same SDLC.
Below is a simple workload.yaml for a service with three infrastructure resources, a Cloud Storage bucket, a Cloud SQL database, and a Pub/Sub topic. If you recall, the Konfig control plane will handle provisioning these resources and configuring the service account with properly scoped roles. It will also inject environment variables into the container so that the service can “discover” these resources at runtime.
Example workload.yaml showing resource dependencies
As you can imagine, there’s a lot more to configuring these resources than simply specifying their name. This is where Konfig’s notion of resource templates comes into play. Konfig relies on resource templates to abstract the complexity of configuring cloud resources and provide a means to implement and enforce organizational standards. For instance, we might enforce a specific version of PostgreSQL, high availability mode, and customer-managed encryption keys. For non-production environments, we may use a non-HA configuration to reduce costs.
This model allows a platform engineering or SRE team to centrally manage default or required configurations for resources. Now organizations can enforce a “golden path” or a standardized way of building something within their organization. Rather than relying on external policy scanners like Checkov that work reactively, we can build our policies directly into the platform and hide most of the complexity from developers, allowing them to focus on what matters: product and feature work. An organization can choose the right balance between autonomy and standardization for their unique situation, and we can eliminate infrastructure and architecture fragmentation.
Standardizing API ingress and routing is another key part of reducing architecture fragmentation and improving developer productivity. Konfig takes an opinionated stance on how workloads interact with each other and how external traffic interacts with a workload. By default, workloads are only accessible to other workloads in the same domain. However, we can also expose workloads to other workloads in the same platform or even across platforms if they are within the same control plane. Lastly, we can expose a workload to external traffic from the internet or from other control planes.
Konfig manages load balancers to make this ingress seamless and straightforward. It also utilizes path-based routing that maps to the platform, domain, workload hierarchy to provide a clean way of exposing APIs. Path-based routing is a best practice we promote because, compared to host-based routing, there’s less infrastructure to maintain, it removes cross-origin resource sharing (CORS) as a concern, and there are significantly fewer DNS records involved. A common challenge for SaaS companies is getting customers to whitelist hostnames. This is often a major headache for enterprise customers where whitelisting hostnames can be difficult. Path-based routing eliminates this problem by exposing services under the same domain.
Config Connector for IaC rather than Terraform
As mentioned earlier, one of the reasons we chose GCP as the initial cloud platform supported in Konfig is Config Connector. Config Connector is a Kubernetes operator that lets you manage GCP resources the same way you manage Kubernetes applications, and it’s a model that many other cloud platforms and infrastructure providers are adopting as well. Config Connector offers a compelling alternative to Terraform for managing IaC with a number of advantages.
First, because Config Connector is specific to GCP, it offers a more native integration with the platform. This includes more fine-grained status reporting that tells us the state of individual resources. It also lets us benefit from Kubernetes events for improved visibility. This allows us to provide greater visibility into what is happening with your infrastructure which results in a better overall developer experience.
Second, it enables us to use a combination of Kubernetes RBAC and GCP IAM for managing access control. With this model, we can have strong security boundaries and reduced blast radius as it relates to infrastructure.
Third, Config Connector provides an improved model for state management and reconciliation. With Terraform, managing state drift and environment promotions can be challenging. Additionally, the Terraform state file often contains secrets stored in clear text which is a security risk and requires the state file itself to be treated as highly sensitive data. Yet, Terraform does not support client-side state encryption but rather relies on at-rest encryption of the state backends (this is one of the areas Terraform and OpenTofu have diverged). It’s also common to hit race conditions in Terraform, where certain resources need to spin up before others can successfully apply. Sometimes this doesn’t happen and the deploy fails, requiring the apply to be re-run.
Config Connector takes a very different approach which solves these issues. Instead, it relies on a control loop which periodically reconciles resources to automatically correct drift. Think of it almost like “terraform apply” running regularly to ensure your desired state and actual state are in constant lockstep. The other benefit is it decouples dependent resources so we avoid race conditions and sequencing problems. This is possible because Config Connector models infrastructure as an eventually consistent state. This means resources can provision independently, even if their dependencies are not ready—no more re-running jobs to get a failed apply to work. Lastly, it can rely on Kubernetes secrets or GCP Secret Manager secrets to store sensitive information such as passwords or credentials. Sensitive data is properly isolated from our infrastructure configuration.
Finally, it’s possible to both bulk import existing resources into Config Connector and export resources to Terraform. This makes it possible to migrate existing infrastructure into Config Connector or migrate from Config Connector to Terraform. Config Connector can also reference resources that it does not manage using external references. This provides a means to gradually migrate to or from Config Connector.
Dealing with constraints and vendor lock-in
Konfig is different from typical PaaS offerings in that it really is an opinionated bundling of components rather than a proprietary, monolithic platform or “walled garden.” Normally, with PaaS systems like Google App Engine or Heroku, you relied on proprietary APIs to build applications which made it very difficult to migrate off when the time came. It also meant when you hit the limits of the platform, that’s it. There’s nothing you can do to work around them. At the other end of the spectrum are products like Crossplane, which are geared towards helping you build your own internal cloud platform. This puts you squarely back into the realm of staffing a team of highly paid platform engineers to build and maintain such a platform. For some companies, this might be a strategic place to invest. For most, it’s not.
And while there are proprietary value-add components to Konfig we have built, the core of it is products you’re already using—namely GitLab and GCP—and the open source Config Connector. The value of Konfig is that it is an opinionated implementation of these pieces that reduces an organization’s total cost of ownership for an enterprise cloud platform and shortens the delivery time for new software products. What this means, though, is that there really isn’t any vendor lock-in beyond whatever lock-in GitLab and GCP already have. Because it’s built around Config Connector, you can just as well use Config Connector to manage your resources directly, you’ll just lose the benefits of Konfig like GitLab and GCP integration and governance, automatic resource provisioning and IAM, ingress management, and the Konfig UI.
Config Connector provides us a powerful escape hatch, either in the case of needing to remove Konfig or needing to step outside Konfig’s opinions. If we want to remove Konfig, we have a couple options. We can export the Config Connector resource definitions that Konfig manages and import them into a new Config Connector instance. This Config Connector instance can be run either as a GKE add-on which is fully managed by Google, or it can be installed into a GKE cluster manually. Alternatively, we can export the resources managed by Konfig to Terraform.
If we need to step outside Konfig’s opinions, for example to provision a resource not currently supported by Konfig such as a VM, we can use Config Connector directly which supports a broad set of resources. We can manage these resources using the same GitOps model we use for Konfig workloads. With this, we have an opinionated platform that can support an organization’s most common needs but, unlike a PaaS, can grow and evolve with your organization.
Konfig reduces your cloud platform engineering costs and the time to deliver new software products. Reach out to learn more about Konfig or schedule a demo.