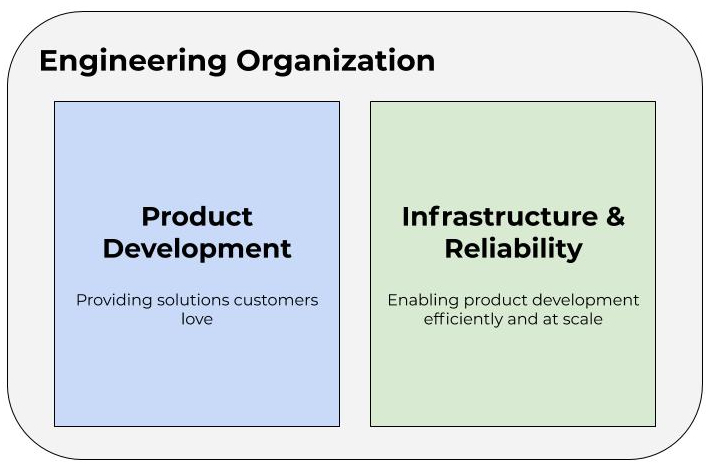
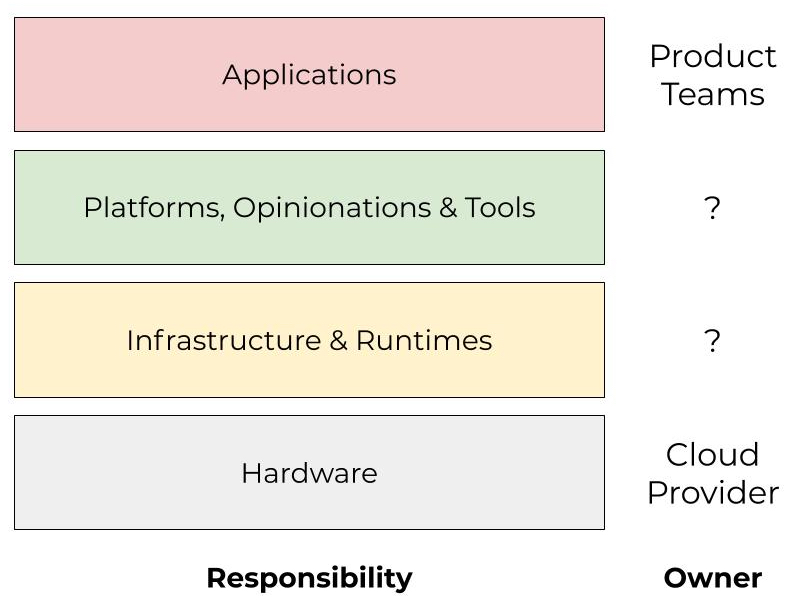
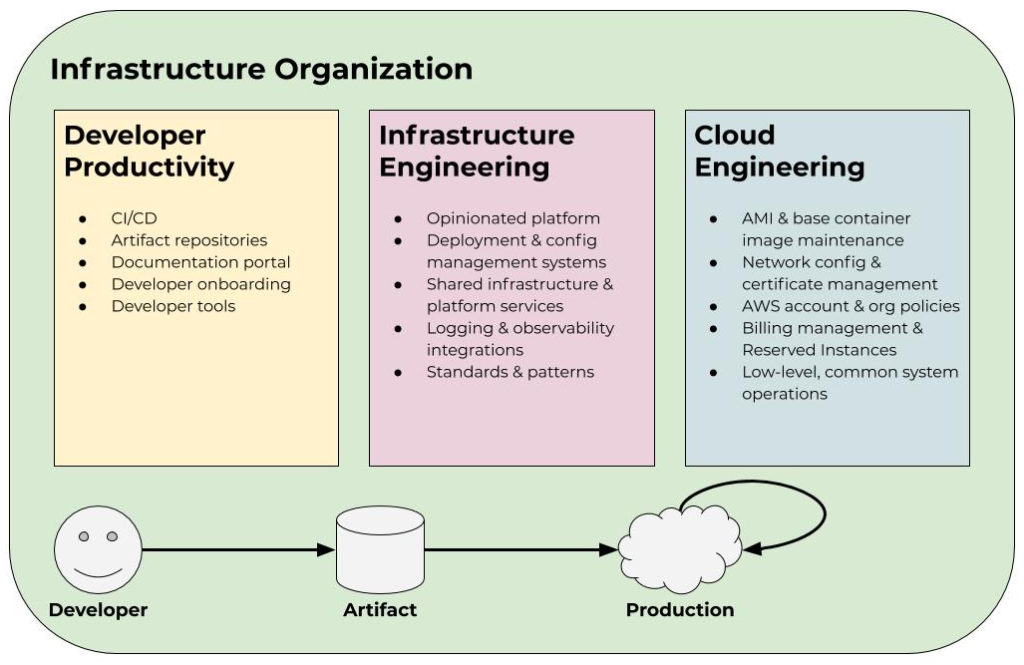
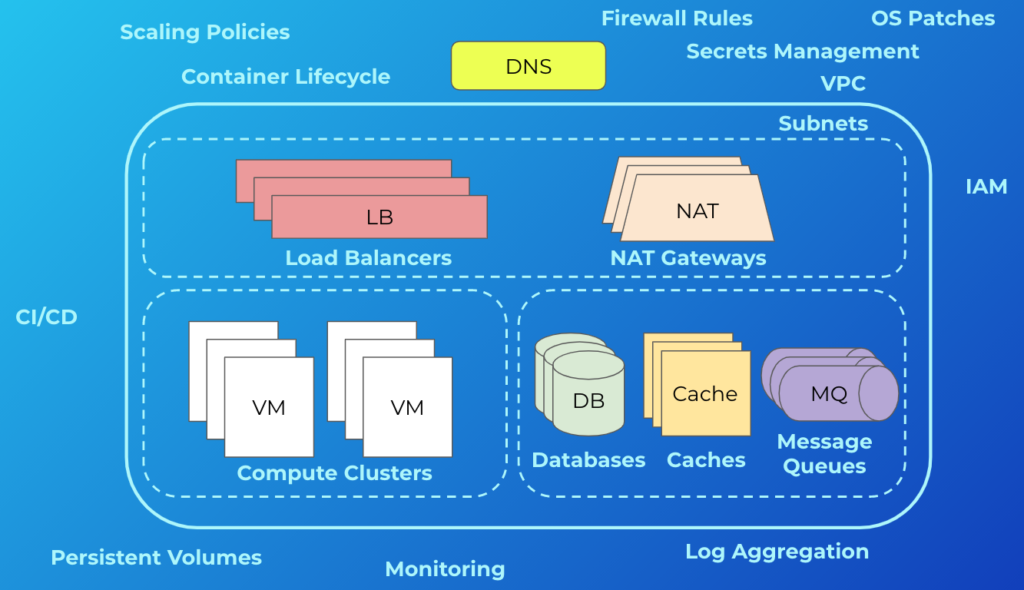
I like to be prepared in meetings. In some ways it’s probably an innate part of my personality, but it also became more important to me as my role has changed throughout my career. In particular, the first time I became an engineering manager is when I started to become a more diligent notetaker and meeting preparer. I think this is largely because my job shifted from being output-centric to more people- and meeting-centric. I still took notes and prepared when I was a software engineer, but it was for a very different context and purpose. As an engineer, my work centered around code output. As a manager, my work instead centered around coordinating, following up, and supporting my team. If you’ve never worked as a manager before, this probably just sounds like paper-pushing, but it’s actually a lot of work—and important! The work product is just different from that of an individual contributor.
When I became a manager, I began taking meeting notes in a small Moleskine notebook. For every meeting, I’d write down the meeting name and the date. I would try to jot down salient points or context, questions, things I wanted to follow up on, or action items I needed to do or delegate. As you can see below, it’s messy. Really messy. It never felt like a particularly good solution. It was hard to find things, hard to pluck out the important action items or follow-ups, hard to even remember who was in a meeting without cross-referencing my calendar. Not to mention my terrible handwriting meant even just reading my own notes was difficult.

An interesting thing about the human brain is that it’s inherently selfish—that is, it’s really good at remembering things that are important to us. The things that are top of mind are probably not things I need to actually write down to remember. But most managers are likely getting pulled in a lot of different directions with a lot of different asks that are all competing for those limited brain cycles. Really good managers seem to have a special knack for juggling all of these things. It’s also why you often hear managers talk about how tiring their job is even though it seems like all they do is go to meetings!
The hard truth about my note-taking system is that I would take a lot of notes, write a lot of action items, and feel really productive in my meetings. Then I would proceed to never look at those notes again. Partly because of the chaos of meeting-packed days week after week, but also because it’s just hard to derive value from notes. Countless times a topic or question would come up in a discussion where I knew I had notes from a previous meeting about it, but it was just impossible to actually find anything in a notebook full of hastily scribbled notes. And by the time you find it, the conversation has moved on. You know how people say your new car loses its value the moment you drive off the lot? Your meeting notes lose value the moment you finish writing them.
This leads to another interesting thing about the human brain—it’s pretty good at organizing memories around time and people. “I remember talking to Joe about managing our cloud costs last week in our weekly cloud strategy meeting”—that sort of thing. And while my notebook provided a chronological ordering of my meeting notes, it wasn’t really conducive to recalling important information quickly or managing my to-do list.
A software engineer’s job often involves coordinating across different software systems, but their to-do list likely consists of things along the lines of “do X.” This is why tools like Jira or Asana exist, to manage the backlog of X’s that need to be done and provide visibility for the people coordinating those X’s.
A manager’s job involves coordinating across a different kind of system—people. A manager’s to-do list is going to consist mostly of things like “talk to Y about Z.” Again, the work product is different. It’s about making sure there is alignment and lines of communication between various people or teams. Your work shifts from being a do-er to a delegate-er and communicator. This kind of work is not managed in Jira or displayed in a Gantt chart. It’s often not managed anywhere except perhaps scribbled in the depths of a Moleskine notebook or tucked away in the corner of a meeting-fatigued brain.
Nevertheless, I carried on with my note-taking system of questionable value, even after transitioning back to an individual contributor role. It wasn’t until I started consulting that I had a realization. With consulting, I work with a lot of different people across a lot of different projects across a lot of different clients. The type of consulting we do at Real Kinetic is very discussional in nature. While we have deliverables, most of our work product is in the form of discussion, guidance, recommendations, coaching, and helping organizations with their own communication challenges. It’s not work that can be managed in a traditional task-management system. Instead, it’s much like the manager’s work of connecting threads of conversation across meetings and people and juggling lots of asks from clients.
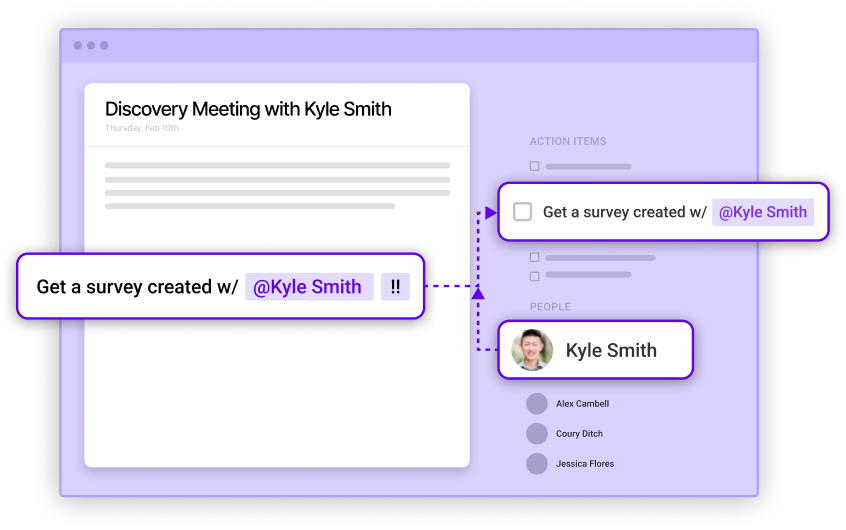
For example, in a meeting with John I might realize we need to connect with Rachel to talk about strategies for improving development velocity. Sure, you could maybe put “Talk to Rachel about dev velocity” into a Trello card or a to-do list app but in doing so it loses the surrounding context. And for a role that is more discussion-oriented than task-oriented, the context is important. Not only that, but tools like Trello or Todoist are just not really designed for this purpose. They are meant more for the do-ers, not the delegate-ers or communicators. They are clunky to use for someone whose job consists mostly of being in meetings and talking to people day in and day out. This is the challenge with productivity apps—most of them are centered around task management and task collaboration. And actual note-taking apps like Evernote are definitely not designed to solve this because they are intended to replace my Moleskine notebook filled with notes I will never look at again.
Now, coming back to my realization: I realized that my meeting notes were not valuable in and of themselves. Rather, they were the medium for my meeting-centric work management. Unfortunately, my notebook was not a great solution, nor was Evernote, nor Google Docs.
What I was really looking for was a sort of to-do list oriented around people and meetings and driven from my meeting notes. Not something centered around task management or collaboration or notes as being anything other than incidental to the process. Instead, I was looking for a tool that could synthesize my notes into something valuable and actionable for me. And I never found it, which is why we ended up creating Witful.
The idea behind Witful is a productivity app for the people whose jobs revolve around, well, people. It turns your meeting notes into something much more valuable. Now, I can take my meeting notes similar to how I used to, but rather than important items falling by the wayside, those items are surfaced to me. Witful tells me if I need to prepare for an upcoming meeting, if there are takeaways from a meeting I need to follow up on, or action items I need to address. And much like the way our brain organizes information, Witful indexes all of my meeting-related content around my meetings, the people in those meetings, and time, making it easy to quickly recall information.
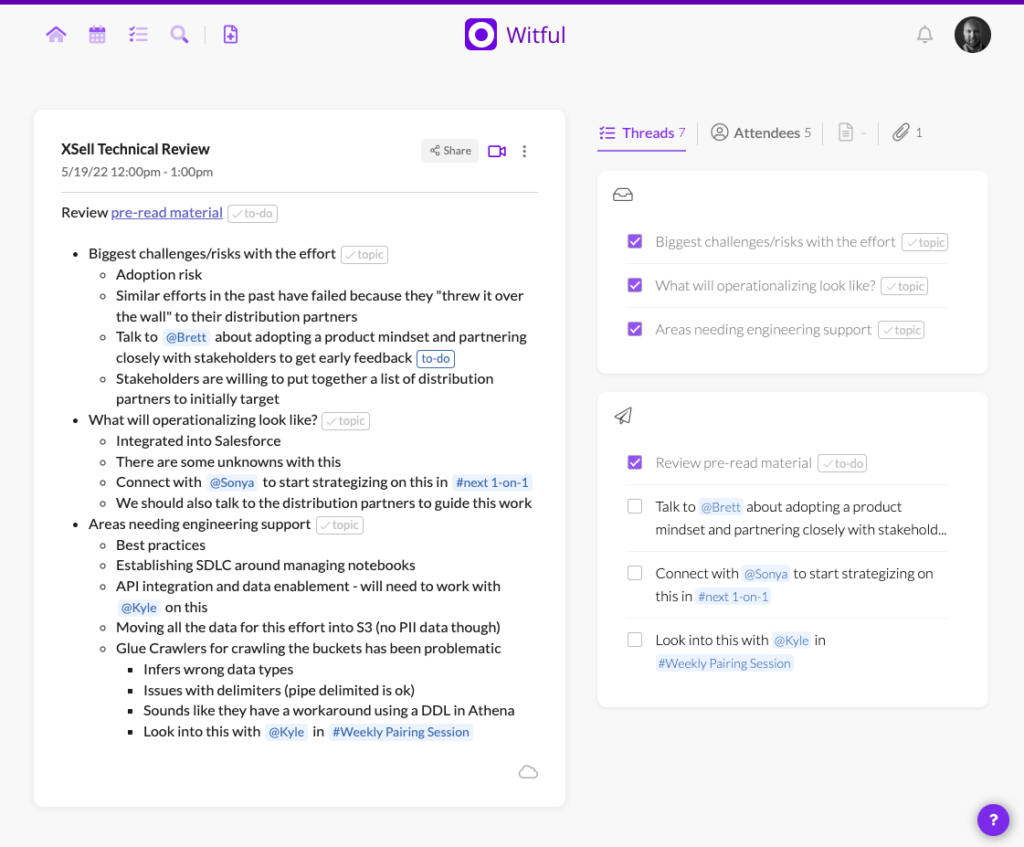
Witful has not radically altered the way I approach meetings. Instead, what it’s done is augmented my previous workflow. It gives me a central place for all my meeting notes, much like the Moleskine notebook did, except it lets me extract much more value from those notes. This has helped me with my consulting work because it has given me the same uncanny knack for juggling lots of things that those really good managers I’ve worked with seem to have. If you’re not a meeting note-taker, Witful might not be for you. If you are and your current system has never felt quite right, you’d like to get more value out of your notes, or you’re looking for a meeting-centric work management system, you should give it a shot.
Follow @tyler_treat