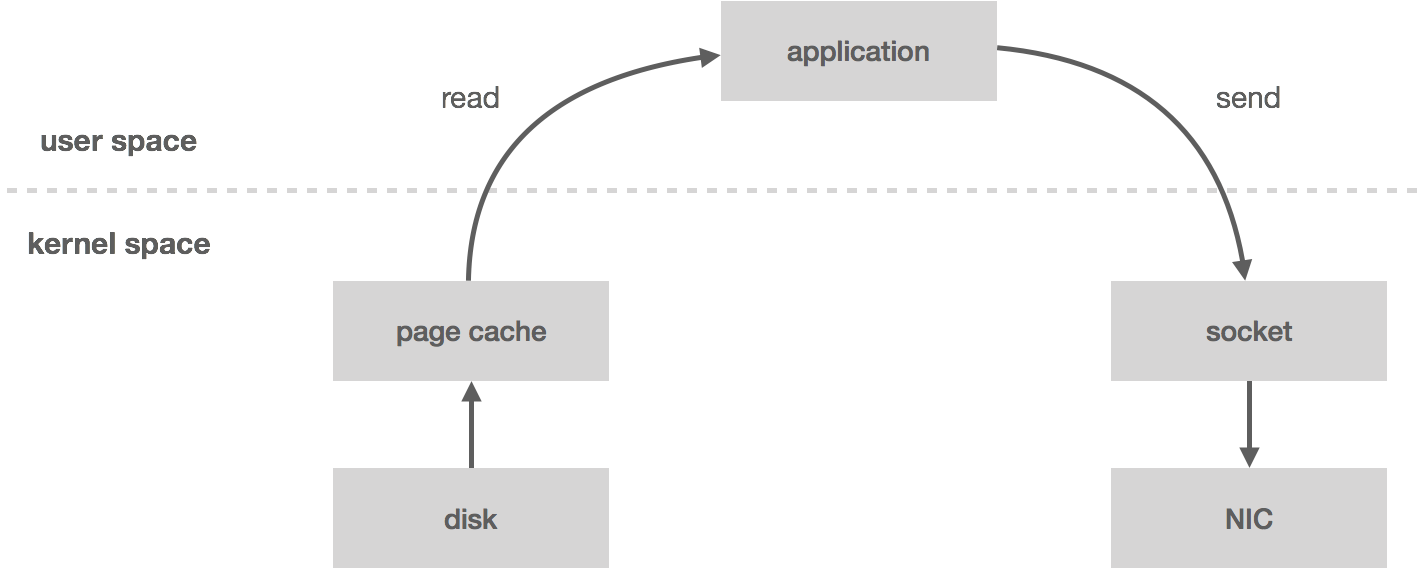
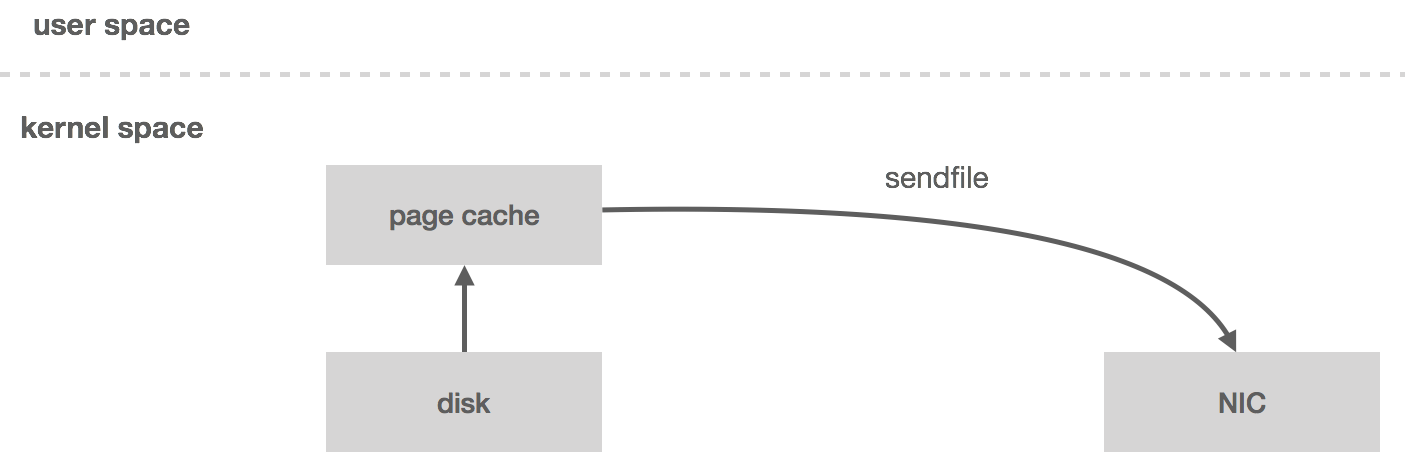
In part two of this series we discussed data replication within the context of a distributed log and how it relates to high availability. Next, we’ll look at what it takes to scale the log such that it can handle non-trivial workloads.
Data Scalability
A key part of scaling any kind of data-intensive system is the ability to partition the data. Partitioning is how we can scale a system linearly, that is to say we can handle more load by adding more nodes. We make the system horizontally scalable.
Kafka was designed this way from the beginning. Topics are partitioned and ordering is only guaranteed within a partition. For example, in an e-commerce application, we might have two topics, purchases and inventory, each with two partitions. These partitions allow us to distribute reads and writes across a set of brokers. In Kafka, the log is actually the partition.
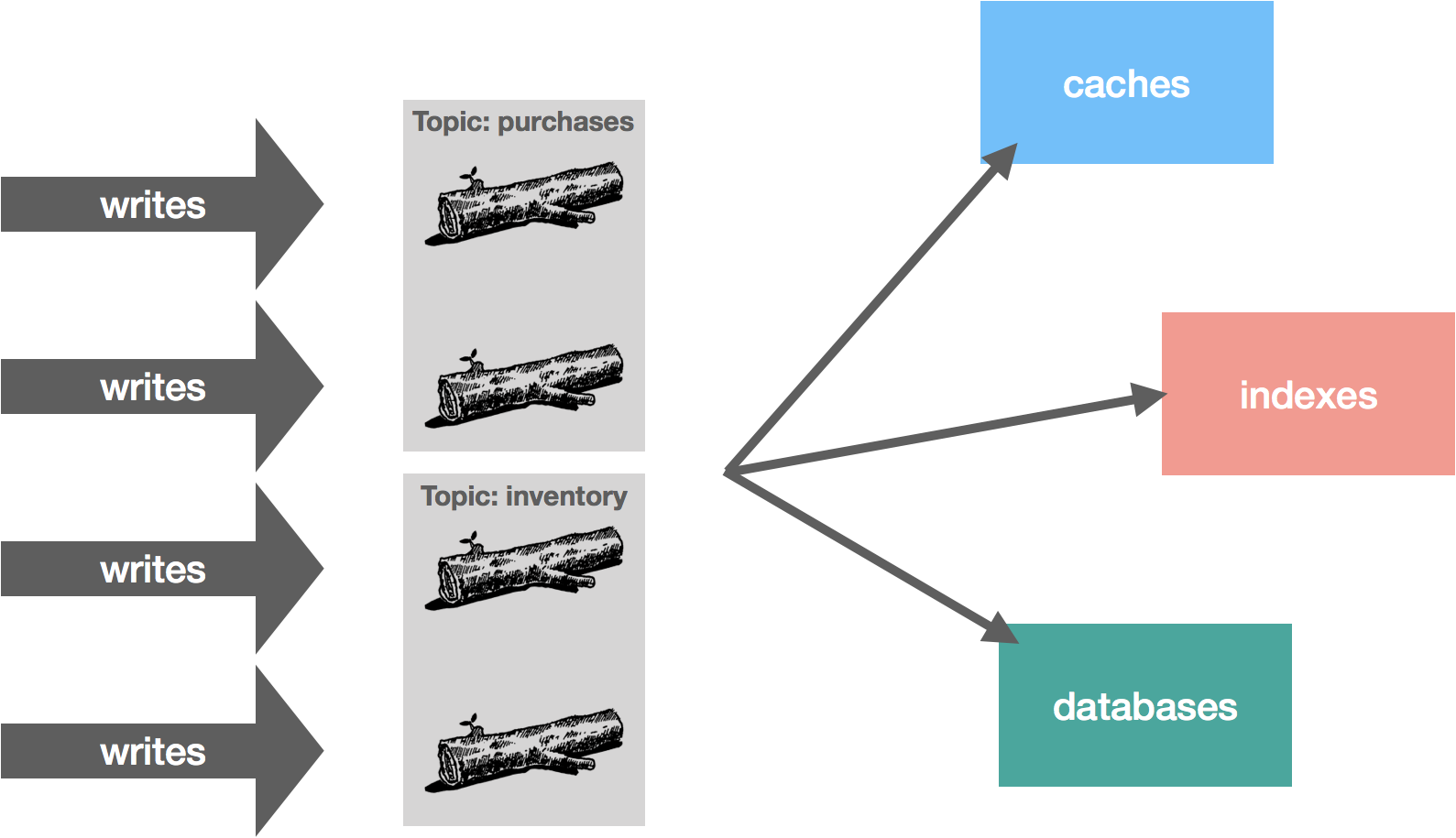
The challenge with this is how we partition the data. We might distribute data using round robin, in effect randomly distributing it. The problem with this is we lose out on ordering, which is an important characteristic of the log. For example, imagine we have add and remove inventory operations. With random partitioning, we might end up with a remove followed by an add getting processed if they’re placed in different partitions. However, if they’re placed in the same partition, we know they will be ordered correctly from the perspective of the publisher.
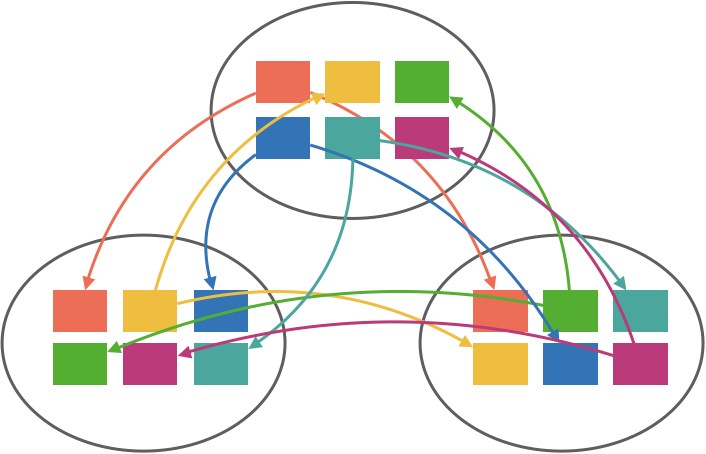
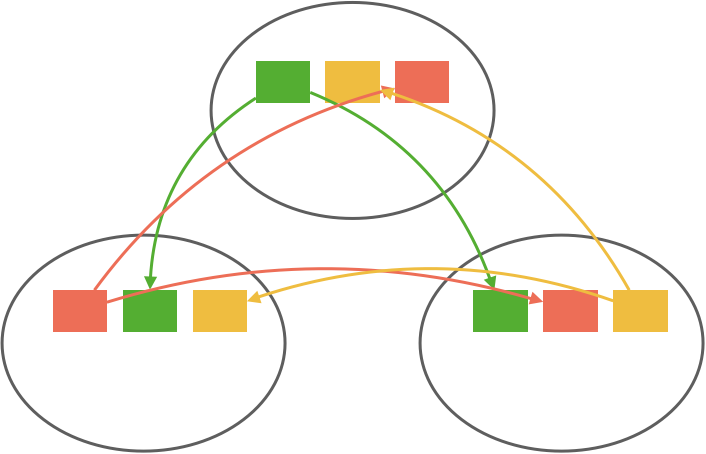
We could also distribute by hashing a key and sending all writes with the same keys to the same partitions or some custom partitioning strategy along these lines. Continuing with our example, we might partition purchases by account name and inventory by SKU. This way, all purchase operations by the same account are ordered, as are all inventory operations pertaining to the same SKU. The diagram below shows a (naive) custom strategy that partitions topics by ranges based on the account and SKU.
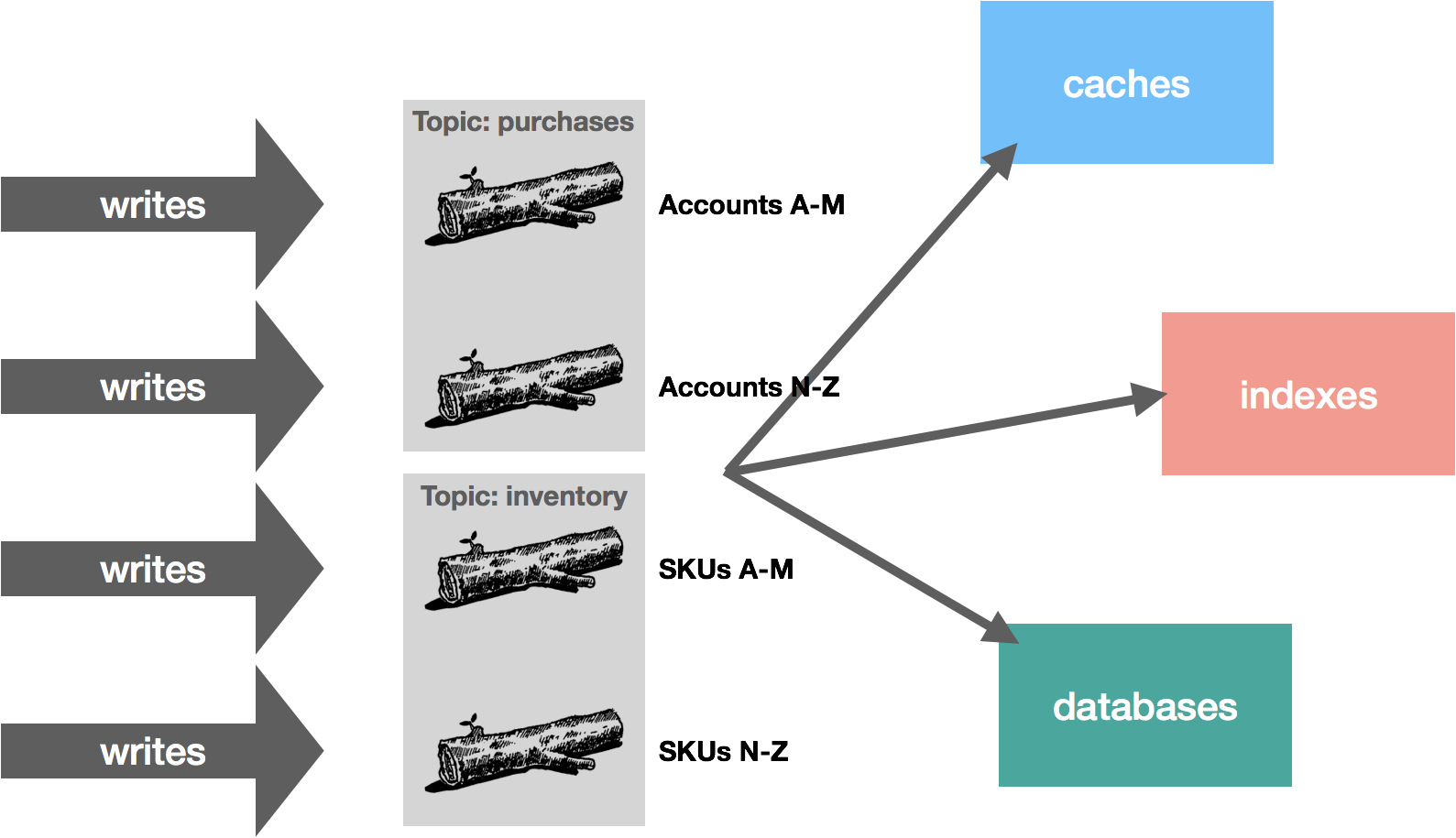
The important point here is that how you partition your data is largely dependent on your application and its usage patterns, but partitioning is a critical part of scalability. It allows you to scale your workload processing by dividing up responsibilities, which in turn, allows you to throw more resources at the problem in a tractable way.
One of NATS Streaming’s shortcomings, in my opinion, is that it doesn’t currently offer a good story around partitioning. Channels are totally ordered, essentially making them the equivalent of a Kafka partition. The workaround is to partition among multiple channels at the application level. To some, this is a benefit because it’s conceptually simpler than Kafka, but Kafka was designed as such because scalability was a key design goal from day one.
Consumer Scalability
One challenge with the log is the problem of high fan-out. Specifically, how do we scale to a large number of consumers? In Kafka and NATS Streaming, reads (and writes) are only served by the leader. Similarly, Amazon Kinesis supports up to only five reads per second per shard (a shard is Kinesis’ equivalent of a partition). Thus, if we have five consumers reading from the same shard, we’ve already hit our fan-out limit. The thought is to partition your workload to increase parallelism and/or daisy chain streams to increase fan-out. But if we are trying to do very high fan-out, e.g. to thousands of IoT devices, neither of these are ideal solutions. Not all use cases may lend themselves to partitioning (though one can argue this is just a sign of poor architecting), and chaining up streams (or in Kafka nomenclature, topics) tends to be kludgey.
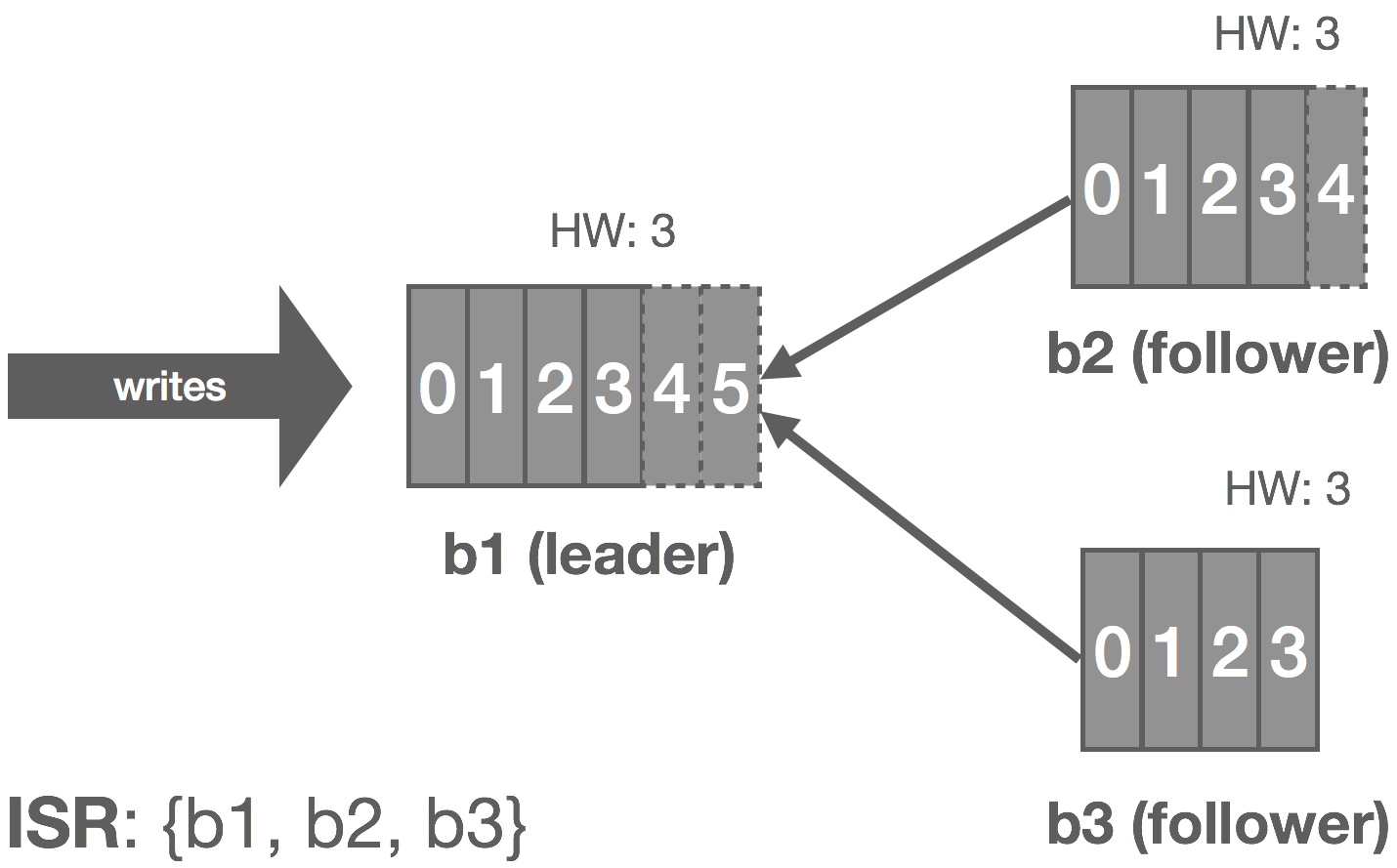
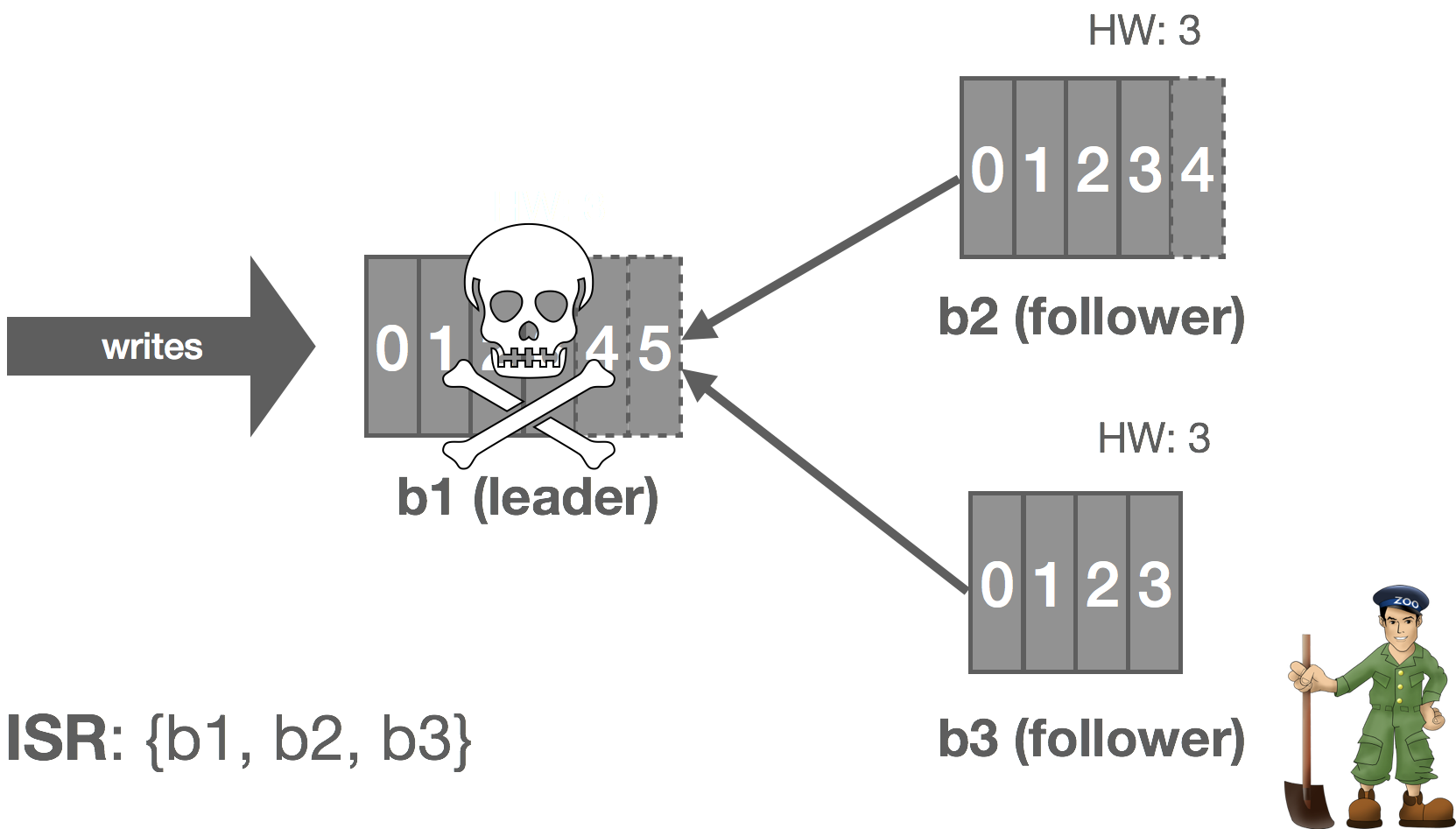
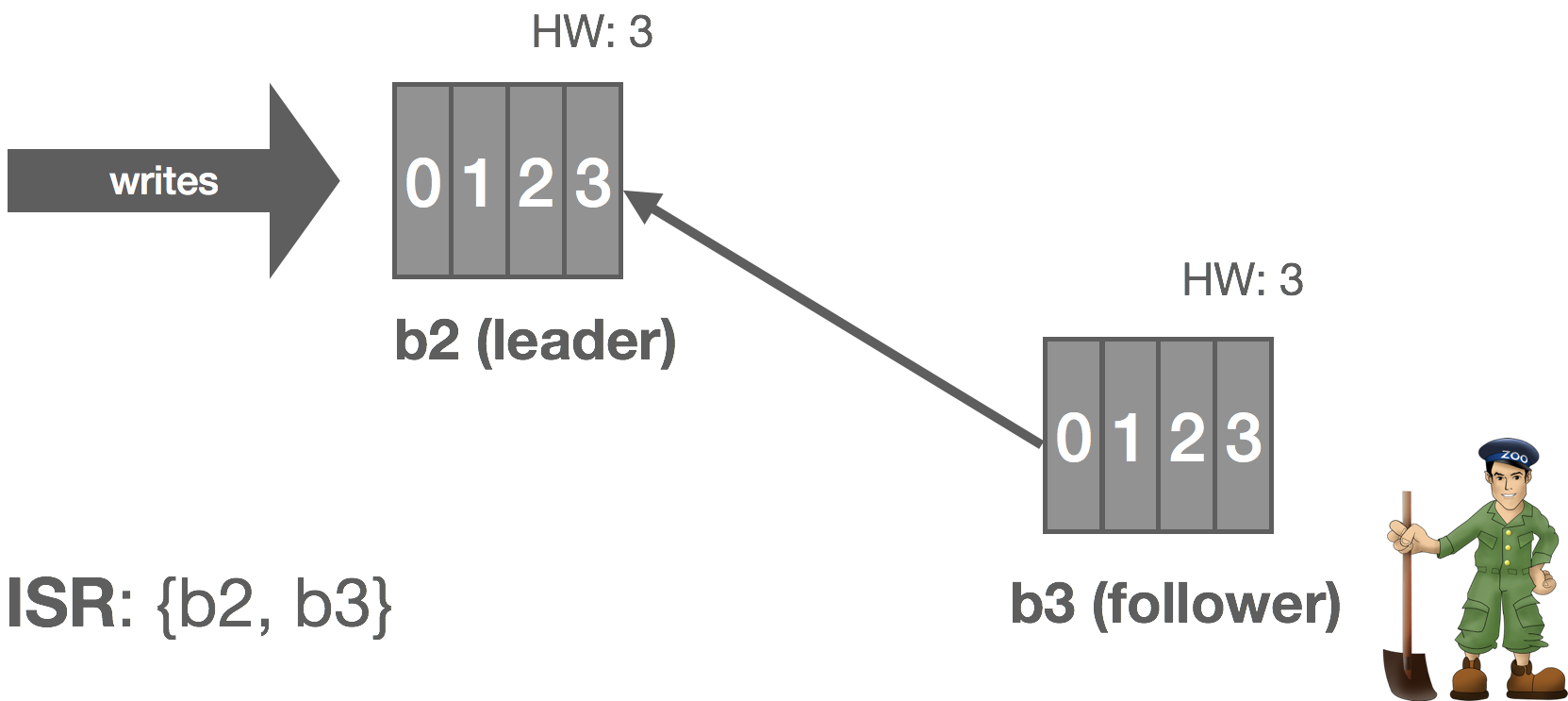
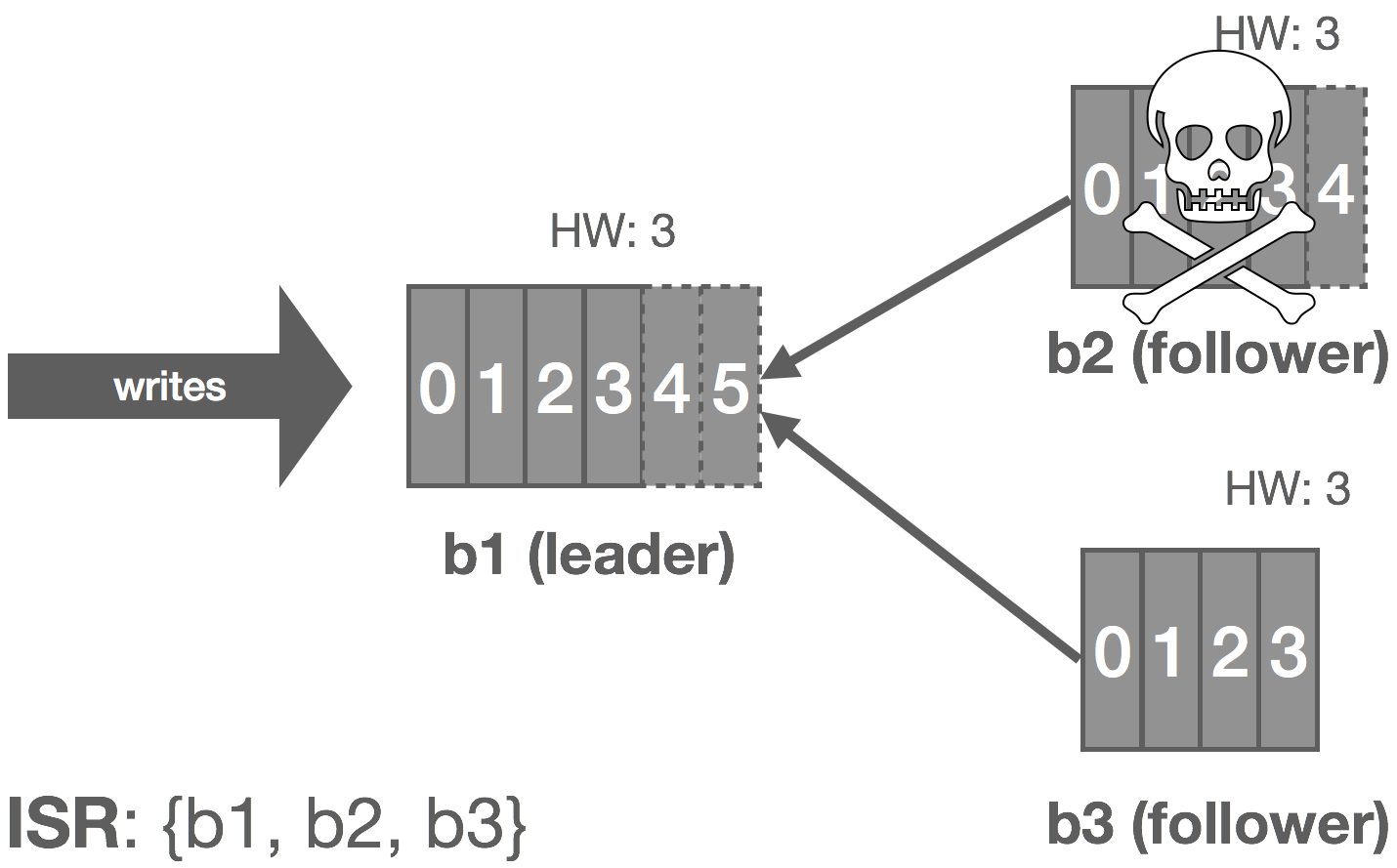
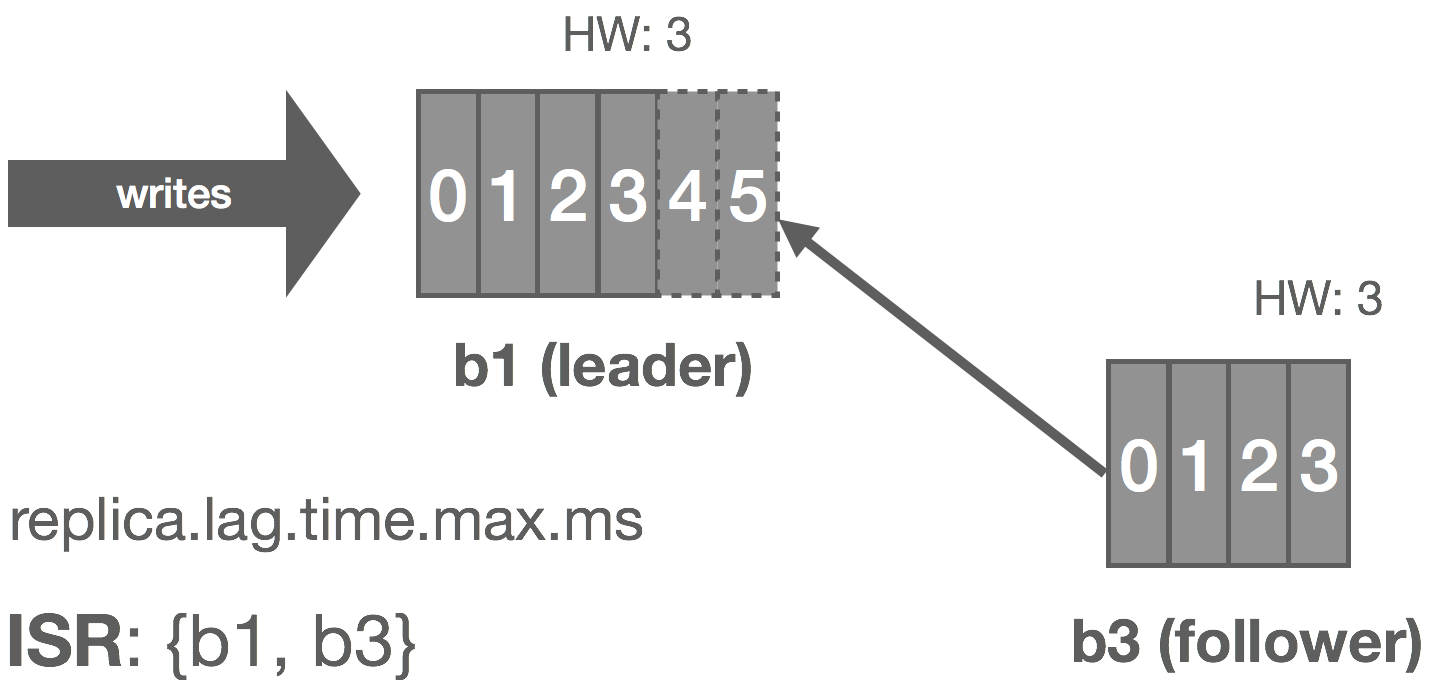
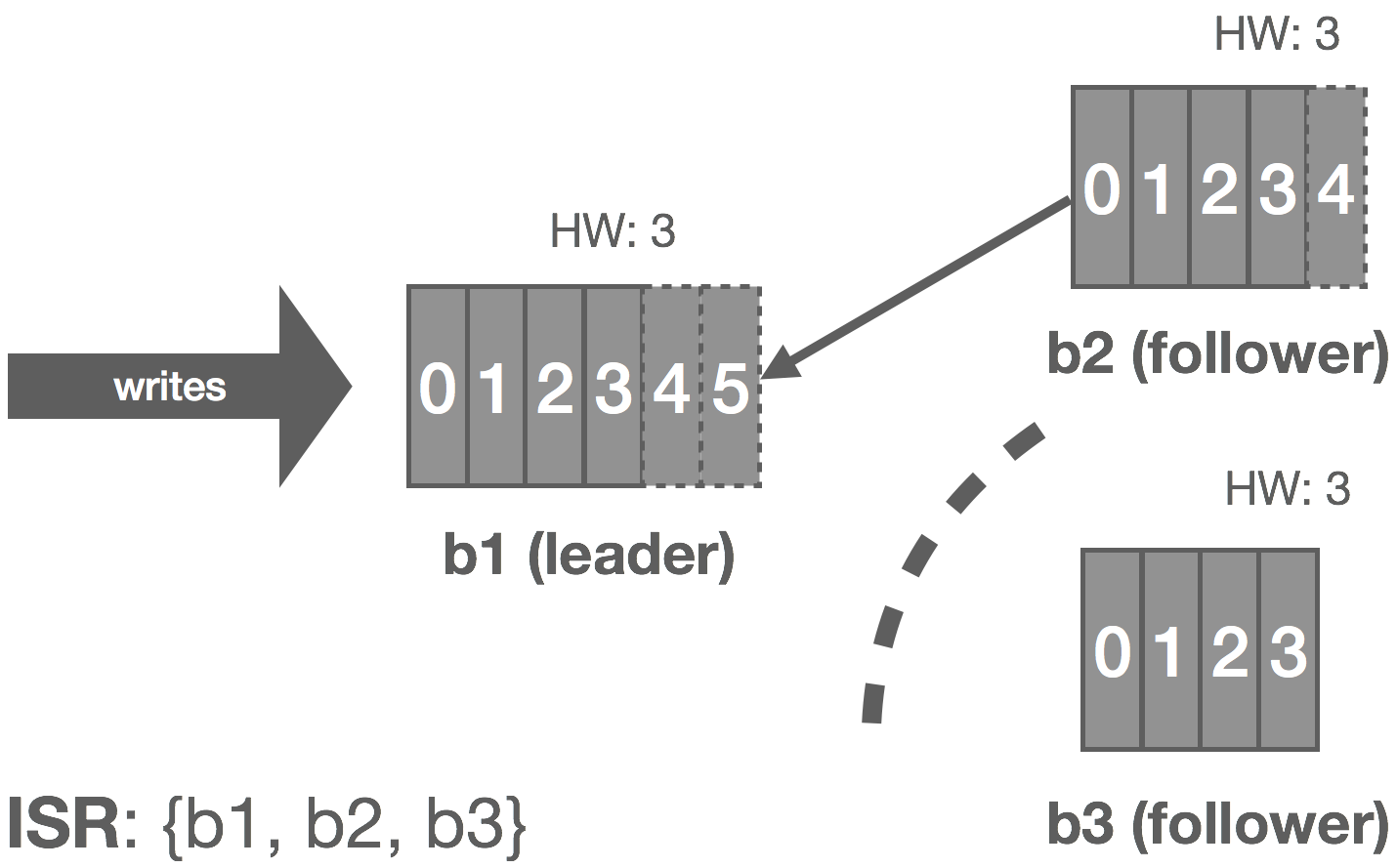
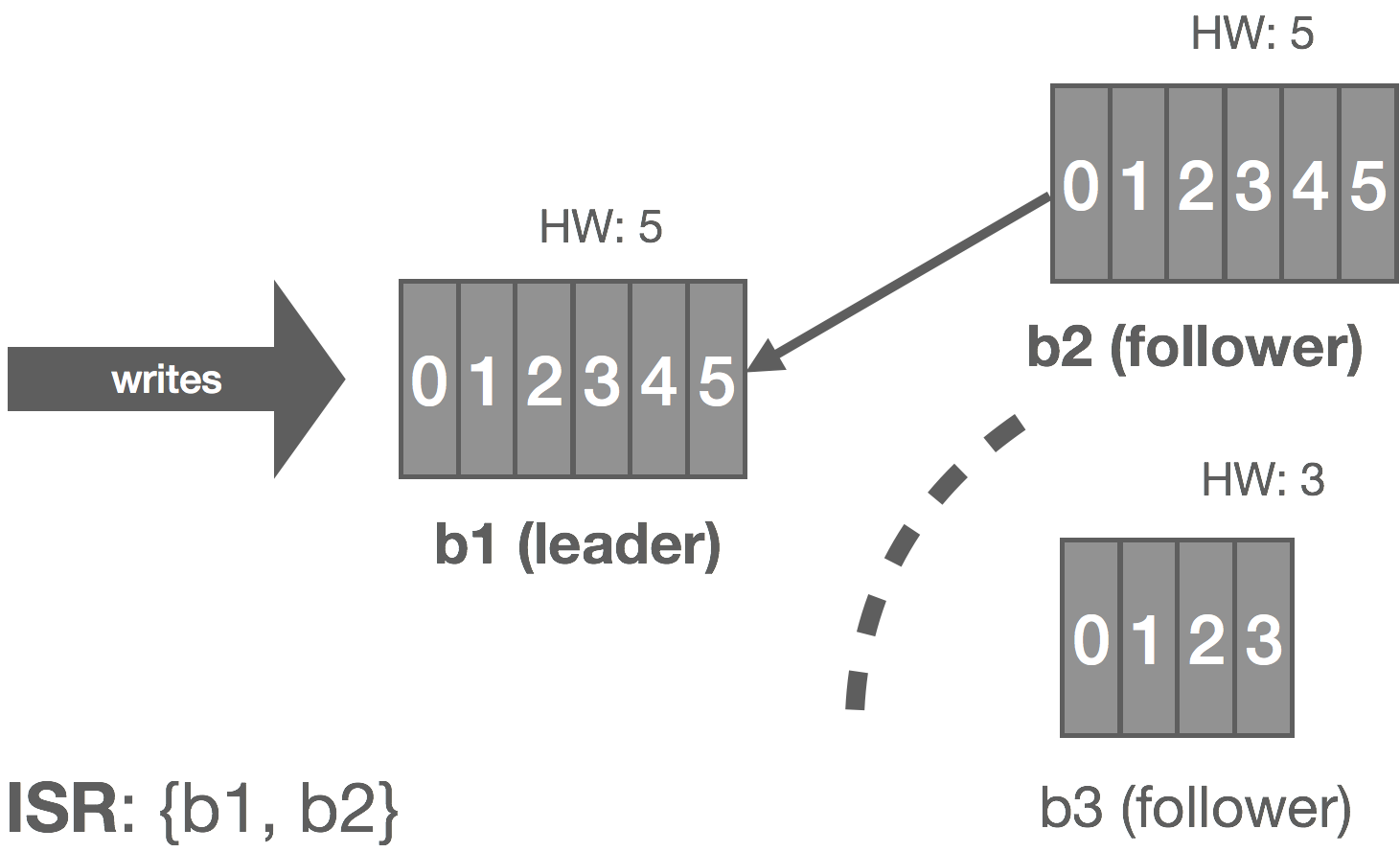
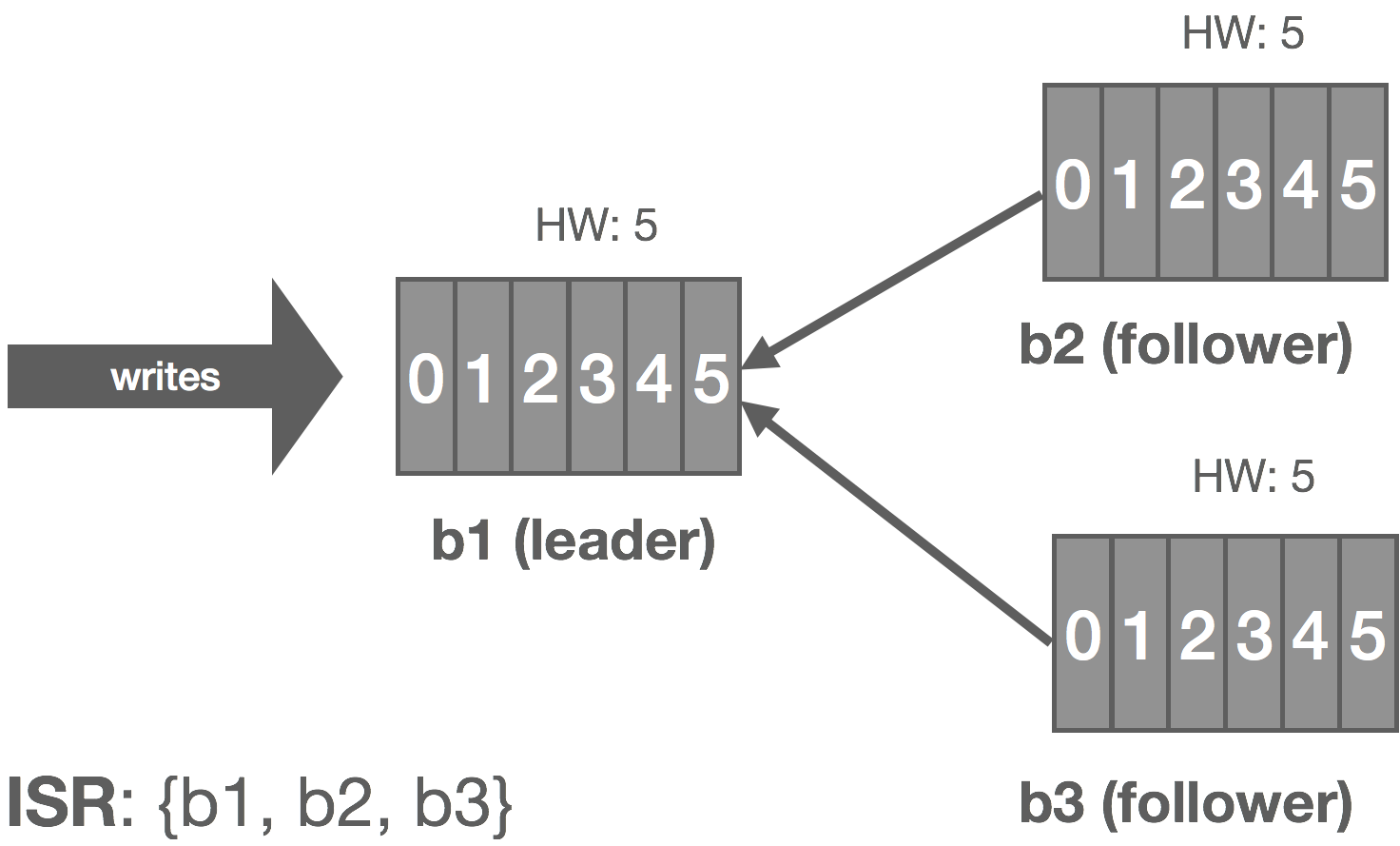
However, we can make the following observation: with an immutable log, there are no stale or phantom reads. Unlike a database, we can loosen our requirements a bit. Whereas a database is typically mutable, with a log, we’re only appending things. From a consumer’s perspective, a replica is either up-to-date with the leader or in the process of catching up, but in either case, if we read all of the records, we should end up in the same state. Immutability, at least in theory, should make it “easy” to scale to a large number of consumers because we don’t have to read from the leader to get correct results (ignoring log compaction and other “mutable” operations), so long as we’re okay with strong eventual consistency with respect to tailing the log.
In NATS Streaming, with Raft, we could simply allow followers to serve reads and scale reads by increasing the size of the cluster, but this would impact performance because the quorum size would also increase. Instead, we can use “non-voters” to act as read replicas and balance consumers among them. These read replicas do not participate in quorum or leader election, they simply receive committed log entries. In effect, this is the daisy chaining of streams mentioned earlier but done implicitly by the system. This is an otherwise common pattern for increasing consumer fan-out in Kinesis but is usually done in an ad hoc, Rube Goldberg-esque fashion. Note that, in the case of NATS Streaming, this isn’t quite as simple as it sounds due to the delivery mechanism used, which we’ll describe next.
Push vs. Pull
In Kafka, consumers pull data from brokers. In NATS Streaming, brokers push data to consumers. Kafka’s documentation describes this design decision in detail. The key factor largely comes down to flow control. With push, flow control needs to be explicit to deal with diverse consumers. Different consumers will consume at different rates, so the broker needs to be aware of this so as not to overwhelm a consumer.
There are obvious advantages and disadvantages to both approaches. With push, it can be a tricky balance to ensure full utilization of the consumer. We might use a backoff protocol like additive increase/multiplicative decrease, widely known for its use in TCP congestion control, to optimize utilization. NATS Streaming, like many other messaging systems, implements flow control by using acks. Upon receiving a message, consumers ack back to the server, and the server tracks the in-flight messages for each consumer. If that number goes above a certain threshold, the server will stop delivery until more acks are received. There is a similar flow-control mechanism between the publisher and the server. The trade-off here is the server needs to do some bookkeeping, which we’ll get to in a bit. With a pull-based system, flow control is implicit. Consumers simply go at their own pace, and the server doesn’t need to track anything. There is much less complexity with this.
Pull-based systems lend themselves to aggressive batching. With push, we must decide whether to send a message immediately or wait to accumulate more messages before sending. This is a decision pertaining to latency versus throughput. Push is often viewed as an optimization for latency, but if we’re tuning for low latency, we send messages one at a time only for them to end up being buffered on the consumer anyway. With pull, the consumer fetches all available messages after its current position in the log, which basically removes the guesswork around tuning batching and latency.
There are API implications with this decision too, particularly from an ergonomics and complexity perspective. Kafka clients tend to be “thick” and have a lot of complexity. That is, they do a lot because the broker is designed to be simple. That’s my guess as to why there are so few native client libraries up to par with the Java client. NATS Streaming clients, on the other hand, are relatively “thin” because the server does more. We end up just pushing the complexity around based on our design decisions, but one can argue that the smart client and dumb server is a more scalable approach. We’ll go into detail on that in the next installment of this series.
Circling back on consumer scalability, the fact that NATS Streaming uses a push-based model means we can’t simply setup read replicas and balance consumers among them. Instead, we would need to partition consumers among the replicas so that each server is responsible for pushing data to a subset of consumers. The increased complexity over pull becomes immediately apparent here.
Bookkeeping
There are two ways to track position in the log: have the server track it for consumers or have consumers track it themselves. Again, there are trade-offs with this, namely between API simplicity, server complexity, performance, and scalability. NATS Streaming tracks subscription positions for consumers. This means consumers can come and go as they like and pick back up where they left off easily. Before NATS Streaming supported clustering, this made a lot of sense because the bookkeeping was all in one server. But with clustering, this data must be replicated just like the message data, which poses a performance challenge.
The alternative is to punt the problem to the consumer. But also keep in mind that consumers might not have access to fast stable storage, such as with an IoT device or ephemeral container. Is there a way we can split the difference?
We can store the offsets themselves directly in the log. As of 0.9, this is what Kafka does. Before that, clients had to manage offsets themselves or store them in ZooKeeper. This forced a dependency on ZooKeeper for clients but also posed a major bottleneck since ZooKeeper is relatively low throughput. But by storing offsets in the log, they are treated just like any other write to a Kafka topic, which scales quite well (offsets are stored in an internal Kafka topic called __consumer_offsets partitioned by consumer group; there is also a special read cache for speeding up the read path).
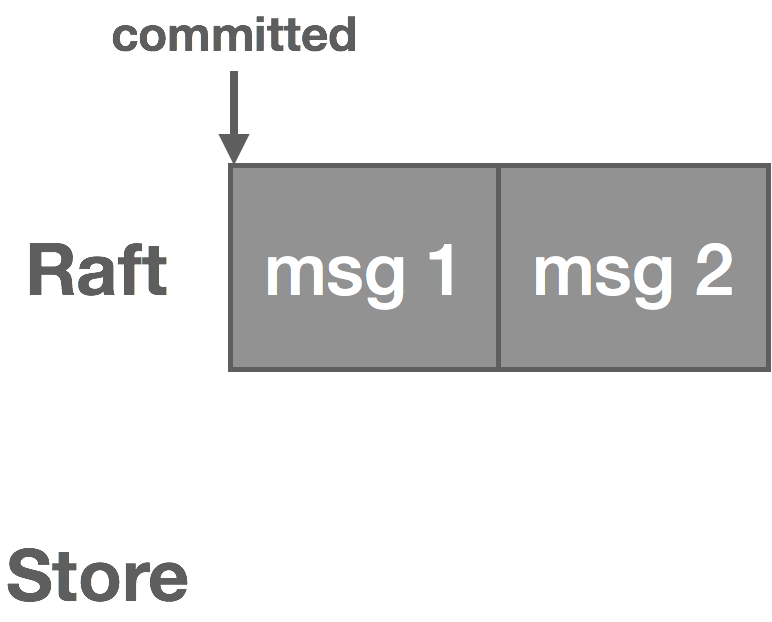
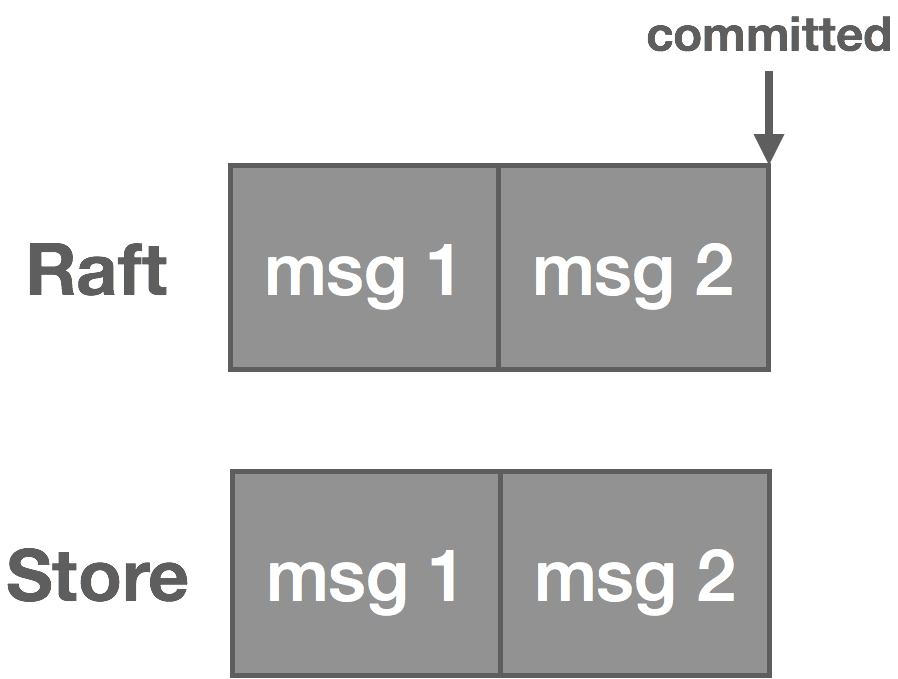
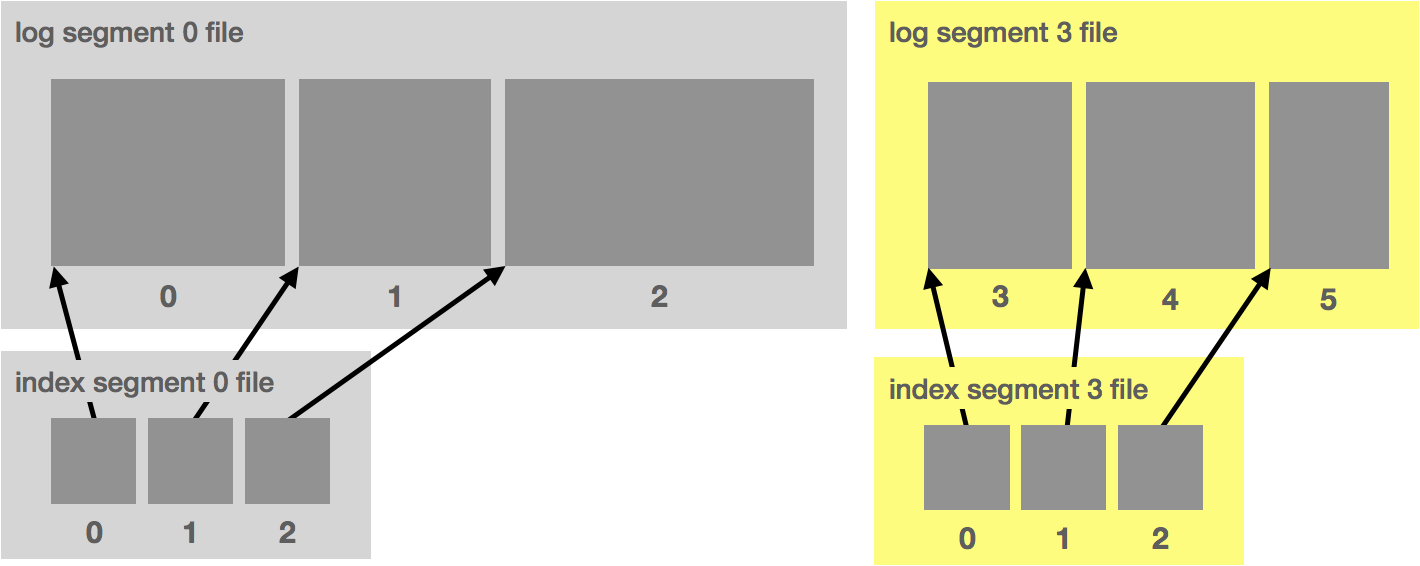
Clients periodically checkpoint their offset to the log. We then use log compaction to retain only the latest offsets. Log compaction works by rewriting the log to retain only the latest message for a given key. On recovery, clients fetch the latest offset from the log. The important part here is we need to structure our keys such that compaction retains the latest offset for each unique consumer. For example, we might structure it as consumer-topic-partition. We end up with something resembling the following, where the message value is the offset:

The above log is uncompacted. Once compacted, it becomes the following:
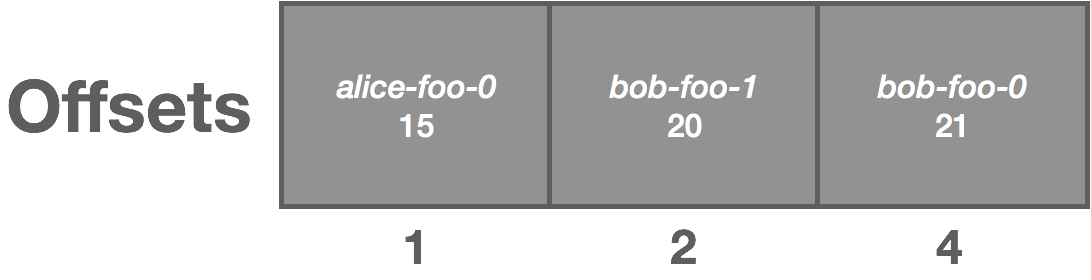
Note that compaction violates some of our previous assumptions around the immutability of the log, but that’s for another discussion.
There are a number of advantages to this approach. We get fault-tolerance and durability due to the fact that our log is already fault-tolerant and durable as designed earlier. We get consistent reads again due to our replication scheme. Unlike ZooKeeper, we get high write throughput. And we reuse existing structures, so there’s less server complexity. We’re just reusing the log, there aren’t really any major new codepaths.
Interestingly, the bookkeeping needed for flow control in push-based systems—such as acks in NATS Streaming—serves much the same purpose as offset tracking in pull-based systems, since it needs to track position. The difference comes when we allow out-of-order processing. If we don’t allow it, then acks are simply a high-water mark that indicate the client is “this far” caught up. The problem with push is we also have to deal with redeliveries, whereas with pull they are implicitly handled by the client. If we do allow out-of-order processing, then we need to track individual, in-flight messages, which is what per-message acks allow us to do. In this case, the system starts to look less like a log and more like a message queue. This makes push even more complicated.
The nice thing about reusing the log to track offsets is it greatly reduces the amount of code and complexity needed. Since NATS Streaming allows out-of-order processing, it uses a separate acking subsystem which otherwise has the same requirements as an offset-tracking subsystem.
In part four of this series, we will discuss some of the key trade-offs involved with implementing a distributed log and some lessons learned while building NATS Streaming.
Follow @tyler_treat