Operations is going through a renaissance right now. With the move to cloud, the increasing amount of automation, and the increasing importance of automation, Ops as we know it is reinventing itself out of necessity. Infrastructure is becoming more and more sophisticated—and commoditized—and practices are just now starting to grow up around that. So while some worry about robots taking our jobs, the reality is more about how automation will help augment us to build better software and focus on higher-value things. It’s not so much about the distant future—whatever that may hold—so much as it is about the next five to ten years, what Operations looks like in that timeframe, and why I think it has to retool.
When we think about traditional Operations, we probably think about hardware and servers, managing networks and databases, application servers and runtimes, disaster recovery, Nagios checks, as well as the business side—vendor management, procurement, and so on. Finally, we have applications built on top by development teams.
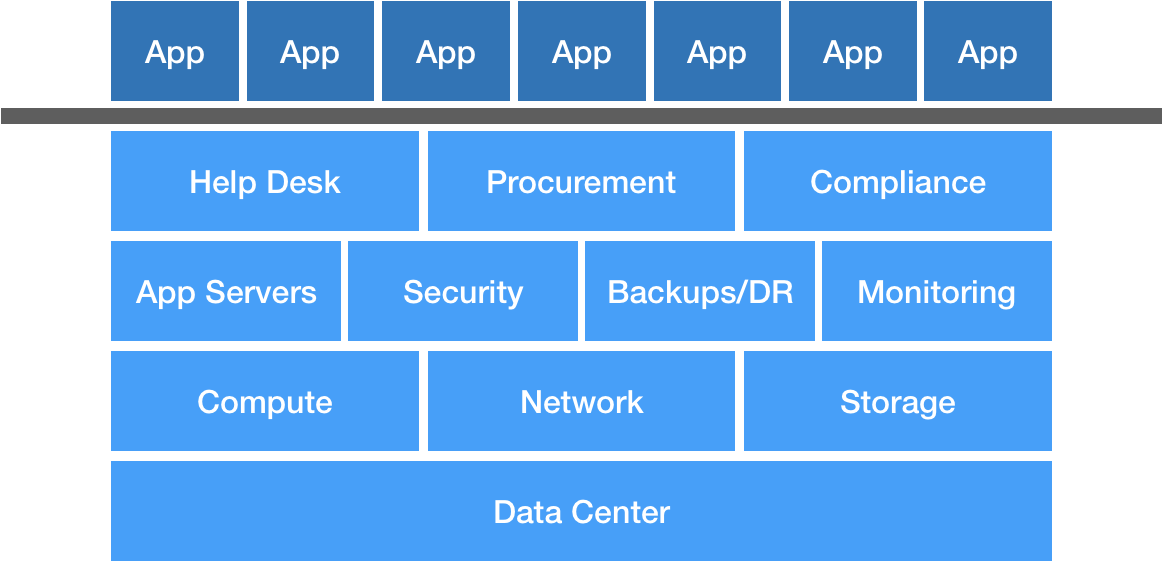
We have a nice, clean separation—developers focus on building features and products, and Ops focuses on making sure the lights stay on. Of course, we know the reality is this separation also creates a lot of problems, so DevOps was borne out of this as a way to bring these two groups into alignment by improving communication and feedback loops.
Now, with the move to cloud, many of these traditional Ops functions are effectively being outsourced to cloud providers, i.e. the idea of NoOps. We get unprecedented elasticity and on-demand compute with far less overhead than we ever had before—shrinking procurement time from days or weeks to seconds or minutes.
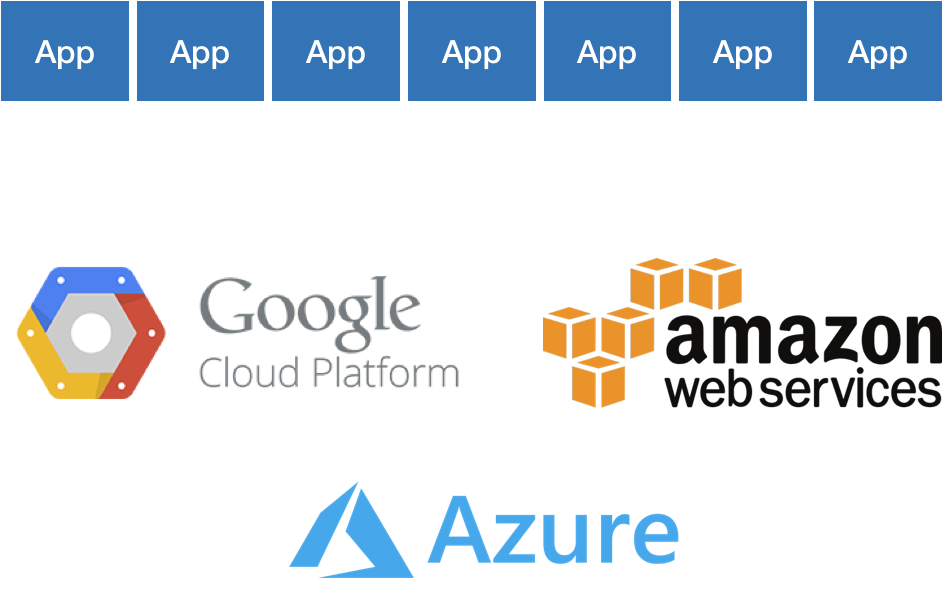
What this leaves is a thin but important slice between Google or Amazon and those products built by developers—the glue, essentially, between cloud and product. I call this NewOps (which I use facetiously in reference to NoSQL/NewSQL), and it’s the future of Ops. This encompasses infrastructure automation, deployment automation, configuration management, logging, monitoring, and many other things. When Marc Andreessen said software is eating the world, he really meant it. The future of Ops—and many other things—is software. It’s killing the boring, repetitive things we really don’t want to be doing anyway and letting us shift our focus elsewhere.
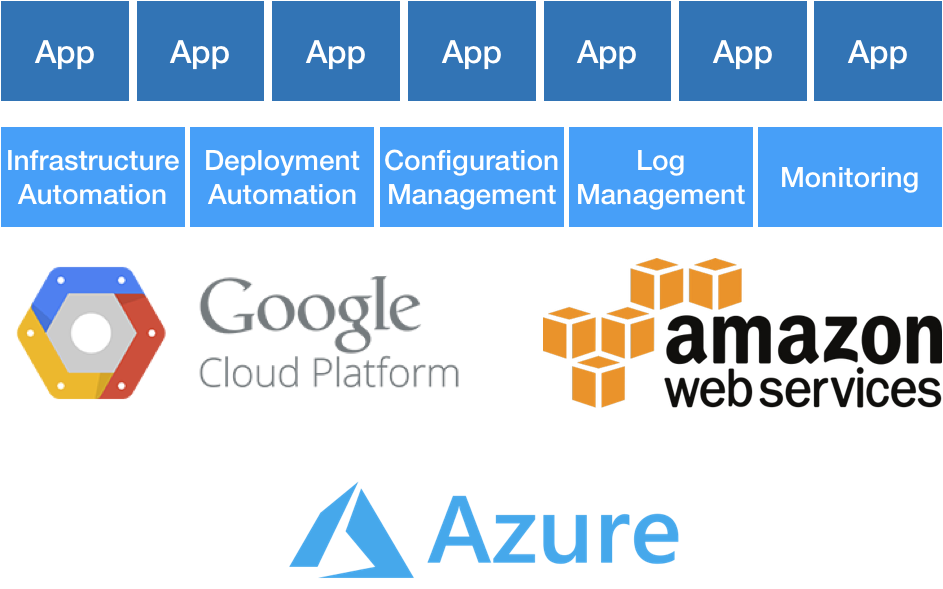
Certainly, automation is nothing new and is, I think, an important part of DevOps, so I’m going to explain what I mean by NewOps and why I’m distinguishing it. I also don’t want to mischaracterize by having these neatly delineated Ops models. The truth is, your company doesn’t just one day graduate and gets its DevOps diploma. Instead, it might evolve through various manifestations of these different models. DevOps is a journey, not a destination in and of itself.
I like to think of a DevOps scale of automation, from manual provisioning all the way to fully self-service. Next, I add a second dimension, org size, from the smallest startups to the biggest enterprises.
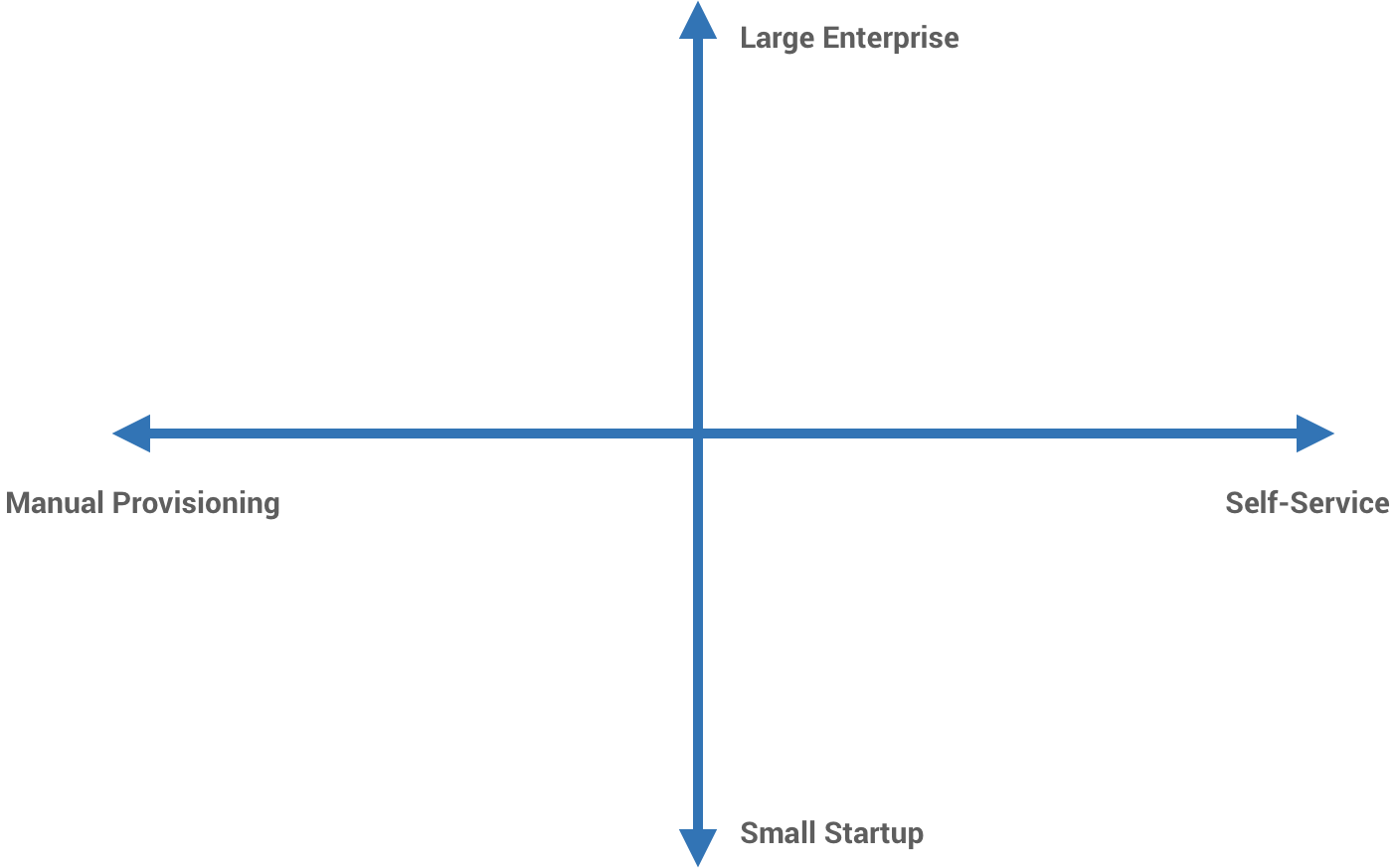
Scaling DevOps
Scaling a business is probably one of the hardest things a company has to go through. In particular, dealing with the problem of silos. They happen at every company as it grows, but why is it that silos form in the first place?
Many companies start with a “DevOps” approach, often out of necessity more than anything. As a small startup, we can’t afford to have dedicated developers, QA, Ops, and security people. We just have people, and those people wear many different hats. Developers might be pushing their own code to production. They might even be managing the infrastructure that code runs on. There’s probably not a lot of stability, probably a lot of risk, and probably not a whole lot of thought towards controlling costs.
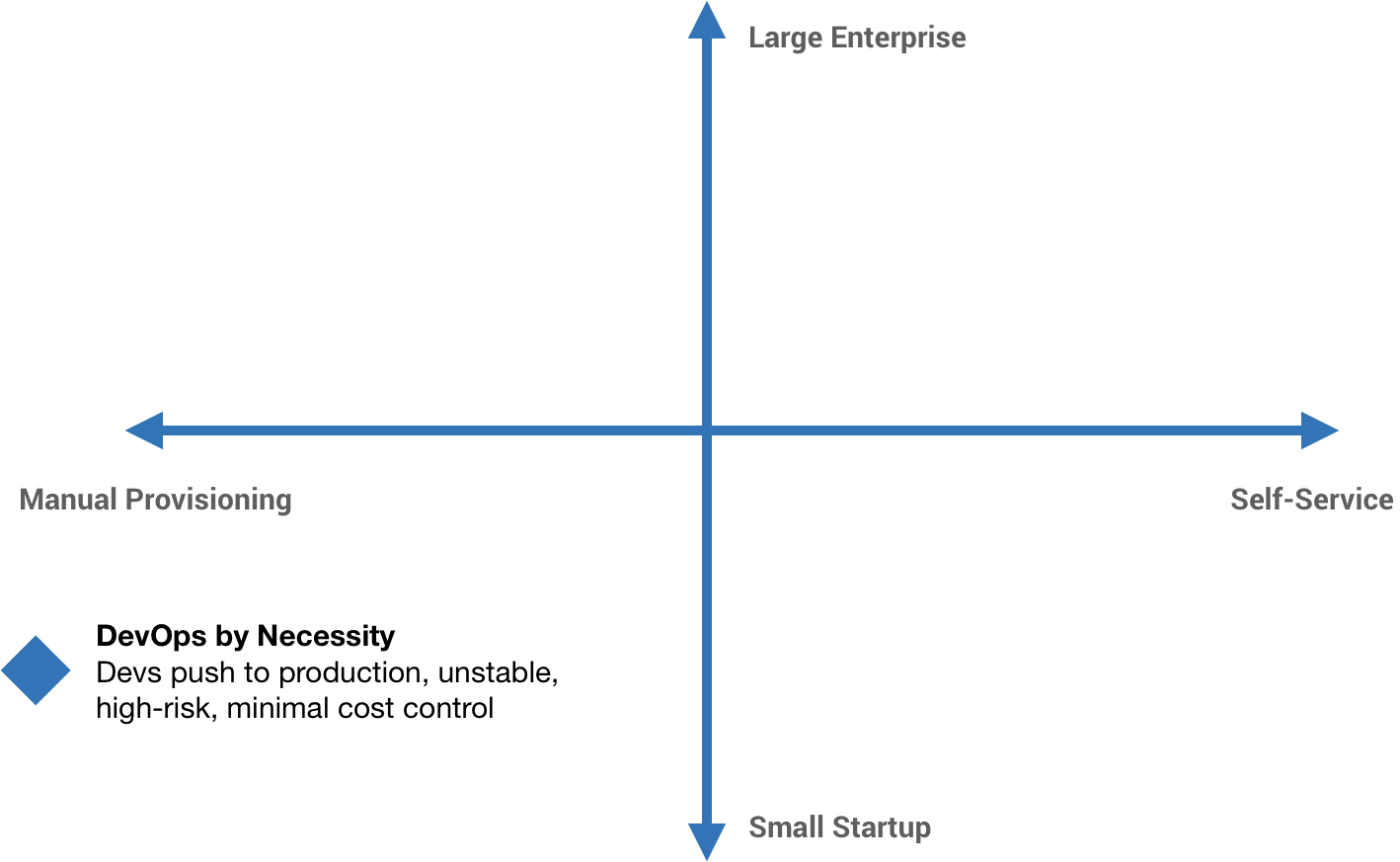
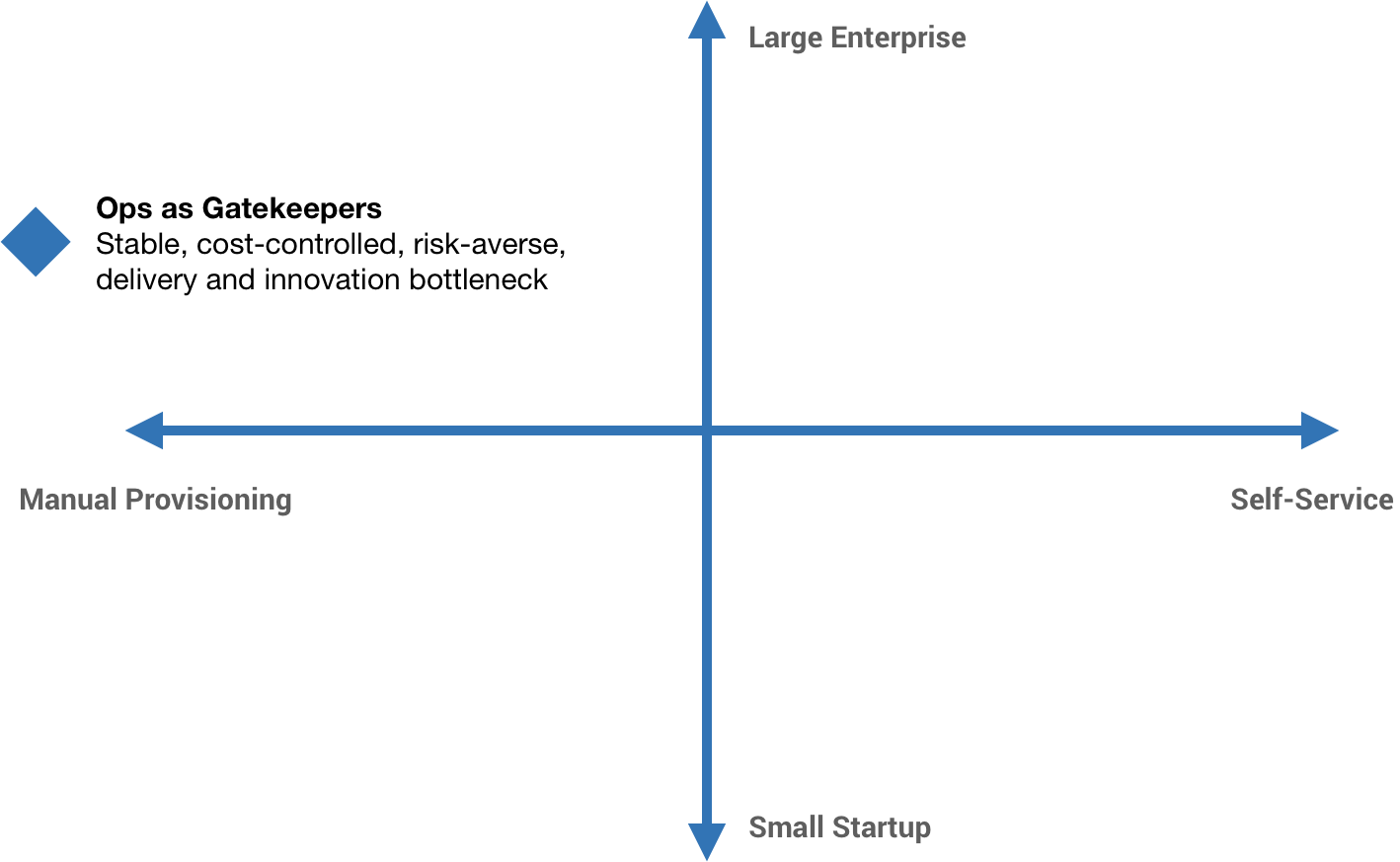
But as the product scales, we specialize. And as the business scales, we add various safety checks, controls, and processes. Developers write code, Ops people run it, QA gets blamed for defects, security blocks everything, and management wonders why nothing gets shipped.
And so we end up in the top left-hand quadrant with Ops as gatekeepers. Ops is fighting for stability and, at the same time, devs are basically fighting for change. More or less, we have a stable, cost-controlled, risk-averse environment—hopefully. But we also have a significant delivery and innovation bottleneck.
Specialization is good! But misalignment is not good. The question is, then, how do we scale specialization? Cross-functional teams come to mind. After all, DevOps encourages cooperation! We add an Ops engineer to each team, and maybe a reliability engineer, and perhaps a few extra for on-call backup, and of course a QA engineer too. Problem solved, right?
But hold on. What if we have 40 development teams? And all those teams are doing microservices. And, of course, all of those microservices are special snowflakes each with their own stacks, infrastructure, databases, and so on. This quickly gets out of control, but moreover, that’s a lot of teams and specialized roles on those teams. That’s a lot of headcount which equates to a lot of hiring and a lot of time and money. If you’re Google and you can just throw money at the problem, this might work out okay. For the rest of us, it might not be such a realistic option.
We go back to the drawing board and again ask ourselves how do we scale specialization? My thought to how we do this is with vision and product.
A vision is simply a mental image of what the future could be like. It enables independent decision making and alignment. Vision allows all of those teams, and the people on those teams, to make decisions without having to constantly coordinate with each other. Without vision, you’re just iterating to nowhere fast.
But vision without execution is just hallucination. Products are how we scale execution. Specifically, this idea of Operations through the lens of product, which I’ll describe after showing the parallel with what’s happening in QA.
In a lot of engineering organizations, many QA roles have been quietly disappearing. I think what’s happening is this evolution of QA, particularly, this shift from being test-focused to tools-focused.
We can look at companies like Amazon and Microsoft who popularized the SDET (Software Development Engineer in Test) model. These companies recognized that having a separate QA and development group causes a lot of problems, just like how having a separate Ops group does. We end up with SDEs (Software Development Engineers) who still focus on the development aspects of building software and SDETs who focus on the quality aspects, but rather than having two wholly separate groups, we just have development teams with SDETs embedded in them.
More recently, Microsoft moved to what they call a “Combined Engineering” model—effectively combining the SDE and SDET roles into a single role called a Software Engineer. Software Engineers write the product code, test code, and tools code needed to deliver their service. They are responsible for everything. Quality is a core concern of software development anyway.
Software Engineers write the code, unit tests, and integration tests. Those tests run in CI. The code moves through a CD pipeline before finally going out to production in some fashion. QA teams are shrinking, but what’s growing are the teams building the tools—the CI environments, the CD pipelines, the automated testing frameworks, the production tooling and automation, etc. The same is becoming true of Ops.
This is what I mean by “Operations through the lens of product.” The build, release, deploy automation, configuration management, infrastructure automation, logging, monitoring—these are all products.
Constraints often make problems easier. At Workiva, as we were struggling through that scaling phase, we placed a constraint on ourselves. We capped our infrastructure engineering headcount at 15% of R&D. This forced us to solve the problem using technology, and technical problems tend to be easier than people problems. In effect, this required us to productize our infrastructure. In doing so, we scaled. We controlled costs. We kept our headcount in check. We reduced risk. We accelerated development. Ultimately, we delivered value to customers faster, going from about three to four releases per year to multiple releases per day. In the end, this is really the goal of DevOps—to deliver value to customers continuously and to do it rapidly and reliably.
Rethinking Ops
It’s time we start to rethink Operations because clearly this model of Ops as cluster or infrastructure admins does not scale. Developers will always out-demand their capacity to supply. Either your headcount is out of control or your ability to innovate and deliver is severely hamstrung. Operations becomes this interrupt-driven thing where we’re just fighting fires as they happen. Ops as masters of production usually devolves to Ops becoming human incident routers, trying to figure out what team or person can help resolve problems because, being responsible for everything, they don’t have the insight to fix it themselves.
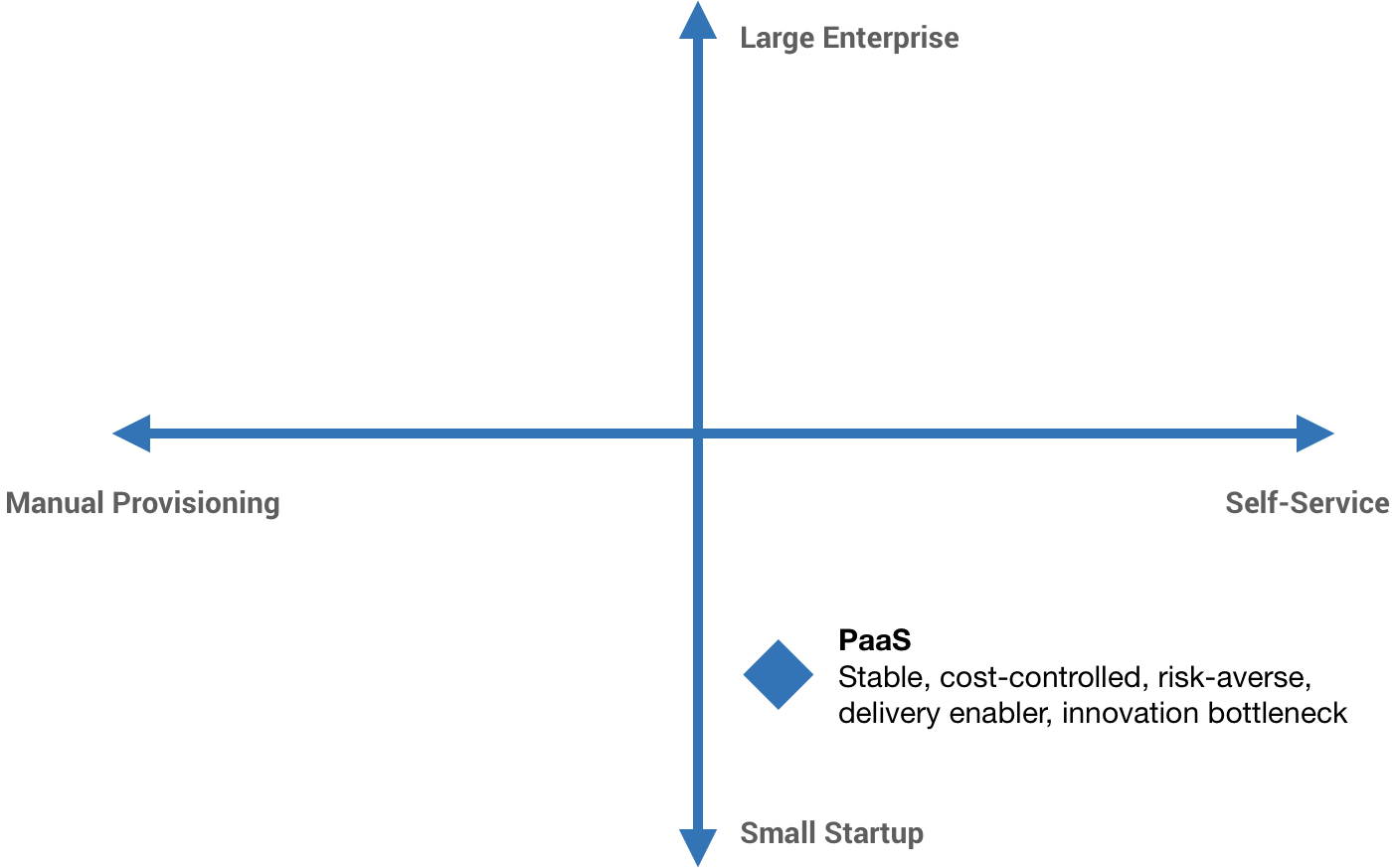
Another path that many companies take is Platform as a Service. Workiva is an example of this. For a very long time, Workiva didn’t have a traditional Ops team because the Ops team was Google. The first product was built on Google App Engine. This helped immensely to deliver value to customers quickly. We could just focus on the product and not the surrounding operational aspects, but there is a very real innovation bottleneck that comes with this.
The idea of “Ops lock-in” can be a major problem, whether it’s a PaaS like App Engine locking you in or your own Ops team who just isn’t able to support the kind of innovation that you’re trying to do.
My vision for the future of Operations is taking Combined Engineering to its logical conclusion. Just like with QA, Ops capabilities should be embedded within development teams. The reality is you can’t be an effective software engineer today without some Ops skills, and I think every role should be working towards automating itself out of a job. Specifically, my vision is enabling developers to self-service through tooling and automation and empowering them to deploy and operate their services.
The knee-jerk reaction to this idea is usually fully embracing Infrastructure as a Service, infrastructure as code, and giving developers freedom—and usually the consequences are dire. The point here is that the pendulum can swing too far in the other direction. This was a problem for a brief period of time at Workiva. As we were building new products off of App Engine, developers had this newfound freedom, so teams all went different directions introducing new tech, new infrastructure, new services, and so forth. It was a free-for-all, an explosion of stuff, and the cost explosion that comes with it.
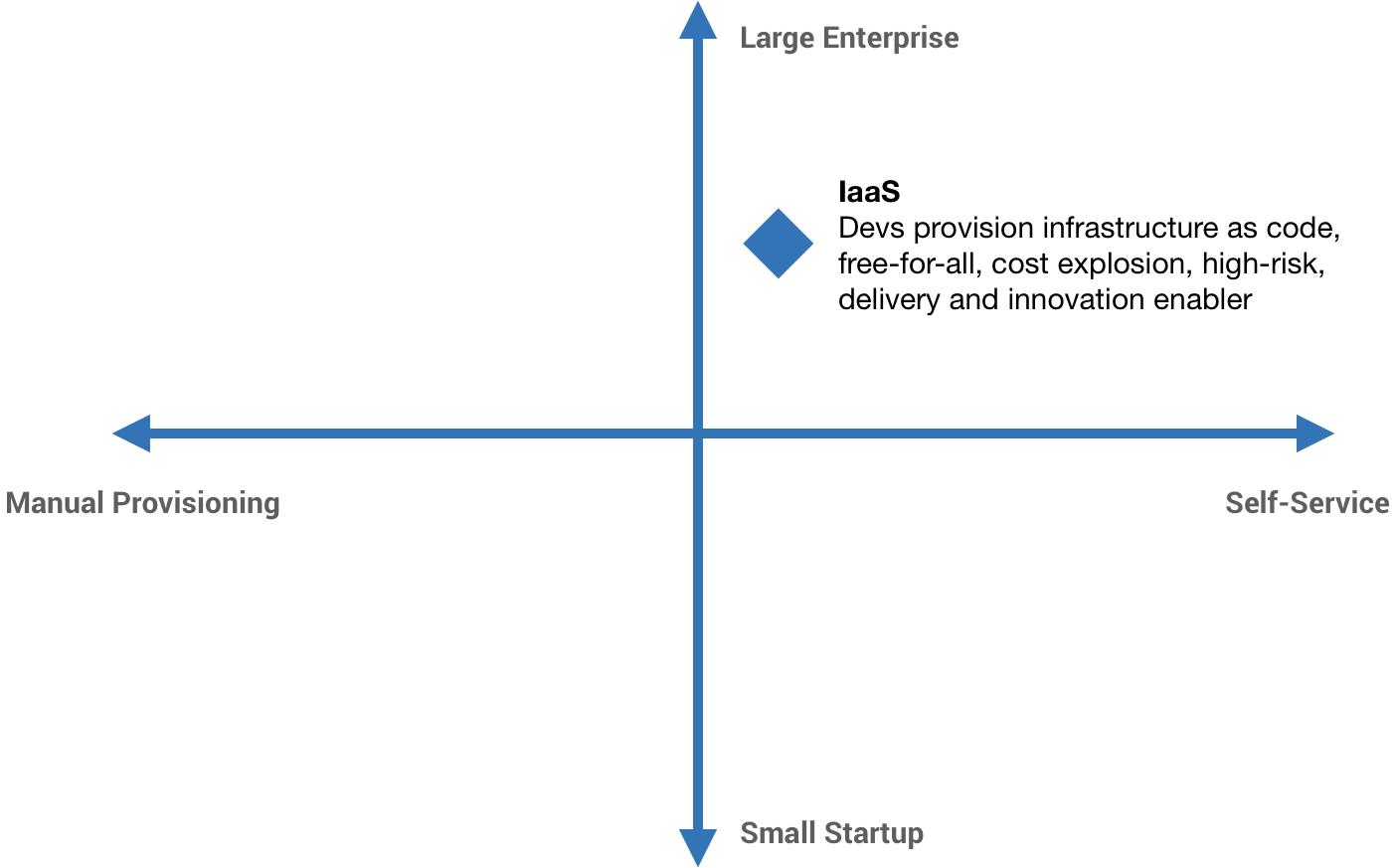
There has to be some control around that, so we tweak the vision statement a bit: enabling developers to self-service through tooling and automation and empowering them to deploy and operate their services…with minimal Ops intervention. We have to have some checks and balances in place.
With this, Ops become force multipliers. We move away from the reactive, interrupt-driven model where Ops are masters of production responsible for everything. Instead, we make dev teams responsible for their services but provide the tools they need to actually own their systems end-to-end—from the code on their laptops to operating it in production.
Enabling developers to self-service through tooling and automation means treating Ops as a product team. The infrastructure automation, deployment automation, configuration management, logging, monitoring, and production tools—these are all products. It’s these products that allow teams to fully own their services. This leads to empowerment.
I have this theory that all engineering organizations operate in this fashion which I call pain-driven development. As a company grows, it starts to develop limbs—teams or silos. Each of these limbs has its own pain receptors. Teams operate in a way that minimizes the amount of pain that they feel, it’s human instinct. We make locally optimal decisions to minimize pain and end up following a path of least resistance.
Silos promote pain displacement, which results in a “bulkhead” effect. Product development feels the pain of building software, QA feels the pain of testing software, and Ops feels the pain of running software. This creates broken feedback loops. For instance, developers aren’t feeling the pain Ops is feeling trying to run their software. We just throw things over the wall and it becomes an empathy problem.
This leads to misaligned incentives because each team will optimize for the pain that they feel. How do you expect developers to care about quality if they’re not on the hook? Similarly, how do you expect them to care about operability if they’re not on the hook? Developers won’t build truly reliable software until they are on-call for it and directly responsible. However, responsibility requires empowerment. You can’t have one without the other. You can’t ask someone to care about something and fix it without also giving them the power to do so. Most Ops teams simply haven’t done enough to empower and offload responsibility onto development teams.
Products enable ownership. We move away from Ops as masters of production responsible for everything and push that responsibility onto dev teams. They are the experts for their services. They are best equipped to deal with problems that arise. But we provide the tools they need to diagnose and resolve those problems on their own.
Products maintain control through enablement—enabling teams to follow best practices for builds, testing, deploys, support, and compliance. Compliance and other SDLC requirements have to be encoded into the tools and processes. These are things developers won’t empathize with or simply won’t understand. Rather than giving them a long list of things they have to do, we take as many of those things as we can and bake them into our products. If you use these tools or follow these processes, you’ll get a lot of this stuff for free. This reduces risk and accelerates development.
Similarly, we can’t allow all of the special snowflakes to happen. We have to control that explosion of stuff. To do this, we use pain-driven development to our advantage by creating paths of least resistance. Using standardized patterns, application shapes, and infrastructure services, we can setup “paths” to both make it easier to reach production and meet the goals of the business. As a developer, if you follow this path, your life will be a lot easier and you’ll feel less pain. If you deviate from that path, things get much harder—and painful.
We end up with a set “menu” of standard application shapes and infrastructure. If teams want to deviate and go off-menu, it’s on them to make a case for it. For example, if I want to introduce Erlang into our stack, it’s on my team and me to present the case for that. Part of this might mean we help build and maintain the tools needed to support that. If there is a compelling enough case or enough teams are making similar asks, we can start to standardize new shapes.
Note that we aren’t necessarily mandating technologies, but we’re leveraging pain-driven development to work in our favor.
Products in Practice
Next, I’m going to look at this idea of Operations through the lens of product in a bit more detail. We’ll see what this might actually look like in practice, again using Workiva as a bit of a case study.
Below is the high-level flow that I think about, from code on laptop to code in production.

Starting with the Build and continuous integration stage, this workflow tends to look something like the following. A developer pushes a change to a branch in a code repository, e.g. GitHub. This triggers a few things to happen. First, the build process, which runs unit/integration tests and builds artifacts. This, in turn, might trigger a QA and/or compliance process. At the same time, we have code reviews happening. All of these processes provide feedback to the developer to quickly iterate.
Workiva has a lot of automated processes built into the developer workflow, some off-the-shelf and some built in-house. For example, when a PR is opened, a security scanner runs which does static analysis and looks for various security vulnerabilities. This can flag a security review when a closer look is needed. Likewise, there is code coverage, automated builds, unit tests, and integration tests, Docker image builds, and compliance checks. The screenshots below come from an open-source repo showing some of these products in practice.
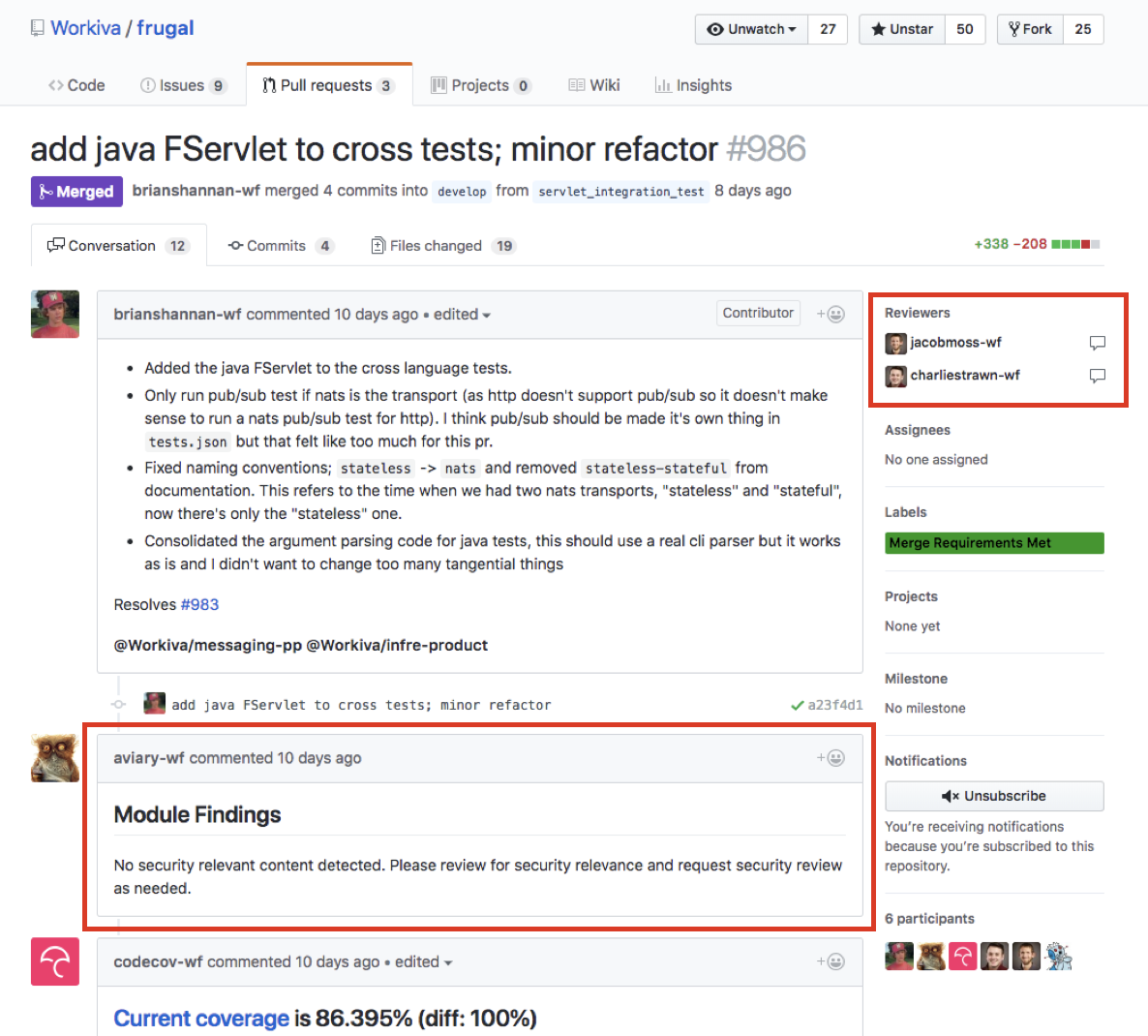
For compliance reasons, Workiva requires at least one other person sign-off on code changes. GitHub provides pretty good support for this. Code reviewers provide their feedback, developers work through that feedback, and, once satisfied, reviewers give their “plus one.”
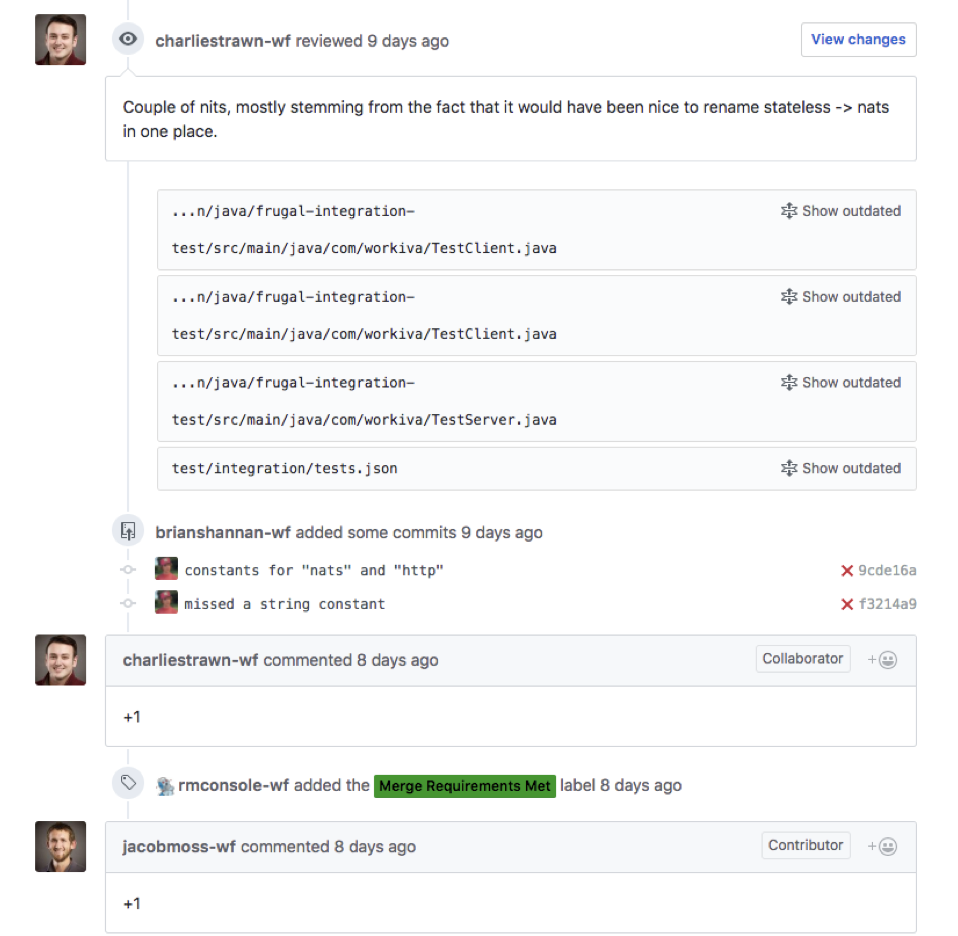
The screenshot below shows some of the automated processes Workiva relies on in the developer workflow: Travis CI, Codecov, Smithy (which is Workiva’s internal build system), Skynet (automated testing), Rosie (automated compliance controls, e.g. do you have code reviews, security reviews, other SDLC compliance requirements?), and Aviary (the security scanner). Once all of these have passed, the PR is automatically labeled with “Merge Requirements Met” and the change can be merged into master.
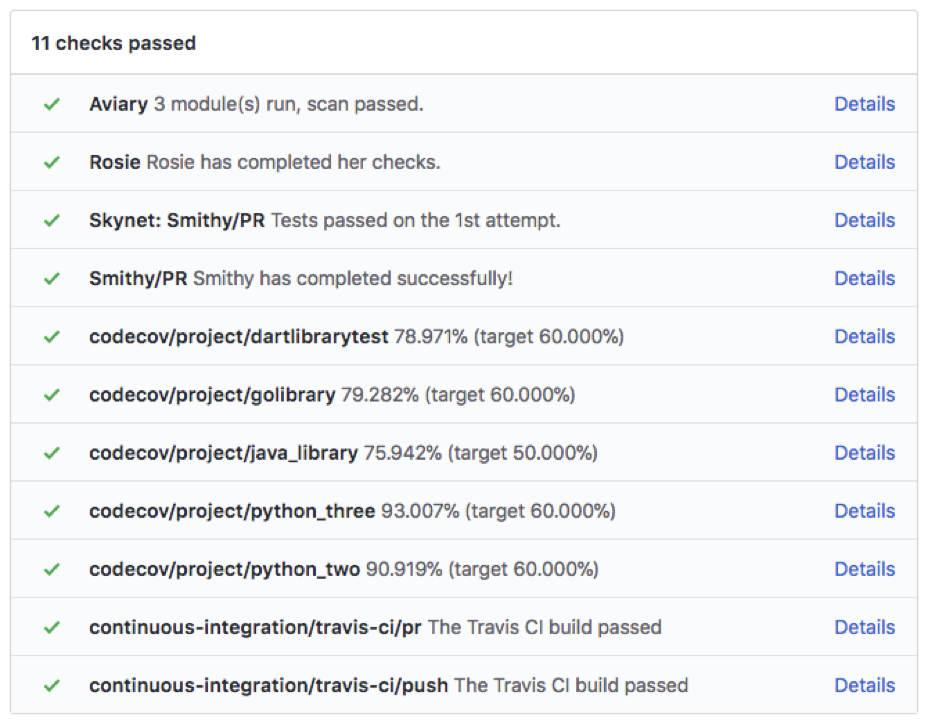
There are a couple things worth pointing out with this workflow. First, the build plan is part of the code and not baked into some build tool. This allows dev teams to fully control their builds. Second, you noticed that Workiva has very deep integration with GitHub. This has allowed them to build automated controls into the development process, which speeds up the developer’s workflow while reducing risk.
Next, we move on to the Release stage. This flow looks something like the following:
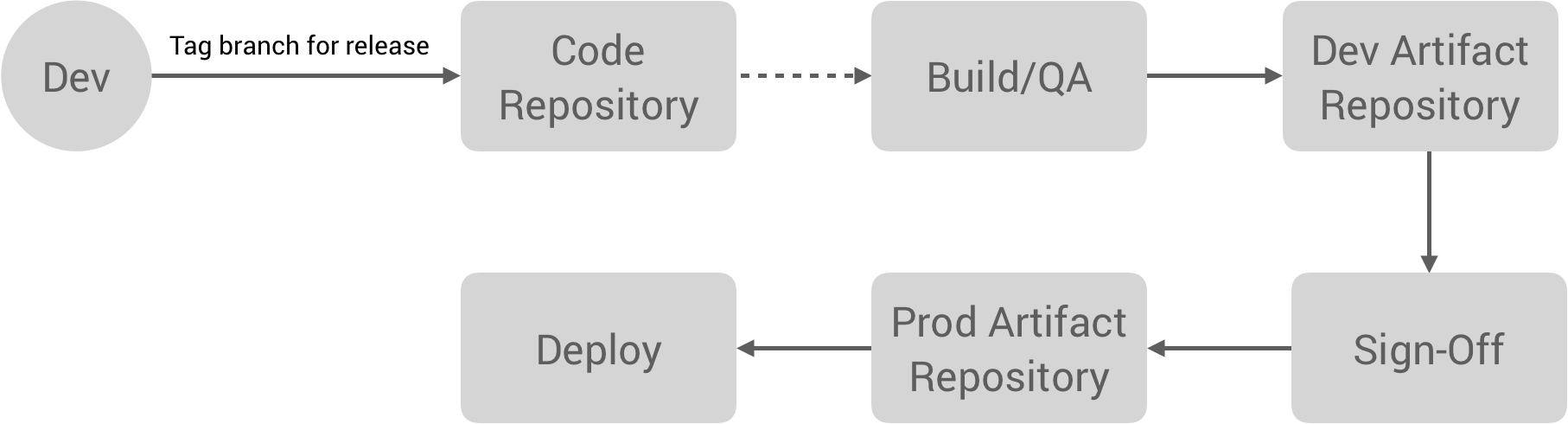
The developer tags a branch for release, which triggers a build process for creating the artifact. This may have a QA process which then promotes the artifact to a development artifact repository. As you may have noticed, Workiva has a lot of compliance requirements since they deal with companies’ pre-financial data, so there is typically a sign-off process at various stages involving different parties like Release Management, QA, Security, etc. Depending on your compliance controls, this might just be clicking a button to promote an artifact to a production repository. From there, it can actually be deployed to a production environment.
With this workflow, artifact tagging, building, and promotion is all automated. It’s also important we have processes around security. Container and machine image auditing is automated as well as security patching for OS updates, etc. For example, this workflow might use something like Packer to automate AMI building. Finally, the artifact sign-off is streamlined for the various parties involved, if not fully automated.
Now we’re ready to actually deploy our application. This is a key part of self-service and “owning” a product. This allows a team to configure their application and, ideally, deploy it themselves to production. Initially, this might be handled by a Release Management team who actually clicks the deploy button, but as you become more confident in your processes and your tools become more mature, more of this responsibility can be pushed onto the development teams.
This is also where control comes into play. For instance, I may be allowed to configure my application to use 1GB of RAM, but if I need 1TB, I may need to get additional sign-off.
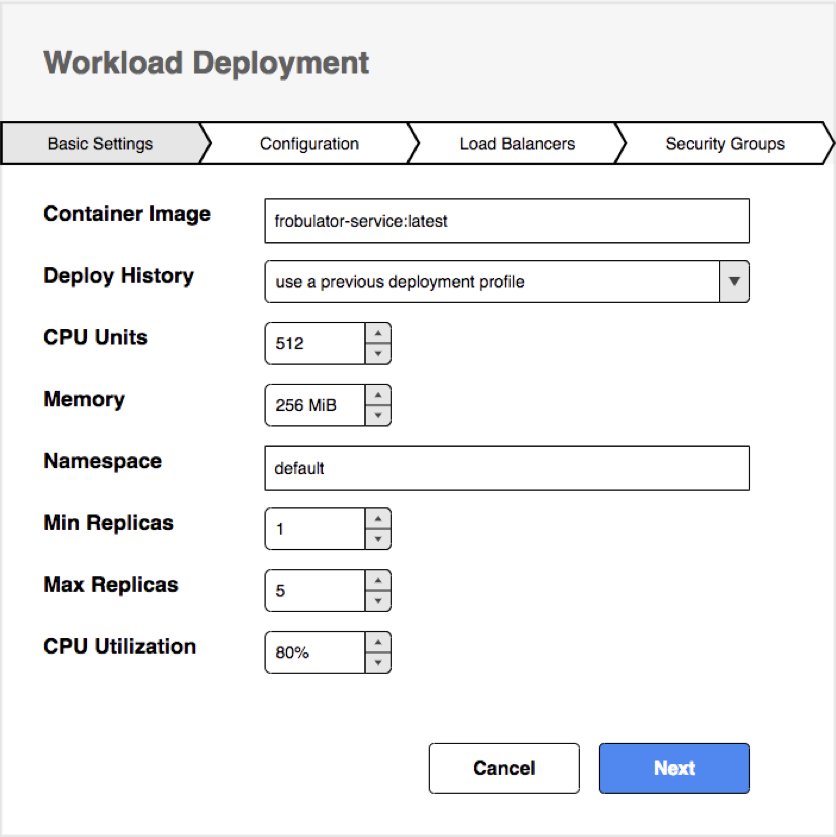
Self-service deploys and self-service configuration—with guard rails—are an important part of continuous deployment. Additionally, infrastructure provisioning should be automated. No more submitting tickets for a nameless Ops person to provision and configure servers, VMs, or other resources—no ticket-driven development.
I’ve been deliberate about not prescribing particular solutions for some of these problems. You might be using Kubernetes or ECS to orchestrate containers, it doesn’t really matter. These should mostly be implementation details. What does matter, though, is having good abstractions around certain implementation details. For example, Workiva was meticulous about building some layers around workload scheduling. This allowed them at one point to switch from using Fleet to ECS to manage containers with virtually no impact to developers. With the amount of churn that happens in tech, it’s important not to tie yourself too heavily to any one implementation. Instead, think about the APIs you expose for your infrastructure and consider those the deliverable.
Finally, we need to operate our service in production, another important part of ownership. There are a lot of products here, so we’ll just look at a cross section.
Logging is arguably the most important part of how we figure out what is happening in our systems. For this reason, Workiva built structured logging and metrics specs and language libraries implementing these specs. As a developer, this made it easy to simply pull in the library for your language and get structured, contextual logging for free. The other half to this was building out a data pipeline. Basically all metadata at Workiva went into Amazon Kinesis, including logs, metrics, and traces. First, this allowed us to reuse the same infrastructure for all of this data, from the agents running on the machines to the pipeline itself. Second, it allowed us to fan this data out to different backend systems—Splunk, SumoLogic, Datadog, Stackdriver, BigQuery, as well as various internal tools. This is probably one of the most important things you can do with your infrastructure.
Other continuous operations tools include telemetry, tracing, health checks, alerting, and more sophisticated production tools like canary deploys, A/B testing, and traffic shadowing. Some might refer to these as tools for testing in production. Realistically, once you reach a certain scale, testing in production is the only real alternative to the proliferation of deployment environments.
It’s worth mentioning that you do not need to build all of these products yourself. In fact, you shouldn’t. Many off-the-shelf solutions just need glued together. However, I’ve also come to realize that it’s often the “glue” that is important. That is to say, taking some large, commercial off-the-shelf solution and introducing it into a company is frequently rife with headaches. It’s like Jira, a big Frankenstein product that attempts to solve everyone’s problems and, in doing so, solves none of them particularly well. This is why I tend to favor small, modular solutions that can be composed. But it also highlights why there is a cultural aspect to this.
If you think the solution to your ailments is some magical product—maybe a CI/CD pipeline or Kubernetes or something else—you’re misguided. If anything, most problems are cultural, not technical in nature. Technology will not fix your broken culture! The products are not the endgame, they are a means to an end. And the products need to fit the company, its culture, its architecture, and its constraints. It’s tempting to take something you see on Hacker News and introduce it into your stack, but you have to be careful.
Likewise, it’s tempting to dive straight into the deep-end, automate everything, and build out a highly sophisticated infrastructure. But it’s important to start small and evolve over time. My approach to this is get the workflow correct, start manual, then automate more and more over time.
Wrapping Up
Specialization leads to misalignment and broken feedback loops, but it’s an important part of scaling a business. The question is: how do we specialize?
We know the traditional Ops model does not scale—devs will always out-demand capacity in this reactive model. Not only this, the siloing creates an empathy problem. DevOps attempts to help with this by tightening feedback loops and building empathy. NewOps takes this further by empowering teams and providing autonomy. It’s not a replacement for DevOps, it’s an evolution of it. It’s applying a product mindset to the traditional Ops model.
The future of Ops is taking Combined Engineering to its logical conclusion. As such, Ops teams should be redefining their vision from being masters of production to enablers of production. Just like with QA, Ops capabilities need to be embedded within dev teams, but the caveat is they need to be enabled! This is the direction Operations is headed. Software is eating the world, which means both up and down the stack. NewOps treats Ops like a product team whose product, effectively, is infrastructure. It’s creating guard rails, not walls—taking SDLC and compliance controls and encoding them into products rather than giving devs a laundry list of things, having them run the gauntlet through a long, drawn-out development process, and having a gatekeeper at the end.
Offloading responsibility helps correct and scale feedback loops. In my opinion, this is how we scale specialization. Operations isn’t going away, it’s just getting a product manager.
Follow @tyler_treat