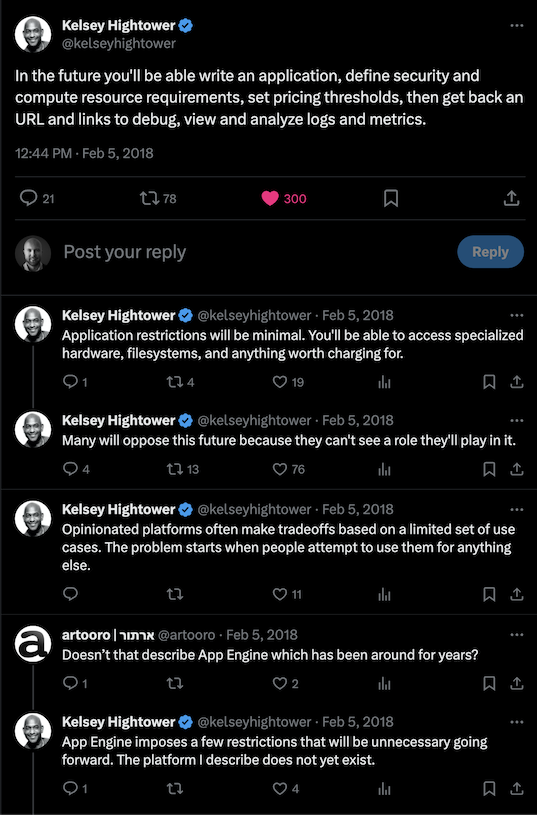
Like most industry jargon, “DevOps” means a lot of things to a lot of different people. While many folks view it as specific to certain tooling or practices, such as CI/CD or Infrastructure as Code (IaC), I’ve always viewed it as an organizational model for how software is built and delivered. In particular, my interpretation is that DevOps is about shifting more responsibilities “left” onto developers, moving away from the more traditional “throw it over the wall” approach to IT operations. No doubt this encompasses tooling or practices like CI/CD and IaC, which are responsibilities that developers now shoulder, perhaps with the support of dev tools, productivity, or enablement teams—some companies just call this the “DevOps” team.
While many organizations still operate with the traditional silos, DevOps has established itself as an industry norm. But as organizations push the boundaries of software development, the limitations of DevOps are becoming increasingly apparent. The problem is that DevOps, in its pursuit of speed and autonomy, often results in chaos and inefficiency. Teams end up reinventing the wheel, creating bespoke solutions for the same problems, and struggling with inconsistent tooling and practices across the organization. The outcome? Technical debt, fragmented processes, and wasted effort. Many of the teams we work with at Real Kinetic spend significantly more time on the “DevOps work” than they do on actual product work.
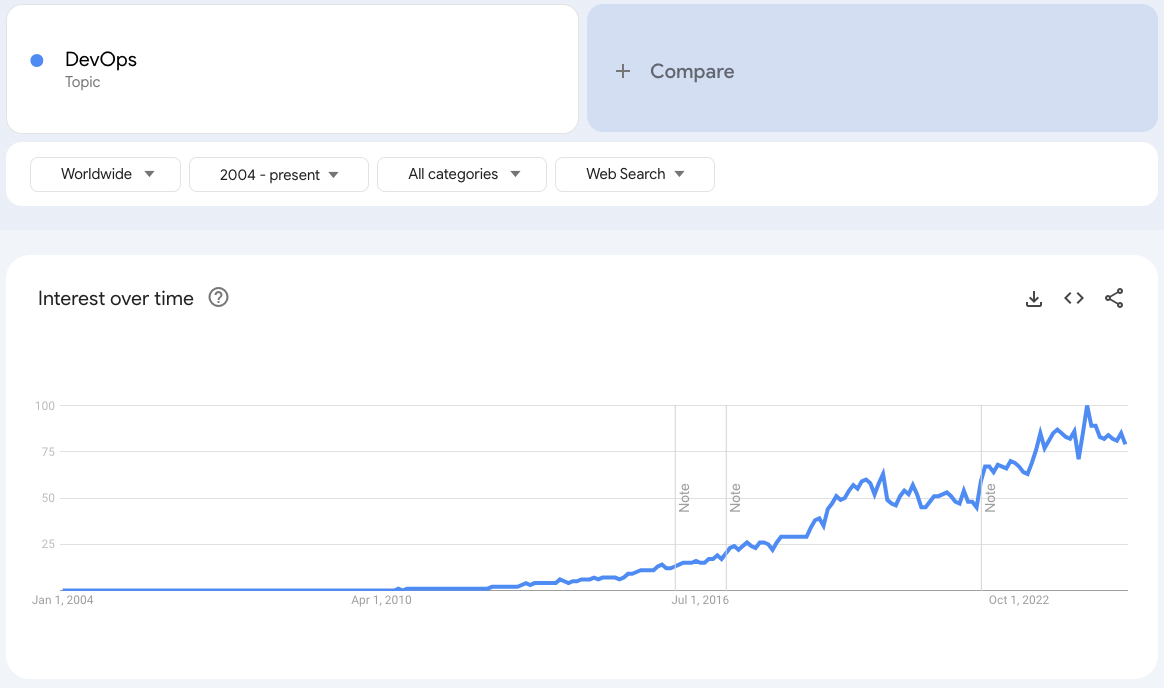
The Rise of Platform Engineering
This is where Platform Engineering comes in. Rather than having each development team own their entire infrastructure stack, platform engineering provides a centralized, productized approach to infrastructure and developer tools. It’s about creating reusable, self-service platforms that development teams can leverage to build, deploy, and scale their applications efficiently. These platforms abstract away the complexities of cloud infrastructure, CI/CD pipelines, and security, enabling developers to focus on writing code rather than managing infrastructure or “glue”.
Platform engineering brings structure to the chaos of DevOps by creating a standardized, cohesive platform that empowers development teams while maintaining best practices and governance. It’s a solution to the growing complexity and sprawl that comes with scaling software delivery and scaling DevOps. Platform engineering is very much in its infancy as DevOps was circa 2012, but there’s growing interest in it as organizations hit the ceiling of DevOps.
But There’s a Catch: The Investment Barrier
Implementing platform engineering isn’t without its challenges. Building a robust, scalable platform requires significant time, resources, and expertise. It demands a deep understanding of your organization’s technology stack, development workflows, and business objectives. And importantly, it diverts valuable resources away from core product development efforts.
Many organizations are hesitant to make this level of investment, especially if it’s not their core competency. They either end up doing it poorly—leading to a half-baked platform that doesn’t deliver the promised efficiencies—or they avoid it altogether, sticking to the DevOps status quo. This often leaves them with the worst of both worlds: the overhead of DevOps without the benefits of a streamlined, developer-friendly platform.
What we most often see are dev tools teams masquerading as platform engineering. As Camille Fournier puts it, they build scripts or tools around configuration management and infrastructure provisioning, not products. Usually it’s because they either don’t want to have skin in the game or they don’t have a mandate from leadership. “Not having skin in the game” means some combination of these things: a) they don’t want to build their own software, b) they don’t want to be on the hook for operations, or c) they don’t want to be in the critical path for production or become a bottleneck. Instead, they provide “blueprints” for these things and the burden and responsibility ultimately falls on the product teams—this is just DevOps.
Another issue is that organizations don’t want to allocate the headcount to do real platform engineering. They’re not wrong to be hesitant because it takes real investment to actually do it. As a result, however, they take half measures. We frequently see companies take an InnerSource approach as an attempt to basically socialize platform engineering. I have never seen this approach work well in practice unless there’s clear ownership and the team has a clear mandate. And just as before, this approach pushes scripts, not products. Without ownership and directive, it just reverts back to DevOps which leads to inefficiency and sprawl.
The Solution: Platform Engineering as a Service
This is where Platform Engineering as a Service (PEaaS) comes in. Unlike traditional Platform as a Service (PaaS) offerings, which provide a rigid, one-size-fits-all platform that abstracts away the underlying infrastructure, PEaaS is designed to be flexible and tailored to your unique requirements. It doesn’t hide the infrastructure but rather empowers your teams by providing the tools, automation, and best practices needed to build and operate cloud-native applications efficiently for your organization.
Instead of building and maintaining a custom platform internally, organizations can partner with experts who specialize in platform engineering and bring deep, hands-on experience to the table. With PEaaS, you get all the benefits of a mature, scalable platform without the heavy upfront investment or the distraction from your core product development. This means that a robust, enterprise-grade platform can be implemented in a fraction of the time, and managed for a fraction of the cost. What typically takes companies 6 months or more to build can be accomplished in days or weeks. And, what typically takes a team of 5 – 10 engineers working full-time to manage can be handled by 1 engineer, often on a part-time basis.
At Real Kinetic, we’ve been helping organizations accelerate their software delivery for years. In fact, we’ve been doing platform engineering long before it was called platform engineering. We bring our extensive expertise in cloud infrastructure, CI/CD, and developer enablement to build platforms that align with your organization’s unique needs and technology stack. By leveraging our Platform Engineering as a Service, you can stay focused on what you do best—building great products—while we take care of the complexities of infrastructure, automation, and developer tooling.
Why Real Kinetic?
Why should you trust us with your platform engineering needs? Because we’ve done it before, time and time again. Real Kinetic has helped numerous organizations—from startups to large enterprises—modernize their software delivery practices, improve developer productivity, and accelerate time to market. Our approach is rooted in real-world experience, not theory. We understand the challenges of scaling platforms because we’ve been there ourselves.
When you partner with Real Kinetic, you’re not just getting a service provider—you’re getting a team of experts who are invested in your success and have skin in the game. We’re here to build a platform that scales with your business, optimizes your development workflows, and ultimately drives more value for your customers.
Ready to Level Up Your Software Delivery?
If you’re tired of the inefficiencies of DevOps and ready to embrace the power of platform engineering, let’s talk. Real Kinetic’s Platform Engineering as a Service is your fast track to a scalable, efficient platform that empowers your developers and accelerates your time to market. And if you’re using AWS or GCP, we’re also looking for a few companies to pilot our batteries-included platform engineering product Konfigurate.
Follow @tyler_treat