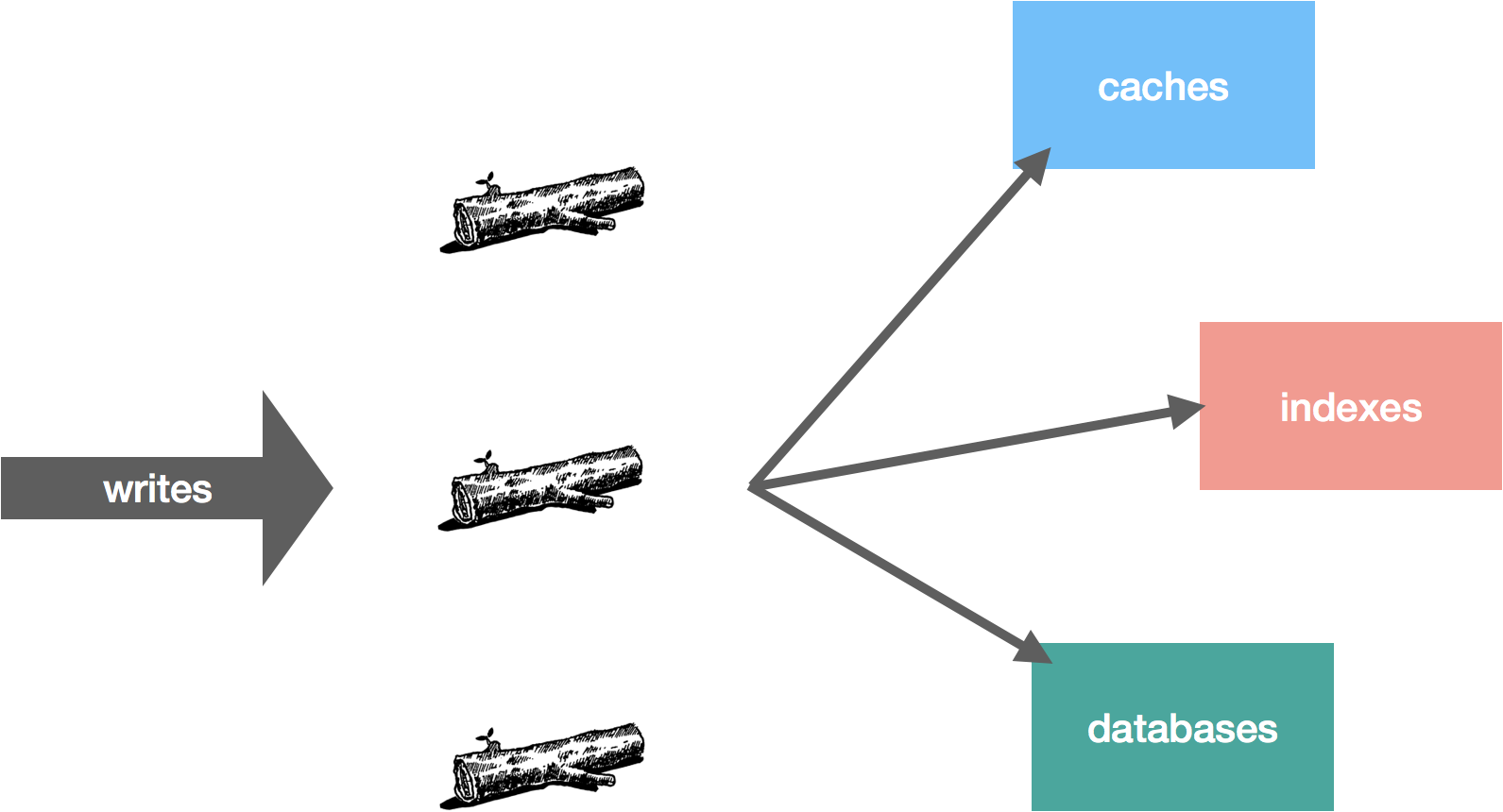
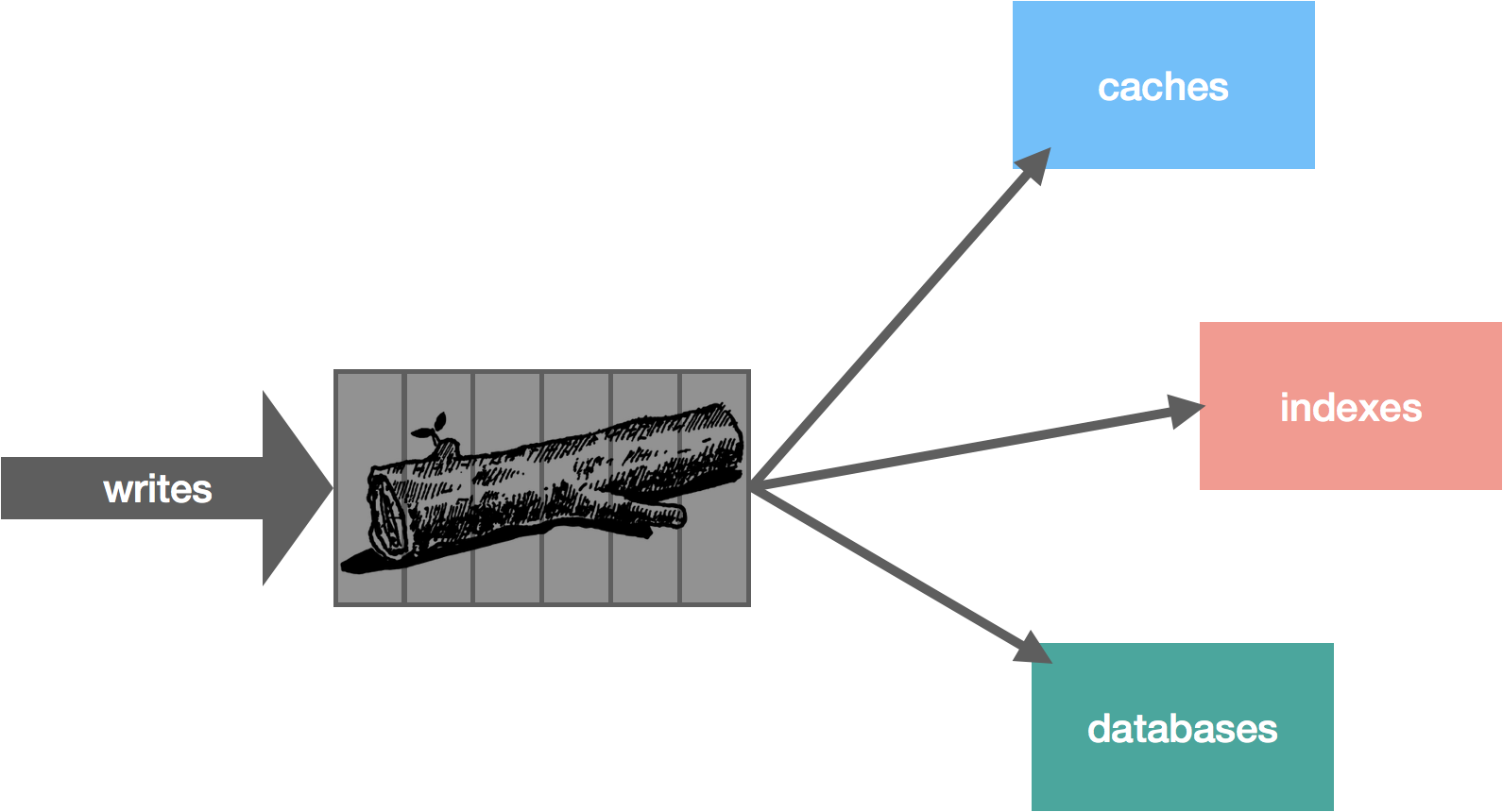
In part four of this series we looked at some key trade-offs involved with a distributed log implementation and discussed a few lessons learned while building NATS Streaming. In this fifth and final installment, we’ll conclude by outlining the design for a new log-based system that draws from the previous entries in the series.
The Context
For context, NATS and NATS Streaming are two different things. NATS Streaming is a log-based streaming system built on top of NATS, and NATS is a lightweight pub/sub messaging system. NATS was originally built (and then open sourced) as the control plane for Cloud Foundry. NATS Streaming was built in response to the community’s ask for higher-level guarantees—durability, at-least-once delivery, and so forth—beyond what NATS provided. It was built as a separate layer on top of NATS. I tend to describe NATS as a dial tone—ubiquitous and always on—perfect for “online” communications. NATS Streaming is the voicemail—leave a message after the beep and someone will get to it later. There are, of course, more nuances than this, but that’s the gist.
The key point here is that NATS and NATS Streaming are distinct systems with distinct protocols, distinct APIs, and distinct client libraries. In fact, NATS Streaming was designed to essentially act as a client to NATS. As such, clients don’t talk to NATS Streaming directly, rather all communication goes through NATS. However, the NATS Streaming binary can be configured to either embed NATS or point to a standalone deployment. The architecture is shown below in a diagram borrowed from the NATS website.
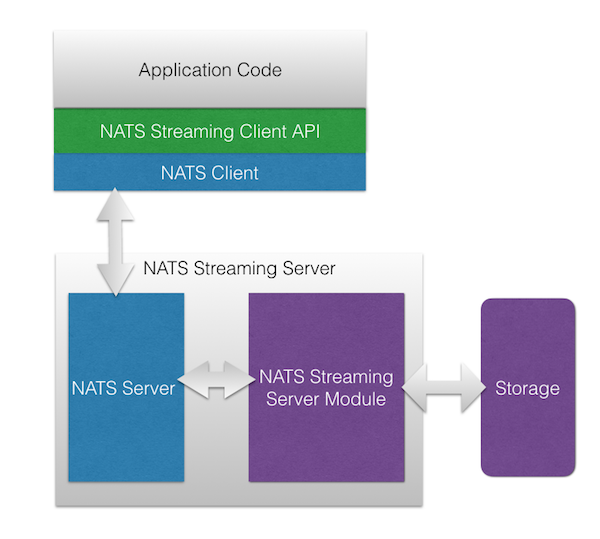
Architecturally, this makes a lot of sense. It supports the end-to-end principle in that we layer on additional functionality rather than bake it in to the underlying infrastructure. After all, we can always build stronger guarantees on top, but we can’t always remove them from below. This particular architecture, however, introduces a few challenges (disclosure: while I’m still a fan, I’m no longer involved with the NATS project and the NATS team is aware of these problems and no doubt working to address many of them).
First, there is no “cross-talk” between NATS and NATS Streaming, meaning messages published to NATS are not visible in NATS Streaming and vice versa. Again, they are two completely separate systems that just share the same infrastructure. This means we’re not really layering on message durability to NATS, we’re just exposing a new system which provides these semantics.
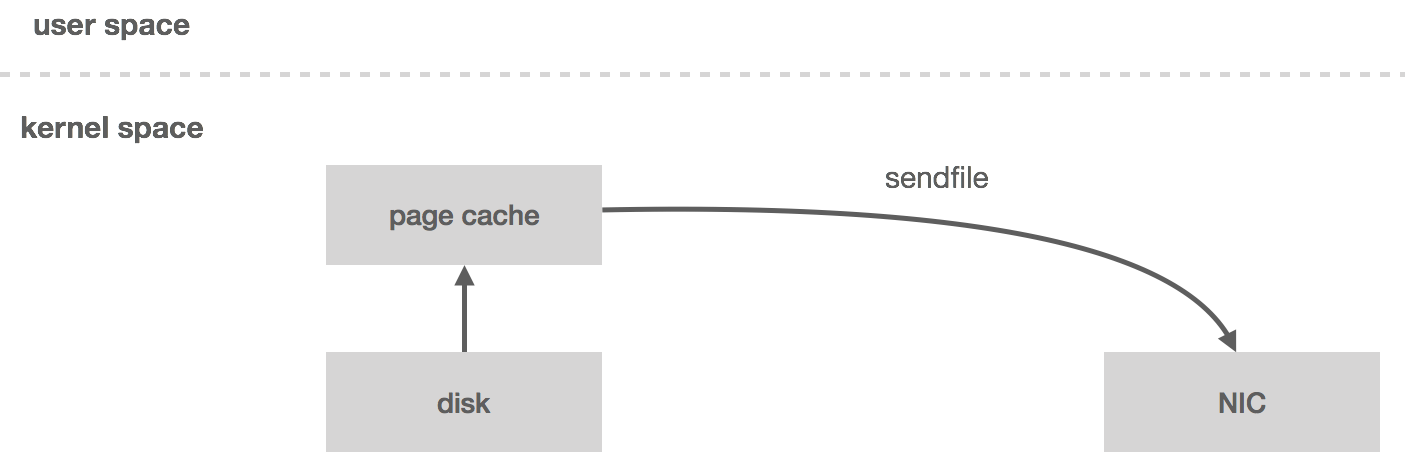
Second, because NATS Streaming runs as a “sidecar” to NATS and all of its communication runs through NATS, there is an inherent bottleneck at the NATS connection. This may only be a theoretical limit, but it precludes certain optimizations like using sendfile to do zero-copy reads of the log. It also means we rely on timeouts even in cases where the server could send a response immediately, such as when there is no leader elected for the cluster.
Third, NATS Streaming currently lacks a compelling story around linear scaling other than running multiple clusters and partitioning channels among them at the application level. With respect to scaling a single channel, the only alternative at the moment is to partition it into multiple channels at the application level. My hope is that as clustering matures, this will too.
Fourth, without extending its protocol, NATS Streaming’s authorization is intrinsically limited to the authorization provided by NATS since all communication goes through it. In and of itself, this isn’t a problem. NATS supports multi-user authentication and subject-level permissions, but since NATS Streaming uses an opaque protocol atop NATS, it’s difficult to setup proper ACLs at the streaming level. Of course, many layered protocols support authentication, e.g. HTTP atop TCP. For example, the NATS Streaming protocol could carry authentication tokens or session keys, but it currently does not do this.
Fifth, NATS Streaming does not support wildcard semantics, which—at least in my opinion—is a large selling point of NATS and, as a result, something users have come to expect. Specifically, NATS supports two wildcards in subject subscriptions: asterisk (*) which matches any token in the subject (e.g. foo.* matches foo.bar, foo.baz, etc.) and full wildcard (>) which matches one or more tokens at the tail of the subject (e.g. foo.> matches foo.bar, foo.bar.baz, etc.). Note that this limitation in NATS Streaming is not directly related to the overall architecture but more in how we design the log.
More generally, clustering and data replication was more of an afterthought in NATS Streaming. As we discussed in part four, it’s hard to add this after the fact. Combined with the APIs NATS Streaming provides (which do flow control and track consumer state), this creates a lot of complexity in the server.
A New System
I wasn’t involved much with NATS Streaming beyond the clustering implementation. However, from that work—and through my own use of NATS and from discussions I’ve had with the community—I’ve thought about how I would build something like it if I were to start over. It would look a bit different from NATS Streaming and Kafka, yet also share some similarities. I’ve dubbed this theoretical system Jetstream (update: this is now Liftbridge), though I’ve yet to actually build anything beyond small prototypes. It’s a side project of mine I hope to get to at some point.
Core NATS has a strong community with solid mindshare, but NATS Streaming doesn’t fully leverage this since it’s a new silo. Jetstream aims to address the above problems starting from a simple proposition: many people are already using NATS today and simply want streaming semantics for what they already have. However, we must also acknowledge that other users are happy with NATS as it currently is and have no need for additional features that might compromise simplicity or performance. This was a deciding factor in choosing not to build NATS Streaming’s functionality directly into NATS.
Like NATS Streaming, Jetstream is a separate component which acts as a NATS client. Unlike NATS Streaming, it augments NATS as opposed to implementing a wholly new protocol. More succinctly, Jetstream is a durable stream augmentation for NATS. Next, we’ll talk about how it accomplishes this by sketching out a design.
Cross-Talk
In NATS Streaming, the log is modeled as a channel. Clients create channels implicitly by publishing or subscribing to a topic (called a subject in NATS). A channel might be foo but internally this is translated to a NATS pub/sub subject such as _STAN.pub.foo. Therefore, while NATS Streaming is technically a client of NATS, it’s done so just to dispatch communication between the client and server. The log is implemented on top of plain pub/sub messaging.
Jetstream is merely a consumer of NATS. In it, the log is modeled as a stream. Clients create streams explicitly, which are subscriptions to NATS subjects that are sequenced, replicated, and durably stored. Thus, there is no “cross-talk” or internal subjects needed because Jetstream messages are NATS messages. Clients just publish their messages to NATS as usual and, behind the scenes, Jetstream will handle storing them in a log. In some sense, it’s just an audit log of messages flowing through NATS.
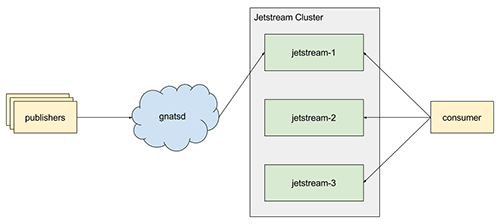
With this, we get wildcards for free since streams are bound to NATS subjects. There are some trade-offs to this, however, which we will discuss in a bit.
Performance
Jetstream does not track subscription positions. It is up to consumers to track their position in a stream or, optionally, store their position in a stream (more on this later). This means we treat a stream as a simple log, allowing us to do fast, sequential disk I/O and minimize replication and protocol chatter as well as code complexity.
Consumers connect directly to Jetstream using a pull-based socket API. The log is stored in the manner described in part one. This enables us to do zero-copy reads from a stream and other important optimizations which NATS Streaming is precluded from doing. It also simplifies things around flow control and batching as we discussed in part three.
Scalability
Jetstream is designed to be clustered and horizontally scalable from the start. We make the observation that NATS is already efficient at routing messages, particularly with high consumer fan-out, and provides clustering of the interest graph. Streams provide the unit of storage and scalability in Jetstream.
A stream is a named log attached to a NATS subject. Akin to a partition in Kafka, each stream has a replicationFactor, which controls the number of nodes in the Jetstream cluster that participate in replicating the stream, and each stream has a leader. The leader is responsible for receiving messages from NATS, sequencing them, and performing replication (NATS provides per-publisher message ordering).
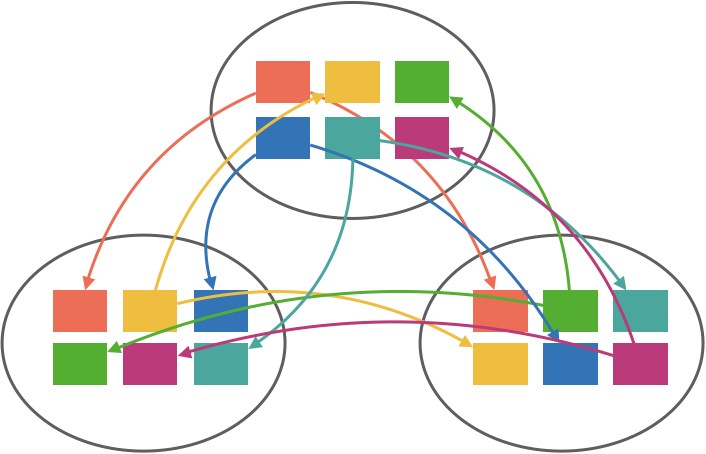
Like Kafka’s controller, there is a single metadata leader for a Jetstream cluster which is responsible for processing requests to create or delete streams. If a request is sent to a follower, it’s automatically forwarded to the leader. When a stream is created, the metadata leader selects replicationFactor nodes to participate in the stream (initially, this selection is random but could be made more intelligent, e.g. selecting based on current load) and replicates the stream to all nodes in the cluster. Once this replication completes, the stream has been created and its leader begins processing messages. This means NATS messages are not stored unless there is a stream matching their subject (this is the trade-off to support wildcards, but it also means we don’t waste resources storing messages we might not care about). This can be mitigated by having publishers ensure a stream exists before publishing, e.g. at startup.
There can exist multiple streams attached to the same NATS subject or even subjects that are semantically equivalent, e.g. foo.bar and foo.*. Each of these streams will receive a copy of the message as NATS handles this fan-out. However, the stream name is unique within a given subject. For example, creating two streams for the subject foo.bar named foo and bar, respectively, will create two streams which will independently sequence all of the messages on the NATS subject foo.bar, but attempting to create two streams for the same subject both named foo will result in creating just a single stream (creation is idempotent).
With this in mind, we can scale linearly with respect to consumers—covered in part three—by adding more nodes to the Jetstream cluster and creating more streams which will be distributed among the cluster. This has the advantage that we don’t need to worry about partitioning so long as NATS is able to withstand the load (there is also an assumption that we can ensure reasonable balance of stream leaders across the cluster). We’ve basically split out message routing from storage and consumption, which allows us to scale independently.
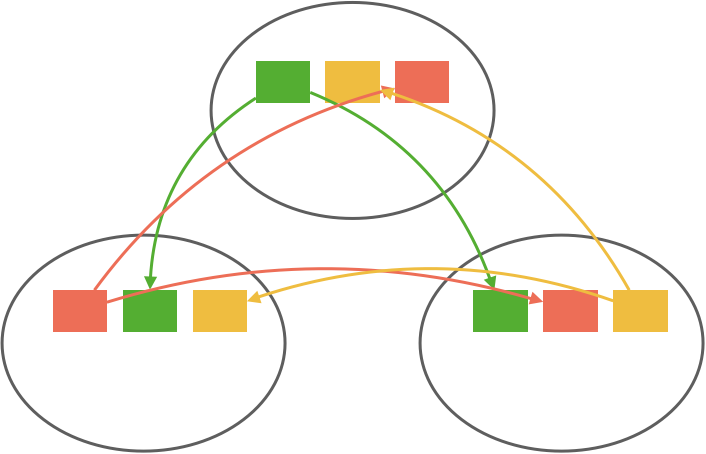
Additionally, streams can join a named consumer group. This, in effect, partitions a NATS subject among the streams in the group, again covered in part three, allowing us to create competing consumers for load-balancing purposes. This works by using NATS queue subscriptions, so the downside is partitioning is effectively random. The upside is consumer groups don’t affect normal streams.
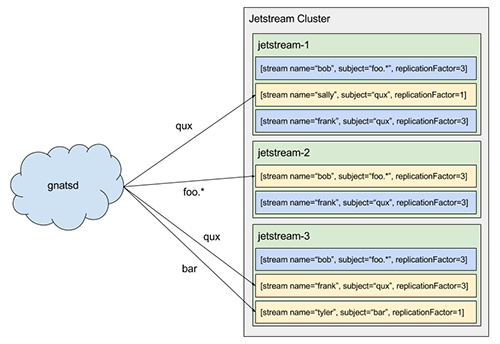
Compaction and Offset Tracking
Streams support multiple log-compaction rules: time-based, message-based, and size-based. As in Kafka, we also support a fourth kind: key compaction. This is how offset storage will work, which was described in part three, but it also enables some other interesting use cases like KTables in Kafka Streams.
As discussed above, messages in Jetstream are simply NATS messages. There is no special protocol needed for Jetstream to process messages. However, publishers can choose to optionally “enhance” their messages by providing additional metadata and serializing their messages into envelopes. The envelope includes a special cookie Jetstream uses to detect if a message is an envelope or a simple NATS message (if the cookie is present by coincidence and envelope deserialization fails, we fall back to treating it as a normal message).
One of the metadata fields on the envelope is an optional message key. A stream can be configured to compact by key. In this case, it retains only the last message for each key (if no key is present, the message is always retained).
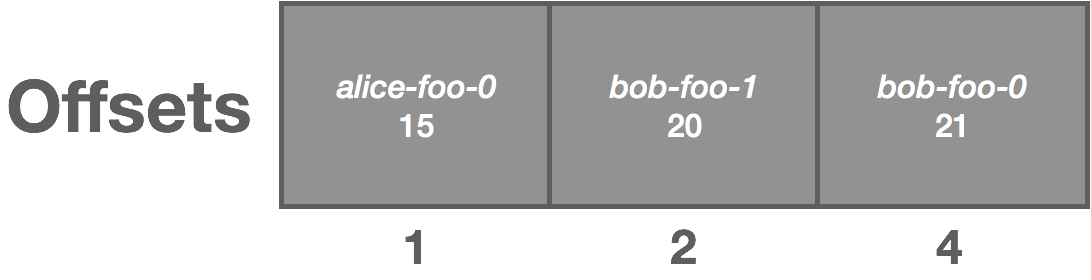
Consumers can optionally store their offsets in Jetstream (this can also be transparently managed by a client library similar to Kafka’s high-level consumer). This works by storing offsets in a stream keyed by consumer. A consumer (or consumer library) publishes their latest offset. This allows them to later retrieve their offset from the stream, and key compaction means Jetstream will only retain the latest offset for each consumer. For improved performance, the client library should only periodically checkpoint this offset.
Authorization
Because Jetstream is a separate server which is merely a consumer of NATS, it can provide ACLs or other authorization mechanisms on streams. A simple configuration might be to restrict NATS access to Jetstream and configure Jetstream to only allow access to certain subjects. There is more work involved because there is a separate access-control system, but this gives greater flexibility by separating out the systems.
At-Least Once Delivery
To ensure at-least-once delivery of messages, Jetstream relies on replication and publisher acks. When a message is received on a stream, it’s assigned an offset by the leader and then replicated. Upon a successful replication, the stream publishes an ack to NATS on the reply subject of the message, if present (the reply subject is a part of the NATS message protocol).
There are two implications with this. First, if the publisher doesn’t care about ensuring its message is stored, it need not set a reply subject. Second, because there are potentially multiple (or no) streams attached to a subject (and creation/deletion of streams is dynamic), it’s not possible for the publisher to know how many acks to expect. This is a trade-off we make for enabling subject fan-out and wildcards while remaining scalable and fast. We make the assertion that if guaranteed delivery is important, the publisher should be responsible for determining the destination streams a priori. This allows attaching streams to a subject for use cases that do not require strong guarantees without the publisher having to be aware. Note that this might be an area for future improvement to increase usability, such as storing streams in a registry. However, this is akin to other similar systems, like Kafka, where you must first create a topic and then you publish to that topic.
One caveat to this is if there are existing application-level uses of the reply subject on NATS messages. That is, if other systems are already publishing replies, then Jetstream will overload this. The alternative would be to require the envelope, which would include a canonical reply subject for acks, for at-least-once delivery. Otherwise we would need a change to the NATS protocol itself.
Replication Protocol
For metadata replication and leadership election, we rely on Raft. However, for replication of streams, rather than using Raft or other quorum-based techniques, we use a technique similar to Kafka as described in part two.
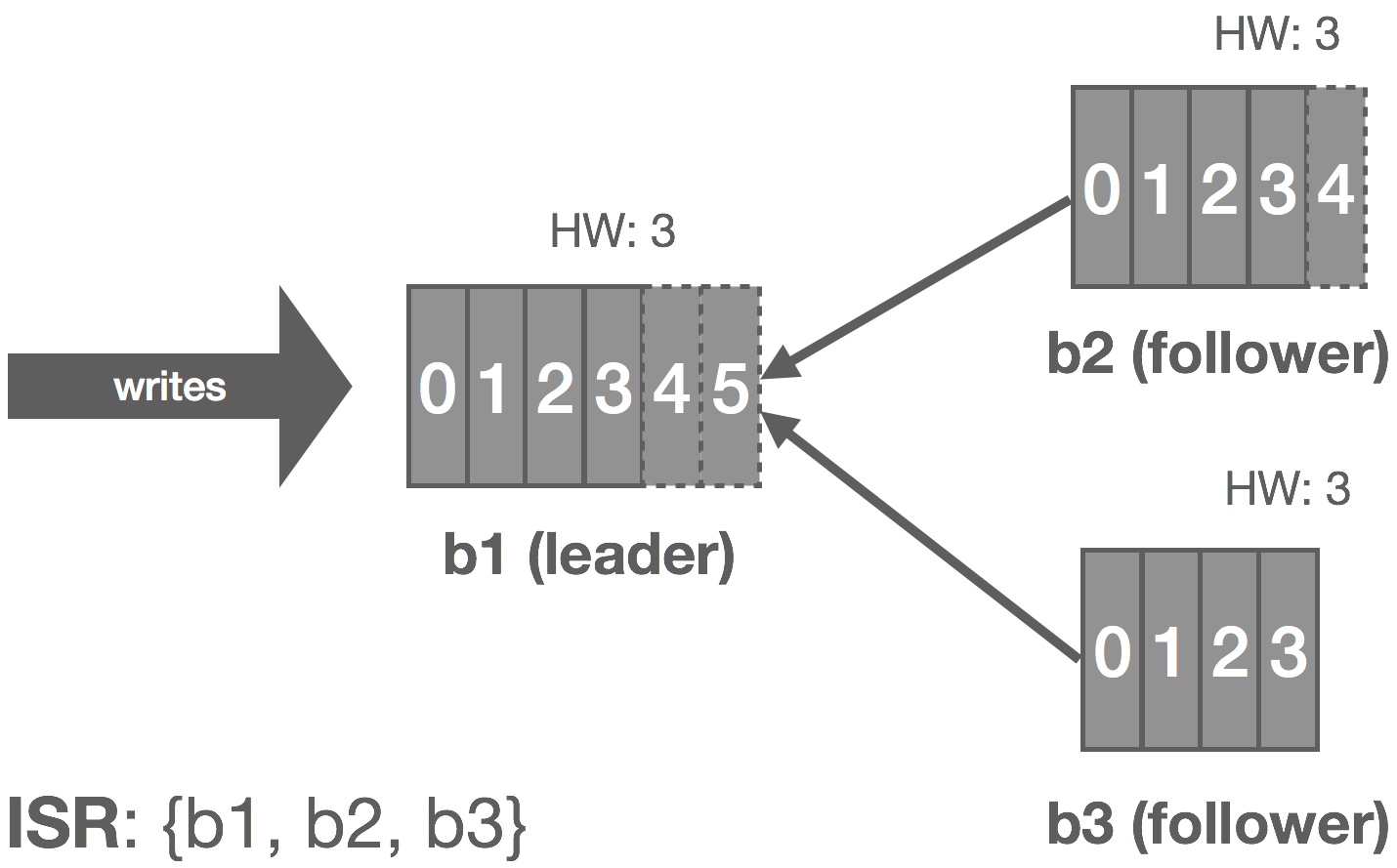
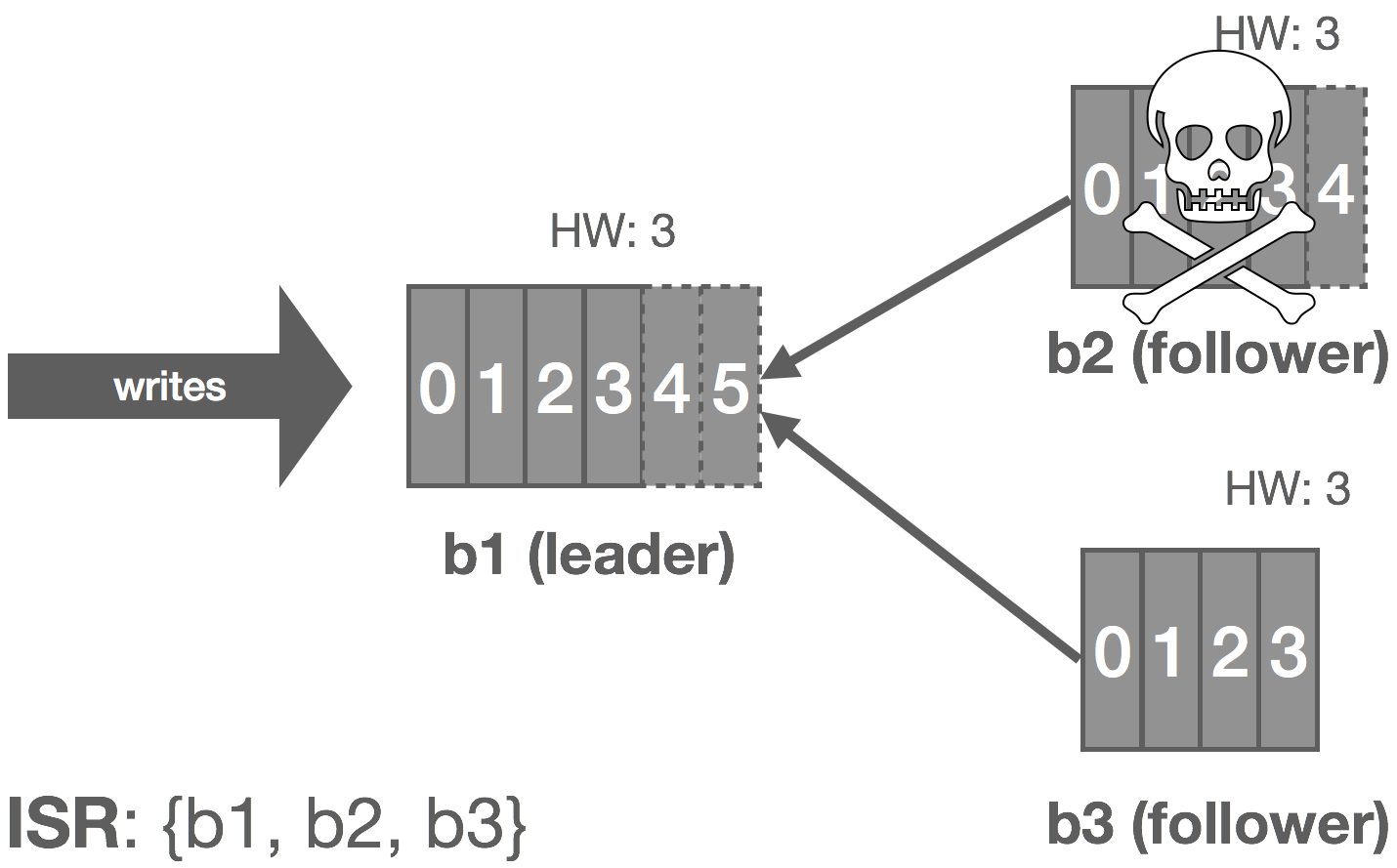
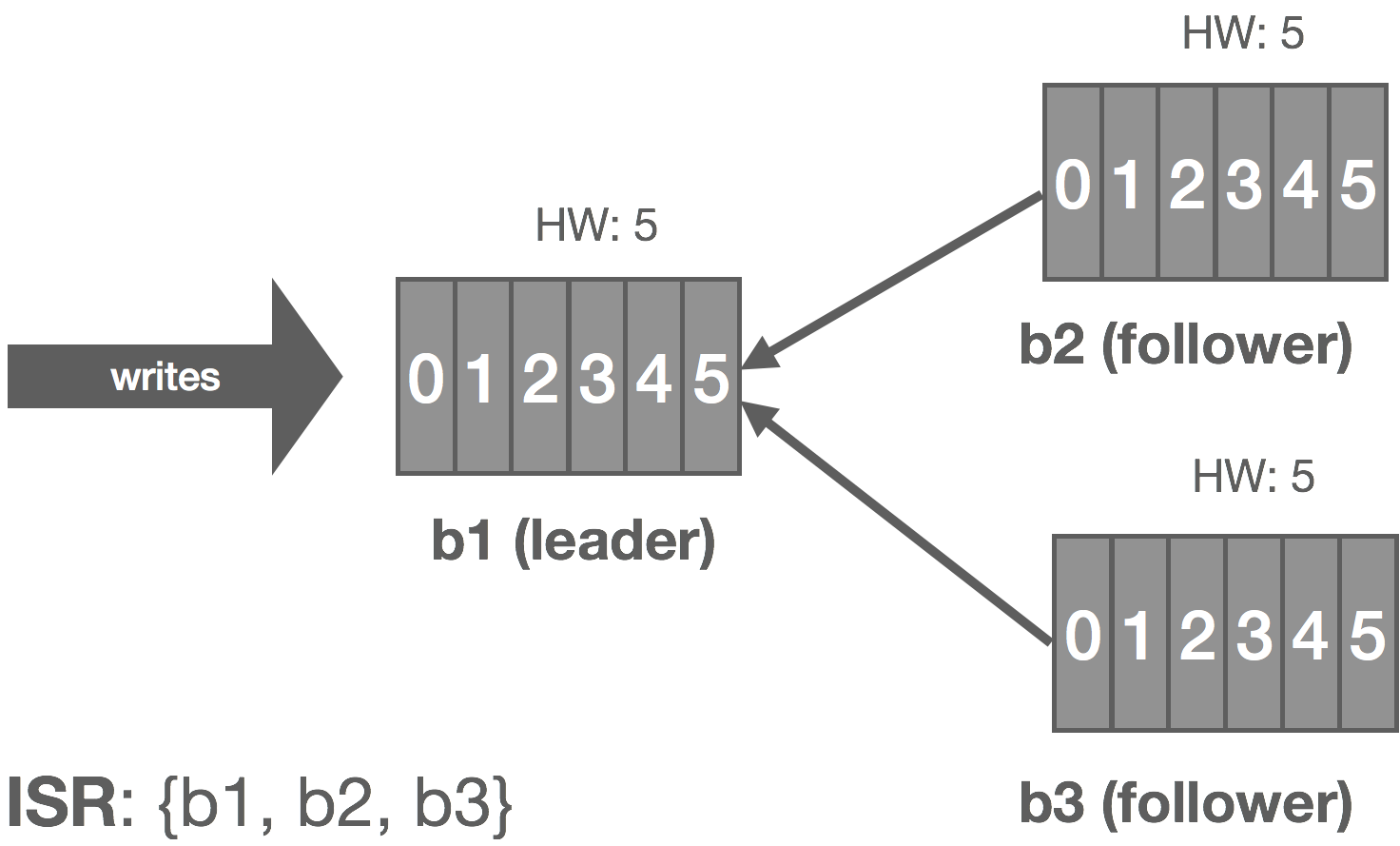
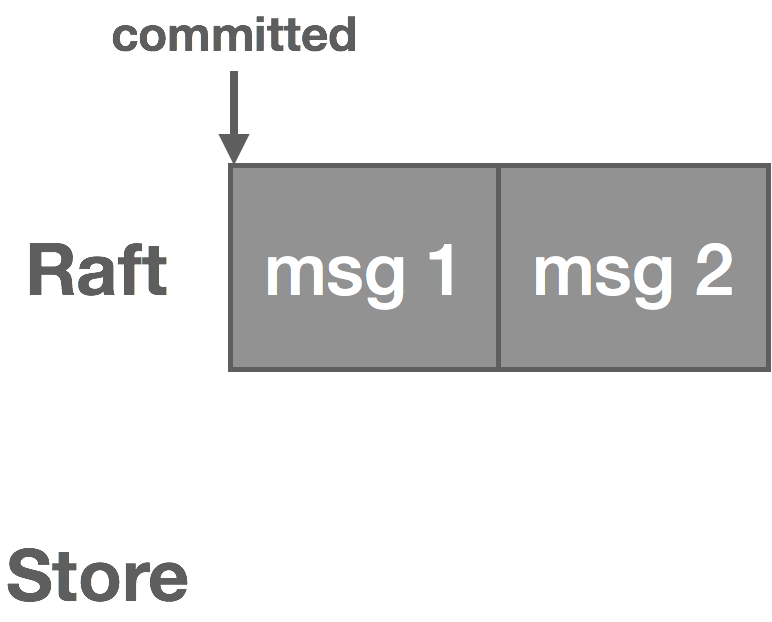
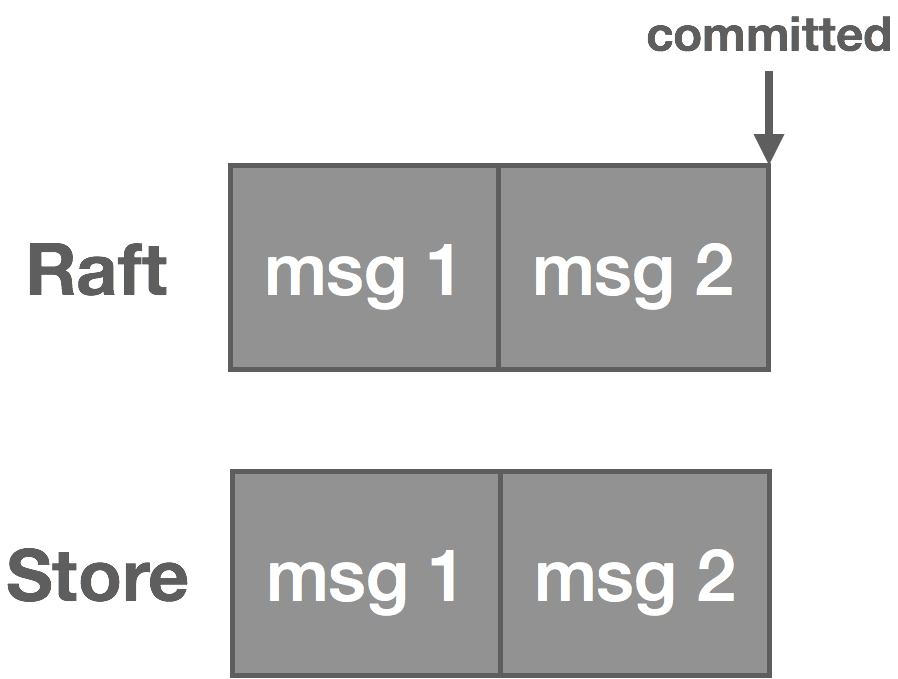
For each stream, we maintain an in-sync replica set (ISR), which is all of the replicas currently up to date (at stream creation time, this is all of the replicas). During replication, the leader writes messages to a WAL, and we only wait on replicas in the ISR before committing. If a replica falls behind or fails, it’s removed from the ISR. If the leader fails, any replica in the ISR can take its place. If a failed replica catches back up, it rejoins the ISR. The general stream replication process is as follows:
- Client creates a stream with a replicationFactor of n.
- Metadata leader selects n replicas to participate and one leader at random (this comprises the initial ISR).
- Metadata leader replicates the stream via Raft to the entire cluster.
- The nodes participating in the stream initialize it, and the leader subscribes to the NATS subject.
- The leader initializes the high-water mark (HW) to 0. This is the offset of the last committed message in the stream.
- The leader begins sequencing messages from NATS and writes them to the log uncommitted.
- Replicas consume from the leader’s log to replicate messages to their own log. We piggyback the leader’s HW on these responses, and replicas periodically checkpoint the HW to stable storage.
- Replicas acknowledge they’ve replicated the message.
- Once the leader has heard from the ISR, the message is committed and the HW is updated.
Note that clients only see committed messages in the log. There are a variety of failures that can occur in the replication process. A few of them are described below along with how they are mitigated.
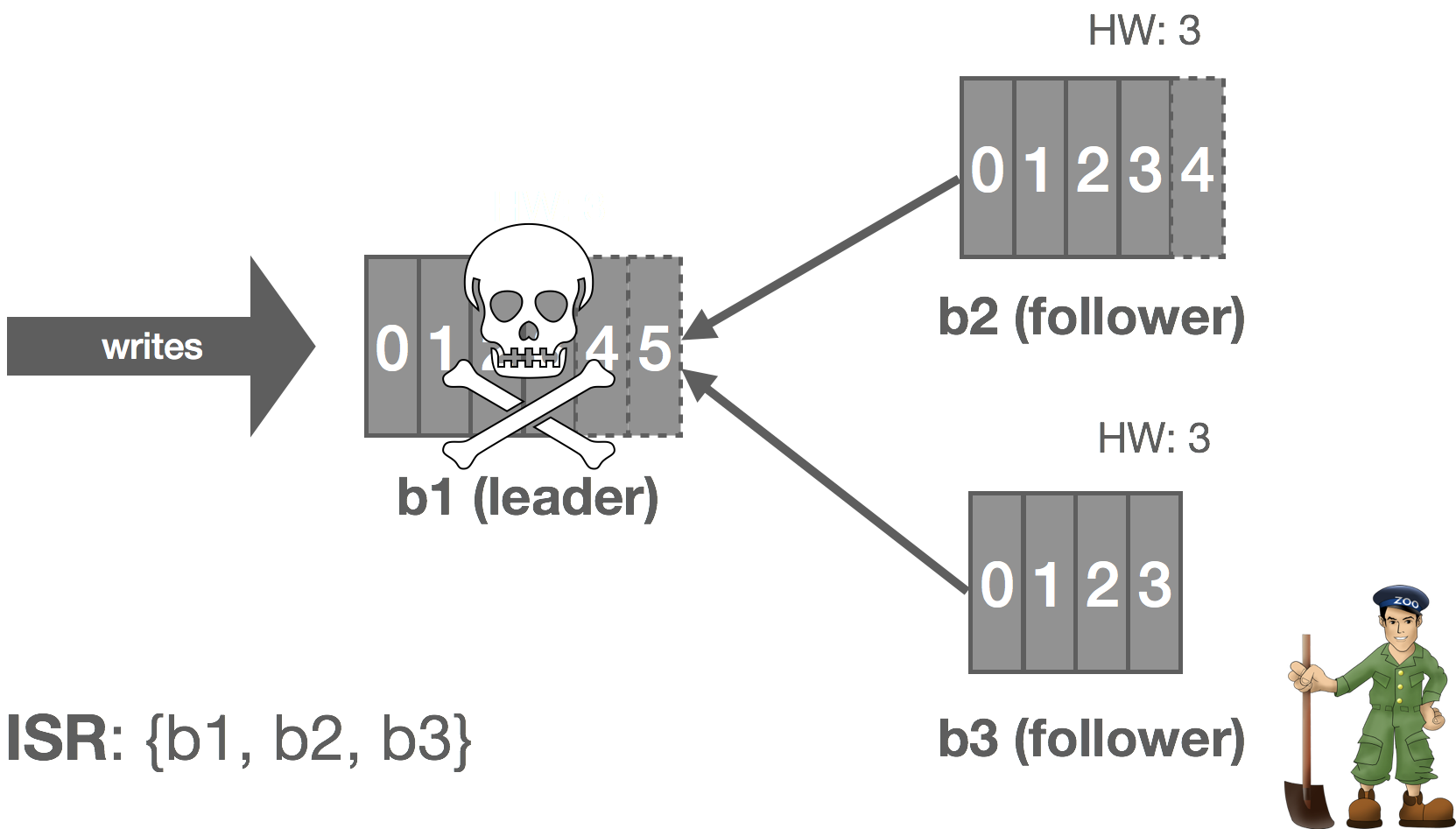
If a follower suspects that the leader has failed, it will notify the metadata leader. If the metadata leader receives a notification from the majority of the ISR within a bounded period, it will select a new leader for the stream, apply this update to the Raft group, and notify the replica set. These notifications need to go through Raft as well in the event of a metadata leader failover occurring at the same time as a stream leader failure. Committed messages are always preserved during a leadership change, but uncommitted messages could be lost.
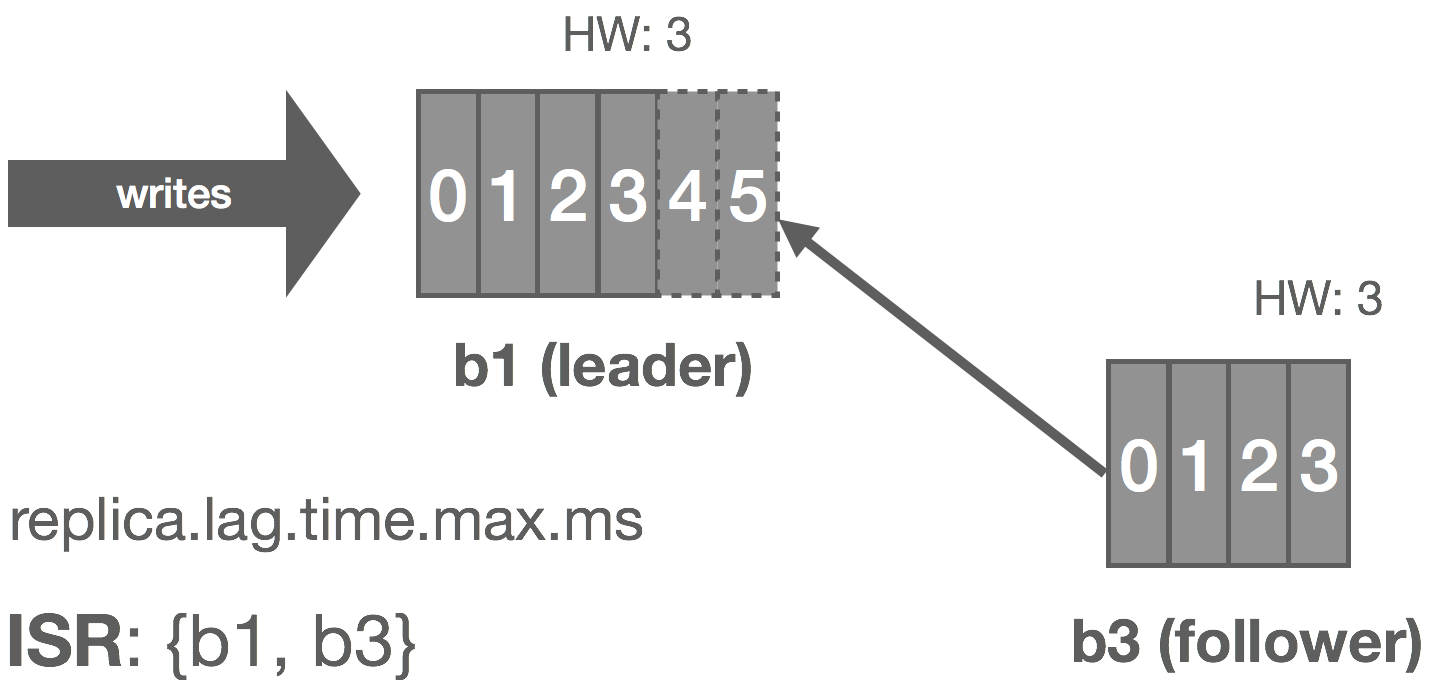
If the stream leader detects that a replica has failed or fallen too far behind, it removes the replica from the ISR by notifying the metadata leader. The metadata leader replicates this fact via Raft. The stream leader continues to commit messages with fewer replicas in the ISR, entering an under-replicated state.
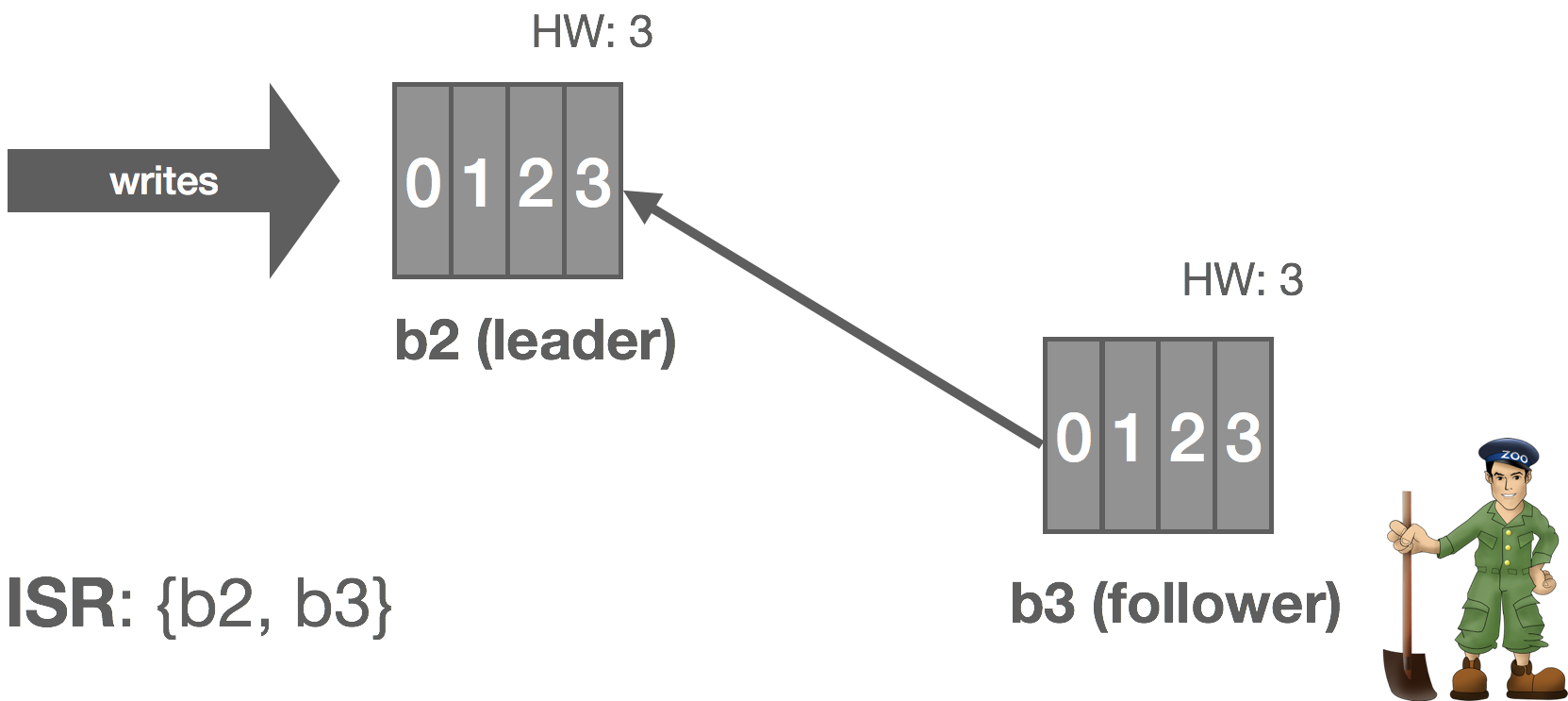
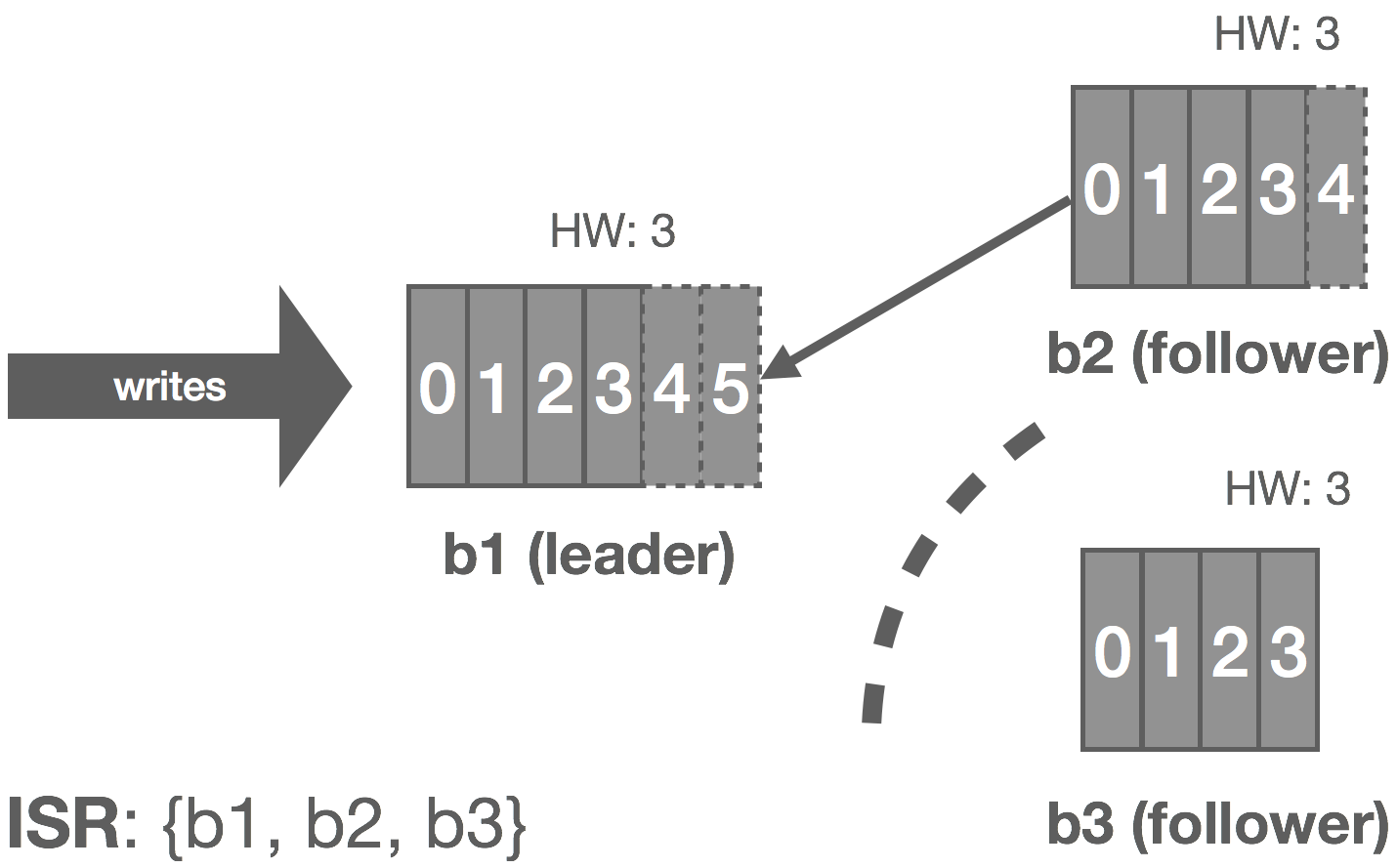
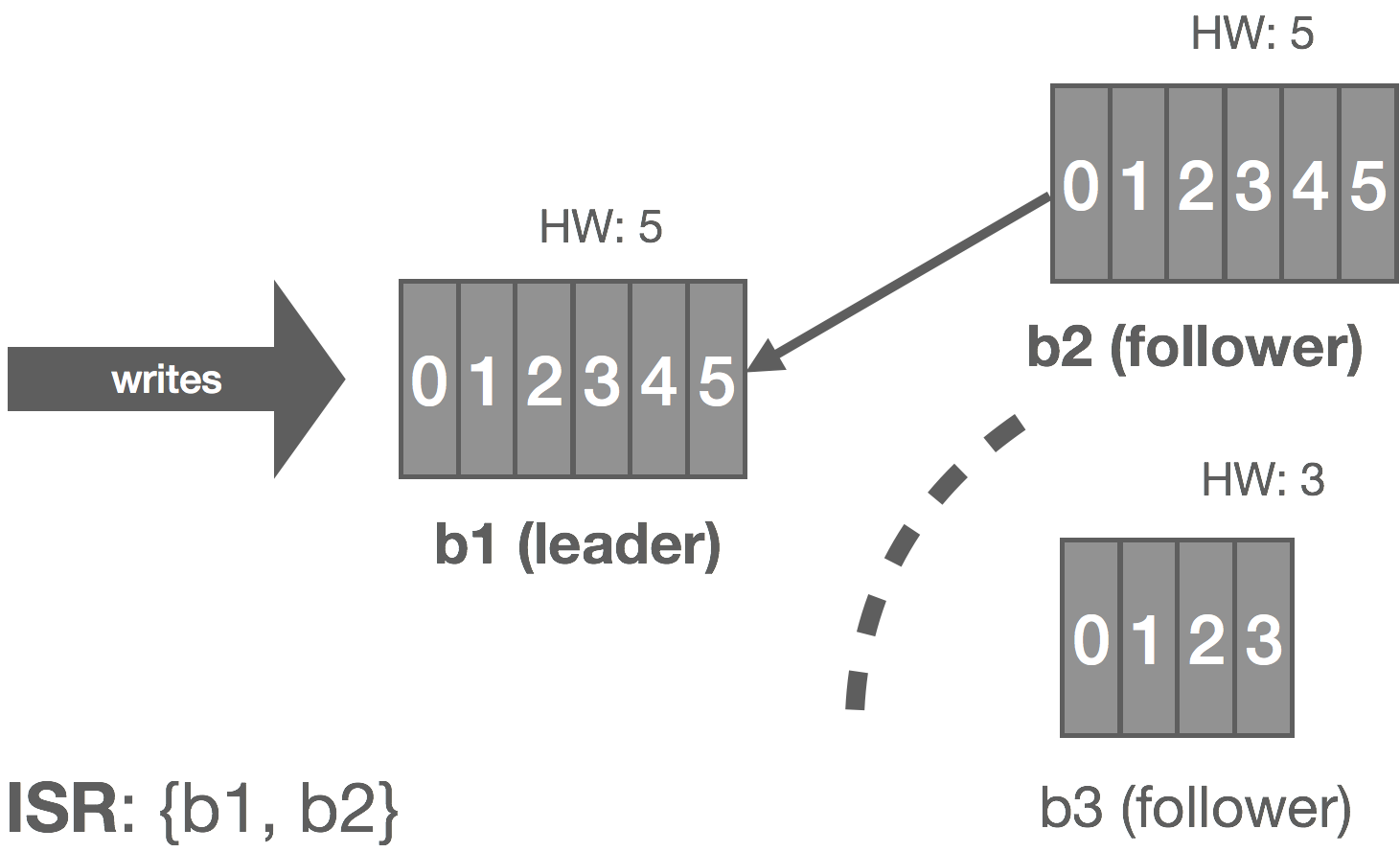
When a failed replica is restarted, it recovers the latest HW from stable storage and truncates its log up to the HW. This removes any potentially uncommitted messages in the log. The replica then begins fetching messages from the leader starting at the HW. Once the replica has caught up, it’s added back into the ISR and the system resumes its fully replicated state.
If the metadata leader fails, Raft will handle electing a new leader. The metadata Raft group stores the leader and ISR for every stream, so failover of the metadata leader is not a problem.
There are a few other corner cases and nuances to handle, but this covers replication in broad strokes. We also haven’t discussed how to implement failure detection (Kafka uses ZooKeeper for this), but we won’t prescribe that here.
Wrapping Up
This concludes our series on building a distributed log that is fast, highly available, and scalable. In part one, we introduced the log abstraction and talked about the storage mechanics behind it. In part two, we covered high availability and data replication. In part three, we we discussed scaling message delivery. In part four, we looked at some trade-offs and lessons learned. Lastly, in part five, we outlined the design for a new log-based system that draws from the previous entries in the series.
The goal of this series was to learn a bit about the internals of a log abstraction, to learn how it can achieve the three priorities described earlier, and to learn some applied distributed systems theory. Hopefully you found it useful or, at the very least, interesting.
If you or your company are looking for help with system architecture, performance, or scalability, contact Real Kinetic.
Follow @tyler_treat