AWS Glue is a managed service for building ETL (Extract-Transform-Load) jobs. It’s a useful tool for implementing analytics pipelines in AWS without having to manage server infrastructure. Jobs are implemented using Apache Spark and, with the help of Development Endpoints, can be built using Jupyter notebooks. This makes it reasonably easy to write ETL processes in an interactive, iterative fashion. Once finished, the Jupyter notebook is converted into a Python script, uploaded to S3, and then run as a Glue job.
There are a number of steps involved in doing this, so it can be worthwhile to automate the process into a CI/CD pipeline. In this post, I’ll show you how you can build an automated pipeline using GitHub Actions to do continuous deployment of Glue jobs built on PySpark and Jupyter notebooks. The full code for this demo is available on GitHub.
The Abstract Workflow
First, I’m going to assume you already have a notebook for which you’d like to set up continuous deployment. If you don’t, you can take a look at my example, but keep in mind you’ll need to have the appropriate data sources and connections set up in Glue for it to work. This post won’t be focusing on the ETL script itself but rather the build and deployment pipeline for it.
I recommend treating your Jupyter notebooks as the “source code” for your ETL jobs and treating the resulting Python script as the “build artifact.” Though this can present challenges for diffing, I find providing the notebook from which the code was derived makes the development process easier, particularly when collaborating with other developers. Additionally, GitHub has good support for rendering Jupyter notebooks, and there is tooling available for diffing notebooks, such as nbdime.
With that in mind, the general flow of our deployment pipeline looks something like this:
- Upon new commits to master, generate a Python script from the Jupyter notebook.
- Copy the generated Python script to an S3 bucket.
- Update a Glue job to use the new script.
You might choose to run some unit or integration tests for your script as well, but I’ve omitted this for brevity.
The Implementation
As I mentioned earlier, I’m going to use GitHub Actions to implement my CI/CD pipeline, but you could just as well use another tool or service to implement it. Actions makes it easy to automate workflows and it’s built right into GitHub. If you’re already familiar with it, some of this will be review.
In our notebook repository, we’ll create a .github/workflows directory. This is where GitHub Actions looks for workflows to run. Inside that directory, we’ll create a main.yml file for defining our CI/CD workflow.
First, we need to give our workflow a name. Our pipeline will simply consist of two jobs, one for producing the Python script and another for deploying it, so I’ll name the workflow “build-and-deploy.”
name: build-and-deploy
Next, we’ll configure when the workflow runs. This could be on push to a branch, when a pull request is created, on release, or a number of other events. In our case, we’ll just run it on pushes to the master branch.
on: push: branches: [ master ]
Now we’re ready to define our “build” job. We will use a tool called nbconvert to convert our .ipynb notebook file into an executable Python script. This means our build job will have some setup. Specifically, we’ll need to install Python and then install nbconvert using Python’s pip. Before we define our job, we need to add the “jobs” section to our workflow file:
# A workflow run is made up of one or more jobs that can run # sequentially or in parallel. jobs:
Here we define the jobs that we want our workflow to run as well as their order. Our build job looks like the following:
build: runs-on: ubuntu-latest steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your # job can access it - uses: actions/checkout@v2 - name: Set up Python 3.8 uses: actions/setup-python@v2 with: python-version: '3.8' - name: Install nbconvert run: | python -m pip install --upgrade pip pip install nbconvert - name: Convert notebook run: jupyter nbconvert --to python traffic.ipynb - name: Upload python script uses: actions/upload-artifact@v2 with: name: traffic.py path: traffic.py
The “runs-on” directive determines the base container image used to run our job. In this case, we’re using “ubuntu-latest.” The available base images to use are listed here, or you can create your own self-hosted runners with Docker. After that, we define the steps to run in our job. This consists of first checking out the code in our repository and setting up Python using built-in actions.
Once Python is set up, we pip install nbconvert. We then use nbconvert, which works as a subcommand of Jupyter, to convert our notebook file to a Python file. Note that you’ll need to specify the correct .ipynb file in your repository—mine is called traffic.ipynb. The file produced by nbconvert will have the same name as the notebook file but with the .py extension.
Finally, we upload the generated Python file so that it can be shared between jobs and stored once the workflow completes. This is necessary because we’ll need to access the script from our “deploy” job. It’s also useful because the artifact is now available to view and download from the workflow run, including historical runs.
Now that we have our Python script generated, we need to implement a job to deploy it to AWS. This happens in two steps: upload the script to an S3 bucket and update a Glue job to use the new script. To do this, we’ll need to install the AWS CLI tool and configure credentials in our job. Here is the full deploy job definition, which I’ll talk through below:
deploy:
needs: build
runs-on: ubuntu-latest
steps:
- name: Download python script from build
uses: actions/download-artifact@v2
with:
name: traffic.py
- name: Install AWS CLI
run: |
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
- name: Set up AWS credentials
shell: bash
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
mkdir -p ~/.aws
touch ~/.aws/credentials
echo "[default]
aws_access_key_id = $AWS_ACCESS_KEY_ID
aws_secret_access_key = $AWS_SECRET_ACCESS_KEY" > ~/.aws/credentials
- name: Upload to S3
run: aws s3 cp traffic.py s3://${{secrets.S3_BUCKET}}/traffic_${GITHUB_SHA}.py --region us-east-1
- name: Update Glue job
run: |
aws glue update-job --job-name "Traffic ETL" --job-update \
"Role=AWSGlueServiceRole-TrafficCrawler,Command={Name=glueetl,ScriptLocation=s3://${{secrets.S3_BUCKET}}/traffic_${GITHUB_SHA}.py},Connections={Connections=redshift}" \
--region us-east-1
- name: Cleanup
run: rm -rf ~/.aws
We use “needs: build” to specify that this job depends on the “build” job. This determines the order in which jobs are run. The first step is to download the Python script we generated in the previous job.
Next, we install the AWS CLI using the steps recommended by Amazon. The AWS CLI relies on credentials in order to make API calls, so we need to set those up. For this, we use GitHub’s encrypted secrets which allow you to store sensitive information within your repository or organization. This prevents our credentials from leaking into code or workflow logs. In particular, we’ll use an AWS access key to authenticate the CLI. In our notebook repository, we’ll create two new secrets, AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY, which contain the respective access key tokens. Our workflow then injects these into an ~/.aws/credentials file, which is where the AWS CLI looks for credentials.
With our credentials set up, we can now use the CLI to make API calls to AWS. The first thing we need to do is copy the Python script to an S3 bucket. In the workflow above, I’ve parameterized this using a secret called S3_BUCKET, but you could also just hardcode this or parameterize it using a configuration file. This bucket acts as a staging directory for our Glue scripts. You’ll also notice that I append the Git commit SHA to the name of the file uploaded to S3. This way, you’ll know exactly what version of the code the script contains and the bucket will retain a history of each script. This is useful when you need to debug a job or revert to a previous version.
Once the script is uploaded, we need to update the Glue job. This requires the job to be already bootstrapped in Glue, but you could modify the workflow to update the job or create it if it doesn’t yet exist. For simplicity, we’ll just assume the job is already created. Our update command specifies the name of the job to update and a long –job-update string argument that looks like the following:
Role=AWSGlueServiceRole-TrafficCrawler,Command={Name=glueetl,ScriptLocation=s3://${{secrets.S3_BUCKET}}/traffic_${GITHUB_SHA}.py},Connections={Connections=redshift}
This configures a few different settings on the job, two of which are required. “Role” sets the IAM role associated with the job. This is important since it determines what resources your Glue job can access. “Command” sets the job command to execute, which is basically whether it’s a Spark ETL job (“glueetl”), Spark Streaming job (“gluestreaming”), or a Python shell job (“pythonshell”). Since we are running a PySpark job, we set the command name to “glueetl” and then specify the script location, which is the path to our newly uploaded script. Lastly, we set a connection used by the job. This isn’t a required parameter but is important if your job accesses any Glue data catalog connections. In my case, that’s a Redshift database connection I’ve created in Glue, so update this accordingly for your job. The Glue update-job command is definitely the most unwieldy part of our workflow, so refer to the documentation for more details.
The last step is to remove the stored credentials file that we created. This step isn’t strictly necessary since the job container is destroyed once the workflow is complete, but in my opinion is a good security hygiene practice.
Now, all that’s left to do is see if it works. To do this, simply commit the workflow file which should kick off the GitHub Action. In the Actions tab of your repository, you should see a running workflow. Upon completion, the build job output should look something like this:
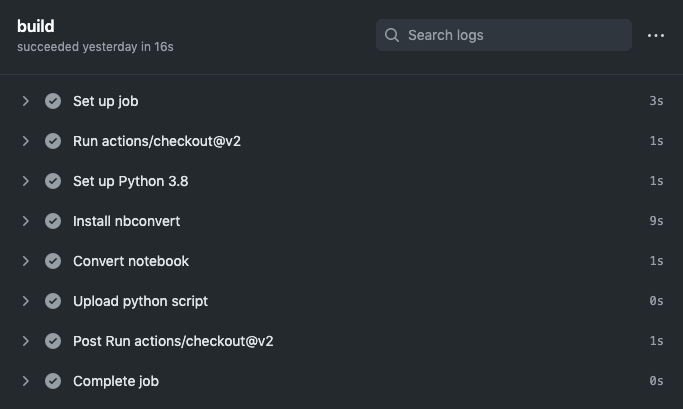
And the deploy output should look something like this:
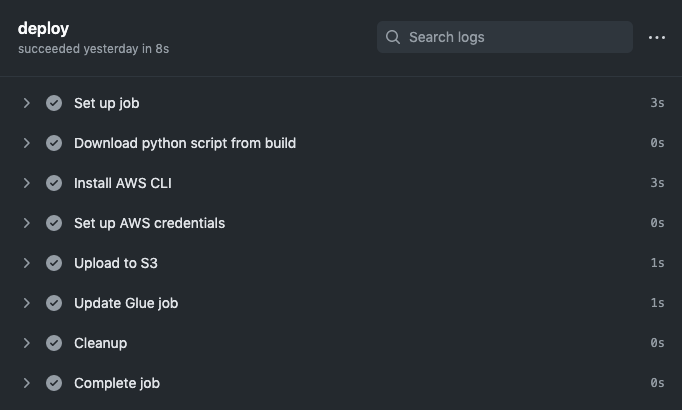
At this point, you should see your Python script in the S3 bucket you configured, and your Glue job should be pointing to the new script. You’ve successfully deployed your Glue job and have automated the process so that each new commit will deploy a new version! If you wanted, you could also extend this workflow to start the new job or create a separate workflow that runs on a set schedule, e.g. to kick off a nightly batch ETL process.
Hopefully you’ve found this useful for automating your own processes around AWS Glue or Jupyter notebooks. GitHub Actions provides a convenient and integrated solution for implementing CI/CD pipelines. With it, we can build a nice development workflow for getting Glue ETL code to production with continuous deployment.
Follow @tyler_treat
Thank you for the great post.
In the post you were focusing on ci/cd for a single job.
How can I do that for more than one?
Or off I updated the source python script would it reflect on the Glue Job?