The platform engineering toolkit for Kubernetes

Last month we open sourced Koreo, our “platform engineering toolkit for Kubernetes.” Since then, we’ve seen a lot of interest from folks in the platform engineering and DevOps space. We’ve also gotten a lot of questions from people trying to better understand how Koreo fits into an already crowded landscape of Kubernetes tools. Koreo is a fairly complex tool, so it can be difficult to quickly grasp just what exactly it is, what problems it’s designed to solve, and how it compares to other, similar tools. In this post, I want to dive into these topics and also discuss the original motivation behind Koreo.
If you’ve read the Koreo website, you’ll know that we refer to it as “a new approach to Kubernetes configuration management and resource orchestration,” but what does this really mean? There are two parts to unpack here: configuration management and resource orchestration.
By far, the most common approach to configuration management in Kubernetes is Helm. Helm charts provide a convenient way to templatize and package up Kubernetes resources and make them configurable via values files. There are some challenges and limitations with Helm though. One is around how it works as a templating system. We talked about this in depth here so I won’t go into a ton of detail, but a challenge with Helm is when charts begin to grow beyond basic templating. Once you start to introduce logic and nested conditionals into your templates, they quickly become difficult to understand, maintain, and evolve. Helm is actually a pretty rudimentary approach because it really just treats configuration management as YAML string templating.
Kustomize can handle some of these cases better by letting you specify base resource manifests and then customize them through overlays and patches that are more structurally aware. However, this largely assumes that the configuration variations are static and don’t rely on computed values or business logic. In other words, as deployments grow in complexity, Kustomize’s reliance on static overlays can become cumbersome and limiting.
Helm and Kustomize are not resource orchestrators—they’re templating tools. If your resources have non-deterministic dependencies on each other, you’ll need to handle this sequencing yourself. For example, to create a VPC and then a Kubernetes cluster in AWS, you must first apply the VPC and then use something like Helm’s lookup function to retrieve its outputs (e.g. subnets) for use in templating the cluster. There are a lot of situations where the inputs of a resource require the outputs of a different resource. Some of these might be deterministic, perhaps like a CIDR block, but many are not. This dependency between resources is what I mean by resource orchestration. Most tools treat configuration management and resource orchestration as separate concerns: tools like Helm, Kustomize, Jsonnet, and Cue handle configuration management, while tools like Crossplane, Argo, and Kro address resource orchestration. But in practice, these responsibilities are often deeply intertwined. Especially in platform engineering, configuring resources almost always requires orchestrating them.
The Motivation Behind Koreo
Koreo was built to make platform engineers’ lives easier. We originally developed it out of a need to both configure and orchestrate cloud resources across GCP and AWS—using Config Connector and ACK—and integrate them cleanly into a broader internal developer platform. Helm wasn’t viable due to its lack of orchestration capabilities. Crossplane, while powerful, proved overly complex but also had several key limitations, namely it’s tightly coupled to Provider APIs and it offers limited support for multitenancy. Kro didn’t exist at the time, but even today it remains too rigid and inflexible for our needs. We also required a way to define standard, base configurations for resources, expose only certain configuration knobs to application teams, and give developers the ability to safely customize what they needed.
Additionally, we felt that much of the innovation in platform engineering and DevOps has thrown away a lot of the learnings and developments that have occurred in software engineering over the last several decades. In particular, many modern infrastructure and platform tools lack robust mechanisms for testing configuration and orchestration logic. Unlike application code, which benefits from well-established practices around unit testing, integration testing, and CI workflows, platform code is often fragile, opaque, and difficult to validate. There’s no easy way to test a change to a Helm chart or a Crossplane composition without applying it to the cluster and hoping for the best. This leads to brittle platforms, longer feedback cycles, and a higher risk of outages. With Koreo, we wanted to bring the rigor of software development—testable components, reproducible workflows, clear interfaces—into the platform space.
We initially built platforms using custom controllers implemented in Go and Python, which allowed us to move quickly. However, extending and iterating on the platform became increasingly difficult and time-consuming. In order to make it easier to implement new capabilities quickly, one of our developers built a lightweight framework to orchestrate workflows by mapping values between steps. Another developer sought to make our existing system more flexible with a simple approach to configuration templating. When we saw these two ideas, which were in two different code bases in two different parts of the system, we realized that they could work well together, and the idea for Koreo was born.
Koreo’s Approach
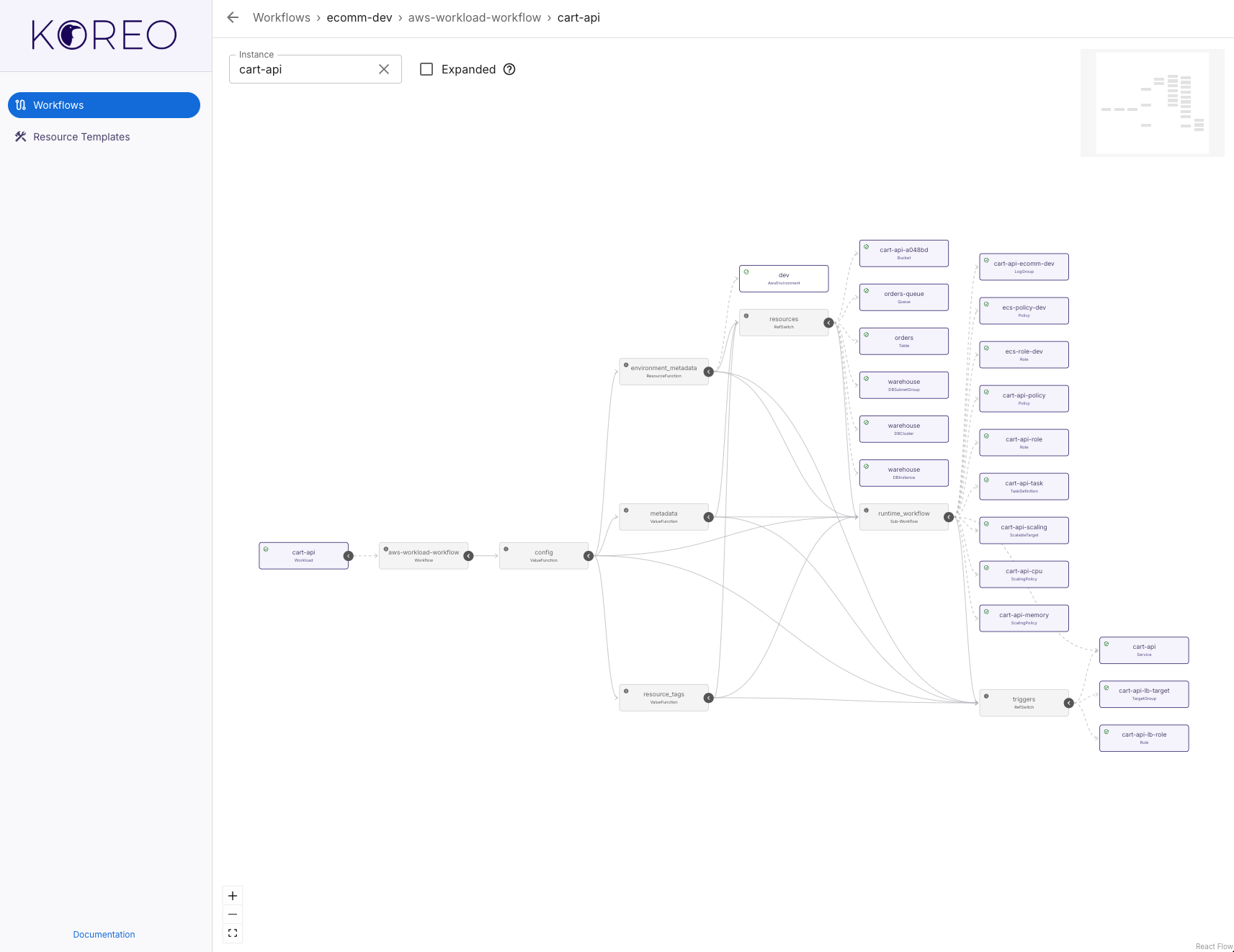
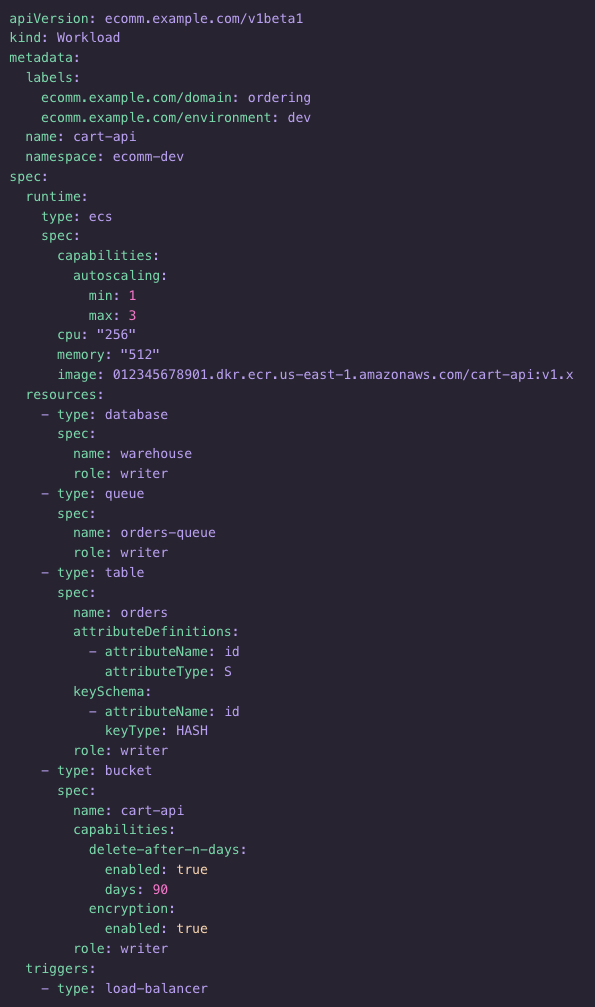
At the heart of Koreo are functions and workflows. Functions are small, reusable logic units that can either be pure and computational (we call these ValueFunctions) or side-effectful and capable of interacting with the Kubernetes API to create, modify, or read resources (ResourceFunctions). These are then composed into workflows, which define a graph of steps, conditions, and dependencies—kind of like a programmable controller but defined entirely in YAML.
We chose YAML deliberately because it doesn’t abstract what is actually being configured: Kubernetes resource manifests. We’ve found keeping the tool “true” to the underlying thing it manages reduces mental overhead for developers and makes it easier to reason about what is happening. This choice also brings some practical benefits. It’s easy to take an existing Kubernetes resource definition and use it as the basis for a ResourceFunction or ResourceTemplate. It also allows us to very cleanly test materialized resources. With FunctionTests, we can ensure resources are configured as expected based on inputs to the function. And by using ResourceTemplates, we can define standard base configurations and then overlay dynamic values on top. This approach to resource materialization allows us to decompose configuration into small, reusable components that can be tested both in isolation and as part of a larger workflow.
Koreo provides a unified approach to configuration management and resource orchestration. Workflows allow us to connect resources together by mapping the outputs of a resource to the inputs of another resource. For instance, let’s say you want to provision a GKE cluster, configure network policies, and deploy an application—all based on some higher-level spec like a tenant definition. With Koreo, you can define a workflow that reads the spec, provisions the GKE cluster, waits for it to be ready, extracts its outputs (e.g. endpoint, credentials), and passes them downstream to subsequent steps. Each step is explicit, composable, and testable.
In effect, Koreo lets you seamlessly integrate Kubernetes controllers and off-the-shelf operators like Config Connector and ACK into a cohesive platform. With this, you can build your own platform controllers without actually needing to implement a custom operator. Any resource in Kubernetes can be connected, and we can use Koreo’s control-flow primitives to implement workflows that are as simple as provisioning a few resources or as complex as automating an entire internal developer platform.
Why Koreo Matters
What makes Koreo different is that it treats platform engineering not as an afterthought to infrastructure management or application deployment, but as a discipline in its own right—one that deserves the same principles of clarity, testability, and modularity that we apply to software engineering. It’s not just about making YAML more bearable or chaining together a few CLI commands. It’s about enabling platform teams to build robust, composable, and predictable automation that supports developers without hiding important details or creating layers of abstraction that become liabilities over time.
Koreo lets you define your platform architecture as code, test it like code, and evolve it like code. It’s declarative, but programmable. It’s simple to start with, but powerful enough to scale across teams, environments, and cloud providers. It gives you a model for thinking about how platform components fit together and the control to manage that complexity as your needs grow.
What’s Next
Since open sourcing Koreo, we’ve been actively working on improving documentation, adding more examples, and expanding support for new use cases. We’re especially excited about adding support for managing resources in other Kubernetes clusters. This enables running Koreo as a centralized control plane in addition to a federated model. We’re also investing in better tooling around developer experience, like improved type checking, workflow debugging, and enhanced UI capabilities to visualize workflow executions.
If you’re a platform engineer, SRE, or DevOps practitioner struggling to manage the growing complexity of Kubernetes-based platforms, we’d love for you to give Koreo a shot. We’re just getting started, and we’d love your feedback.
Follow @tyler_treat