Like most industry jargon, “DevOps” means a lot of things to a lot of different people. While many folks view it as specific to certain tooling or practices, such as CI/CD or Infrastructure as Code (IaC), I’ve always viewed it as an organizational model for how software is built and delivered. In particular, my interpretation is that DevOps is about shifting more responsibilities “left” onto developers, moving away from the more traditional “throw it over the wall” approach to IT operations. No doubt this encompasses tooling or practices like CI/CD and IaC, which are responsibilities that developers now shoulder, perhaps with the support of dev tools, productivity, or enablement teams—some companies just call this the “DevOps” team.
While many organizations still operate with the traditional silos, DevOps has established itself as an industry norm. But as organizations push the boundaries of software development, the limitations of DevOps are becoming increasingly apparent. The problem is that DevOps, in its pursuit of speed and autonomy, often results in chaos and inefficiency. Teams end up reinventing the wheel, creating bespoke solutions for the same problems, and struggling with inconsistent tooling and practices across the organization. The outcome? Technical debt, fragmented processes, and wasted effort. Many of the teams we work with at Real Kinetic spend significantly more time on the “DevOps work” than they do on actual product work.
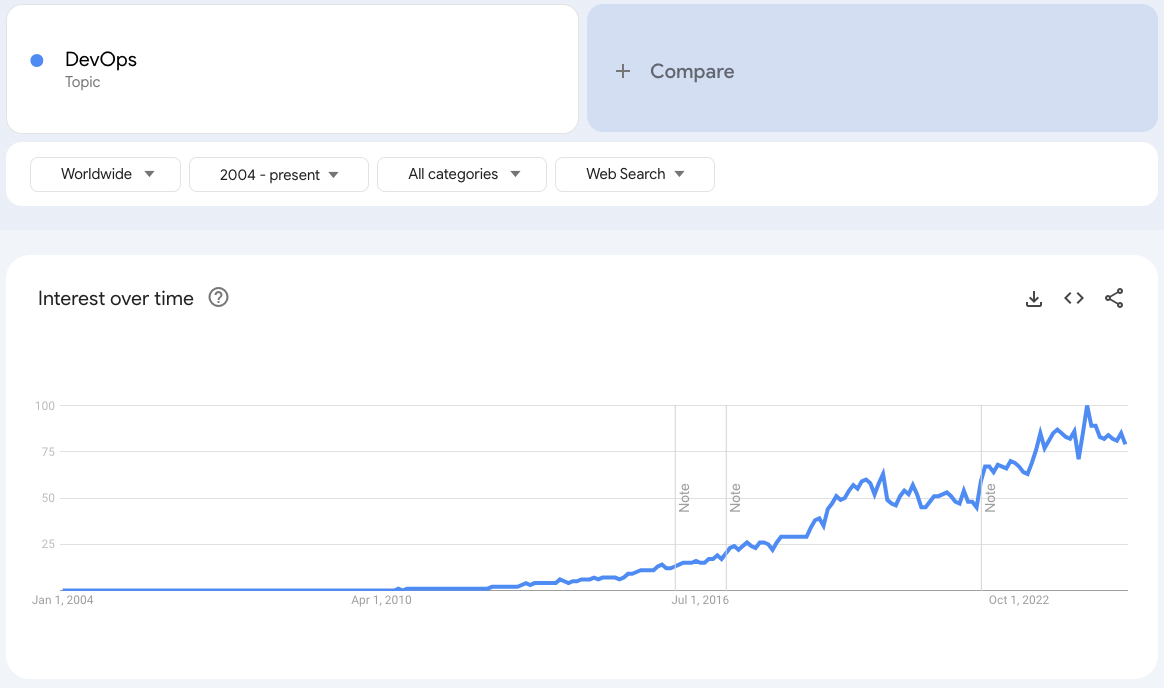
Google Trends for “DevOps”
The Rise of Platform Engineering
This is where Platform Engineering comes in. Rather than having each development team own their entire infrastructure stack, platform engineering provides a centralized, productized approach to infrastructure and developer tools. It’s about creating reusable, self-service platforms that development teams can leverage to build, deploy, and scale their applications efficiently. These platforms abstract away the complexities of cloud infrastructure, CI/CD pipelines, and security, enabling developers to focus on writing code rather than managing infrastructure or “glue”.
Platform engineering brings structure to the chaos of DevOps by creating a standardized, cohesive platform that empowers development teams while maintaining best practices and governance. It’s a solution to the growing complexity and sprawl that comes with scaling software delivery and scaling DevOps. Platform engineering is very much in its infancy as DevOps was circa 2012, but there’s growing interest in it as organizations hit the ceiling of DevOps.
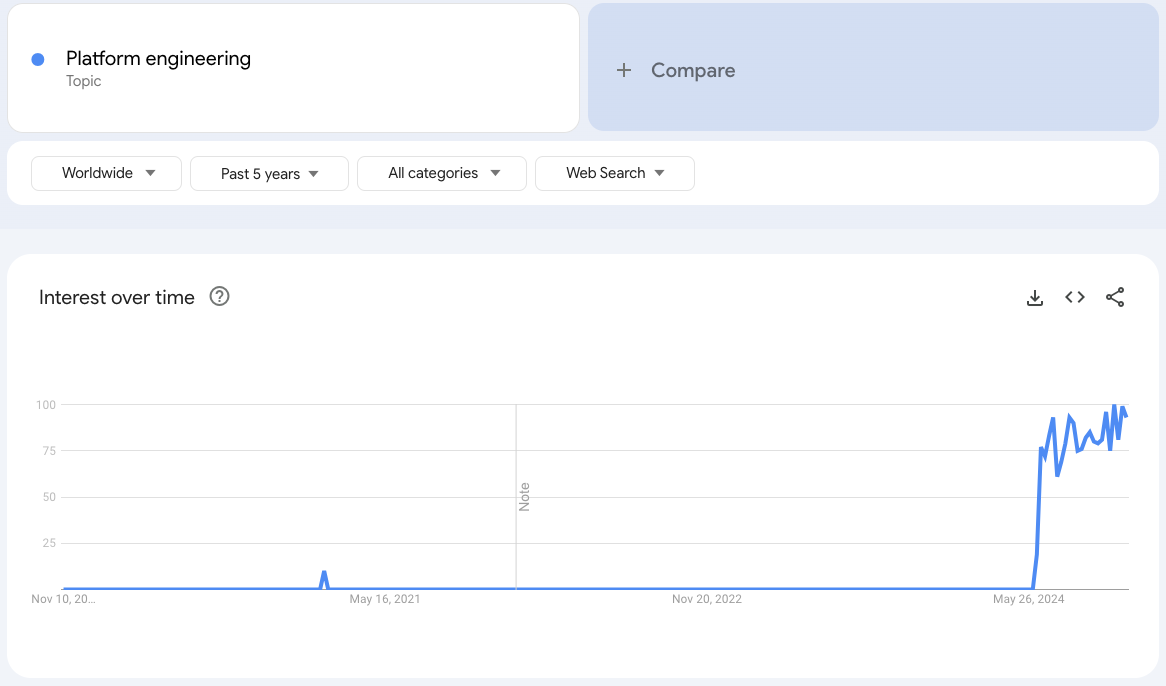
Google Trends for “Platform Engineering”
But There’s a Catch: The Investment Barrier
Implementing platform engineering isn’t without its challenges. Building a robust, scalable platform requires significant time, resources, and expertise. It demands a deep understanding of your organization’s technology stack, development workflows, and business objectives. And importantly, it diverts valuable resources away from core product development efforts.
Many organizations are hesitant to make this level of investment, especially if it’s not their core competency. They either end up doing it poorly—leading to a half-baked platform that doesn’t deliver the promised efficiencies—or they avoid it altogether, sticking to the DevOps status quo. This often leaves them with the worst of both worlds: the overhead of DevOps without the benefits of a streamlined, developer-friendly platform.
What we most often see are dev tools teams masquerading as platform engineering.As Camille Fournier puts it, they build scripts or tools around configuration management and infrastructure provisioning, not products. Usually it’s because they either don’t want to have skin in the game or they don’t have a mandate from leadership. “Not having skin in the game” means some combination of these things: a) they don’t want to build their own software, b) they don’t want to be on the hook for operations, or c) they don’t want to be in the critical path for production or become a bottleneck. Instead, they provide “blueprints” for these things and the burden and responsibility ultimately falls on the product teams—this is just DevOps.
Another issue is that organizations don’t want to allocate the headcount to do real platform engineering. They’re not wrong to be hesitant because it takes real investment to actually do it. As a result, however, they take half measures. We frequently see companies take an InnerSource approach as an attempt to basically socialize platform engineering. I have never seen this approach work well in practice unless there’s clear ownership and the team has a clear mandate. And just as before, this approach pushes scripts, not products. Without ownership and directive, it just reverts back to DevOps which leads to inefficiency and sprawl.
The Solution: Platform Engineering as a Service
This is where Platform Engineering as a Service (PEaaS) comes in. Unlike traditional Platform as a Service (PaaS) offerings, which provide a rigid, one-size-fits-all platform that abstracts away the underlying infrastructure, PEaaS is designed to be flexible and tailored to your unique requirements. It doesn’t hide the infrastructure but rather empowers your teams by providing the tools, automation, and best practices needed to build and operate cloud-native applications efficiently for your organization.
Instead of building and maintaining a custom platform internally, organizations can partner with experts who specialize in platform engineering and bring deep, hands-on experience to the table. With PEaaS, you get all the benefits of a mature, scalable platform without the heavy upfront investment or the distraction from your core product development. This means that a robust, enterprise-grade platform can be implemented in a fraction of the time, and managed for a fraction of the cost. What typically takes companies 6 months or more to build can be accomplished in days or weeks. And, what typically takes a team of 5 – 10 engineers working full-time to manage can be handled by 1 engineer, often on a part-time basis.
At Real Kinetic, we’ve been helping organizations accelerate their software delivery for years. In fact, we’ve been doing platform engineering long before it was called platform engineering. We bring our extensive expertise in cloud infrastructure, CI/CD, and developer enablement to build platforms that align with your organization’s unique needs and technology stack. By leveraging our Platform Engineering as a Service, you can stay focused on what you do best—building great products—while we take care of the complexities of infrastructure, automation, and developer tooling.
Why Real Kinetic?
Why should you trust us with your platform engineering needs? Because we’ve done it before, time and time again. Real Kinetic has helped numerous organizations—from startups to large enterprises—modernize their software delivery practices, improve developer productivity, and accelerate time to market. Our approach is rooted in real-world experience, not theory. We understand the challenges of scaling platforms because we’ve been there ourselves.
When you partner with Real Kinetic, you’re not just getting a service provider—you’re getting a team of experts who are invested in your success and have skin in the game. We’re here to build a platform that scales with your business, optimizes your development workflows, and ultimately drives more value for your customers.
Ready to Level Up Your Software Delivery?
If you’re tired of the inefficiencies of DevOps and ready to embrace the power of platform engineering, let’s talk. Real Kinetic’s Platform Engineering as a Service is your fast track to a scalable, efficient platform that empowers your developers and accelerates your time to market. And if you’re using AWS or GCP, we’re also looking for a few companies to pilot our batteries-included platform engineering product Konfigurate.
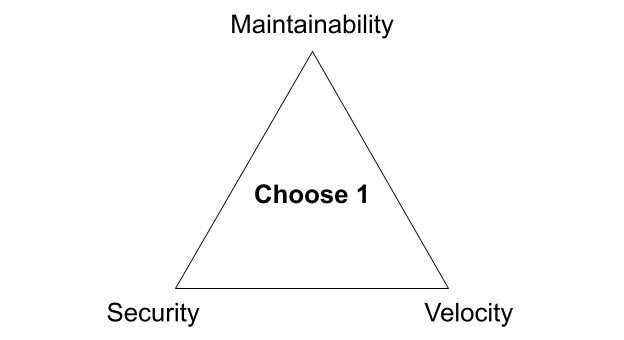
There are three competing priorities that companies have as it relates to software development: security, maintainability, and velocity. I’ll elaborate on what I mean by each of these in just a bit. When I originally started thinking about this, I thought of it in the context of the “good, fast, cheap: choose two” project management triangle. But after thinking about it for more than a couple minutes, and as I related it to my own experience and observations at other companies, I realized that in practice it’s much worse. For most organizations building software, it’s more like security, maintainability, velocity: choose one.
The Software Development Triangle
Of course, most organizations are not explicitly making these trade-offs. Instead, the internal preferences and culture of the company reveal them. I believe many organizations, consciously or not, accept this trade-off as an immovable constraint. More risk-averse groups might even welcome it. Though the triangle most often results in a “choose one” sort of compromise, it’s not some innate law. You can, in fact, have all three with a little bit of careful thought and consideration. And while reality is always more nuanced than what this simple triangle suggests, I find looking at the extremes helps to ground the conversation. It emphasizes the natural tension between these different concerns. Bringing that tension to the forefront allows us to be more intentional about how we manage it.
It wasn’t until recently that I distilled down these trade-offs and mapped them into the triangle shown above, but we’ve been helping clients navigate this exact set of competing priorities for over six years at Real Kinetic. We built Konfig as a direct response to this since it was such a common challenge for organizations. We’re excited to offer a solution which is the culmination of years of consulting and which allows organizations to no longer compromise, but first let’s explore the trade-offs I’m talking about.
Security
Companies, especially mid- to large- sized organizations, care a great deal about security (and rightfully so!). That’s not to say startups don’t care about it, but the stakes are just much higher for enterprises. They are terrified of being the next big name in the headlines after a major data breach or ransomware attack. I call this priority security for brevity, but it actually consists of two things which I think are closely aligned: security and governance.
Governance directly supports security in addition to a number of other concerns like reliability, risk management, and compliance. This is sometimes referred to as Governance, Risk, and Compliance or GRC. Enterprises need control over, and visibility into, all of the pieces that go into building and delivering software. This is where things like SDLC, separation of duties, and access management come into play. Startups may play it more fast and loose, but more mature organizations frequently have compliance or regulatory obligations like SOC 2 Type II, PCI DSS, FINRA, FedRAMP, and so forth. Even if they don’t have regulatory constraints, they usually have a reputation that needs to be protected, which typically means more rigid processes and internal controls. This is where things can go sideways for larger organizations as it usually leads to practices like change review boards, enterprise (ivory tower) architecture programs, and SAFe. Enterprises tend to be pretty good at governance, but it comes at a cost.
It should come as no surprise that security and governance are in conflict with speed, but they are often in contention with well-architected and maintainable systems as well. When organizations enforce strong governance and security practices, it can often lead to developers following bad practices. Let me give an example I have seen firsthand at an organization.
A company has been experiencing stability and reliability issues with its software systems. This has caused several high-profile, revenue-impacting outages which have gotten executives’ attention. The response is to implement a series of process improvements to effectively slow down the release of changes to production. This includes a change review board to sign-off on changes going to production and a production gating process which new workloads going to production must go through before they can be released. The hope is that these process changes will reduce defects and improve reliability of systems in production. At this point, we are wittingly trading off velocity.
What actually happened is that developers began batching up more and more changes to get through the change review board which resulted in “big bang” releases. This caused even more stability issues because now large sets of changes were being released which were increasingly complex, difficult to QA, and harder to troubleshoot. Rollbacks became difficult to impossible due to the size and complexity of releases, increasing the impact of defects. Release backlogs quickly grew, prompting developers to move on to more work rather than sit idle, which further compounded the issue and led to context switching. Decreasing the frequency of deployments only exacerbated these problems. Counterintuitively, slowing down actually increased risk.
To avoid the production gating process, developers began adding functionality to existing services which, architecturally speaking, should have gone into new services. Services became bloated grab bags of miscellaneous functionality since it was easier to piggyback features onto workloads already in production than it was to run the gauntlet of getting a new service to production. These processes were directly and unwittingly impacting system architecture and maintainability. In economics, this is called a “negative externality.” We may have security and governance, but we’ve traded off velocity and maintainability. Adding insult to injury, the processes were not even accomplishing the original goal of improving reliability, they were making it worse!
Maintainability
It’s critical that software systems are not just built to purpose, but also built to last. This means they need to be reliable, scalable, and evolvable. They need to be conducive to finding and correcting bugs. They need to support changing requirements such that new features and functionality can be delivered rapidly. They need to be efficient and cost effective. More generally, software needs to be built in a way that maximizes its useful life.
We simply call this priority maintainability. While it covers a lot, it can basically be summarized as: is the system architected and implemented well? Is it following best practices? Is there a lot of tech debt? How much thought and care has been put into design and implementation? Much of this comes down to gut feel, but an experienced engineer can usually intuit whether or not a system is maintainable pretty quickly. A good proxy can often be the change fail rate, mean time to recovery, and the lead time for implementing new features.
Maintainability’s benefits are more of a long tail. A maintainable system is easier to extend and add new features later, easier to identify and fix bugs, and generally experiences fewer defects. However, the cost for that speed is basically frontloaded. It usually means moving slower towards the beginning while reaping the rewards later. Conversely, it’s easy to go fast if you’re just hacking something together without much concern for maintainability, but you will likely pay the cost later. Companies can become crippled by tech debt and unmaintained legacy systems to the point of “bankruptcy” in which they are completely stuck. This usually leads to major refactors or rewrites which have their own set of problems.
Additionally, building systems that are both maintainable and secure can be surprisingly difficult, especially in more dynamic cloud environments. If you’ve ever dealt with IAM, for example, you know exactly what I mean. Scoping identities with the right roles or permissions, securely managing credentials and secrets, configuring resources correctly, ensuring proper data protections are in place, etc. Misconfigurations are frequently the cause of the major security breaches you see in the headlines. The unfortunate reality is security practices and tooling lag in the industry, and security is routinely treated as an afterthought. Often it’s a matter of “we’ll get it working and then we’ll come back later and fix up the security stuff,” but later never happens. Instead, an IAM principal is left with overly broad access or a resource is configured improperly. This becomes 10x worse when you are unfamiliar with the cloud, which is where many of our clients tend to find themselves.
Velocity
The last competing priority is simply speed to production or velocity. This one probably requires the least explanation, but it’s consistently the priority that is sacrificed the most. In fact, many organizations may even view it as the enemy of the first two priorities. They might equate moving fast with being reckless. Nonetheless, companies are feeling the pressure to deliver faster now more than ever, but it’s much more than just shipping quickly. It’s about developing the ability to adapt and respond to changing market conditions fast and fluidly. Big companies are constantly on the lookout for smaller, more nimble players who might disrupt their business. This is in part why more and more of these companies are prioritizing the move to cloud. The data center has long been their moat and castle as it relates to security and governance, however, and the cloud presents a new and serious risk for them in this space. As a result, velocity typically pays the price.
As I mentioned earlier, velocity is commonly in tension with maintainability as well, it’s usually just a matter of whether that premium is frontloaded or backloaded. More often than not, we can choose to move quickly up front but pay a penalty later on or vice versa. Truthfully though, if you’ve followed the DORA State of DevOps Reports, you know that a lot of companies neither frontload nor backload their velocity premium—they are just slow all around. These are usually more legacy-minded IT shops and organizations that treat software development as an IT cost center. These are also usually the groups that bias more towards security and governance, but they’re probably the most susceptible to disruption. “Move fast and break things” is not a phrase you will hear permeating these organizations, yet they all desire to modernize and accelerate. We regularly watch these companies’ teams spend months configuring infrastructure, and what they construct is often complex, fragile, and insecure.
Choose Three
Businesses today are demanding strong security and governance, well-structured and maintainable infrastructure, and faster speed to production. The reality, however, is that these three priorities are competing with each other, and companies often end up with one of the priorities dominating the others. If we can acknowledge these trade-offs, we can work to better understand and address them.
We built Konfig as a solution that tackles this head-on by providing an opinionated configuration of Google Cloud Platform and GitLab. Most organizations start from a position where they must assemble the building blocks in a way that allows them to deliver software effectively, but their own biases result in a solution that skews one way or the other. Konfig instead provides a turnkey experience that minimizes time-to-production, is secure by default, and has governance and best practices built in from the start. Rather than having to choose one of security, maintainability, and velocity, don’t compromise—have all three. In a follow-up post I’ll explain how Konfig addresses concerns like security and governance, infrastructure maintainability, and speed to production in a “by default” way. We’ll see how IAM can be securely managed for us, how we can enforce architecture standards and patterns, and how we can enable developers to ship production workloads quickly by providing autonomy with guardrails and stable infrastructure.
We encounter a lot of organizations talking about or attempting to implement SRE as part of our consulting at Real Kinetic. We’ve even discussed and debated ourselves, ad nauseam, how we can apply it at our own product company, Witful. There’s a brief, unassuming section in the SRE book tucked away towards the tail end of chapter 32, “The Evolving SRE Engagement Model.” Between the SLIs and SLOs, the error budgets, alerting, and strategies for handling change management, it’s probably one of the most overlooked parts of the book. It’s also, in my opinion, one of the most important.
Chapter 32 starts by discussing the “classic” SRE model and then, towards the end, how Google has been evolving beyond this model. “External Factors Affecting SRE”, under the “Evolving Services Development: Frameworks and SRE Platform” heading, is the section I’m referring to specifically. This part of the book details challenges and approaches for scaling the SRE model described in the preceding chapters. This section describes Google’s own shift towards the industry trend of microservices, the difficulties that have resulted, and what it means for SRE. Google implements a robust site reliability program which employs a small army of SREs who support some of the company’s most critical systems and engage with engineering teams to improve the reliability of their products and services. The model described in the book has proven to be highly effective for Google but is also quite resource-intensive. Microservices only serve to multiply this problem. The organizations we see attempting to adopt microservices along with SRE, particularly those who are doing it as a part of a move to cloud, frequently underestimate just how much it’s about to ruin their day in terms of thinking about software development and operations.
It is not going from a monolith to a handful of microservices. It ends up being hundreds of services or more, even for the smaller companies. This happens every single time. And that move to microservices—in combination with cloud—unleashes a whole new level of autonomy and empowerment for developers who, often coming from a more restrictive ops-controlled environment on prem, introduce all sorts of new programming languages, compute platforms, databases, and other technologies. The move to microservices and cloud is nothing short of a Cambrian Explosion for just about every organization that attempts it. I have never seen this not play out to some degree, and it tends to be highly disruptive. Some groups handle it well—others do not. Usually, however, this brings an organization’s delivery to a grinding halt as they try to get a handle on the situation. In some cases, I’ve seen it take a year or more for a company to actually start delivering products in the cloud after declaring they are “all in” on it. And that’s just the process of starting to deliver, not actually delivering them.
How does this relate to SRE? In the book, Google says a result of moving towards microservices is that both the number of requests for SRE support and the cardinality of services to support have increased dramatically. Because each service has a base fixed operational cost, even simple services demand more staffing. Additionally, microservices almost always imply an expectation of lower lead time for deployment. This is invariably one of the reasons we see organizations adopting them in the first place. This reduced lead time was not possible with the Production Readiness Review model they describe earlier in chapter 32 because it had a lead time of months. For many of the organizations we work with, a lead time of months to deliver new products and capabilities to their customers is simply not viable. It would be like rewinding the clock to when they were still operating on prem and completely defeat the purpose of microservices and cloud.
But here’s the key excerpt from the book: “Hiring experienced, qualified SREs is difficult and costly. Despite enormous effort from the recruiting organization, there are never enough SREs to support all the services that need their expertise.” The authors conclude, “the SRE organization is responsible for serving the needs of the large and growing number of development teams that do not already enjoy direct SRE support. This mandate calls for extending the SRE support model far beyond the original concept and engagement model.”
Even Google, who has infinite money and an endless recruiting pipeline, says the SRE model—as it is often described by the people we encounter referencing the book—does not scale with microservices. Instead, they go on to describe a more tractable, framework-oriented model to address this through things like codified best practices, reusable solutions, standardization of tools and patterns, and, more generally, what I describe as the “productization” of infrastructure and operations.
Google enforces standards and opinions around things like programming languages, instrumentation and metrics, logging, and control systems surrounding traffic and load management. The alternative to this is the Cambrian Explosion I described earlier. The authors enumerate the benefits of this approach such as significantly lower operational overhead, universal support by design, faster and lower overhead SRE engagements, and a new engagement model based on shared responsibility rather than either full SRE support or no SRE support. As the authors put it, “This model represents a significant departure from the way service management was originally conceived in two major ways: it entails a new relationship model for the interaction between SRE and development teams, and a new staffing model for SRE-supported service management.”
For some reason, this little detail gets lost and, consequently, we see groups attempting to throw people at the problem, such as embedding an SRE on each team. In practice, this usually means two things: 1) hiring a whole bunch of SREs—which even Google admits to being difficult and costly—and 2) this person typically just becomes the “whipping boy” for the team. More often than not, this individual is some poor ops person who gets labeled “SRE.”
With microservices, which again almost always hit you with a near-exponential growth rate once you adopt them, you simply cannot expect to have a handful of individuals who are tasked with understanding the entirety of a microservice-based platform and be responsible for it. SRE does not mean developers get to just go back to thinking about code and features. Microservices necessitate developers having skin in the game, and even Google has talked about the challenges of scaling a traditional SRE model and why a different tack is needed.
“The constant growth in the number of services at Google means that most of these services can neither warrant SRE engagement nor be maintained by SREs. Regardless, services that don’t receive full SRE support can be built to use production features that are developed and maintained by SREs. This practice effectively breaks the SRE staffing barrier. Enabling SRE-supported production standards and tools for all teams improves the overall service quality across Google.”
My advice is to stop thinking about SRE as an implementation specifically and instead think about the problems it’s solving a bit more abstractly. It’s unlikely your organization has Google-level resources, so you need to consider the constraints. You need to think about the roles and responsibilities of developers as well as your ops folks. They will change significantly with microservices and cloud out of necessity. You’ll need to think about how to scale DevOps within your organization and, as part of that, what “DevOps” actually means to your organization. In fact, many groups are probably better off simply removing “SRE” and “DevOps” from their vocabulary altogether because they often end up being distracting buzzwords. For most mid-to-large-sized companies, some sort of framework- and platform- oriented model is usually needed, similar to what Google describes.
I’ve seen it over and over. This hits companies like a ton of bricks. It requires looking at some hard org problems. A lot of self-reflection that many companies find uncomfortable or just difficult to do. But it has to be done. It’s also an important piece of context when applying the SRE book. Don’t skip over chapter 32. It might just be the most important part of the book.
Real Kinetic helps clients build great engineering organizations. Learn more about working with us.
Real Kinetic often works with companies just beginning their cloud journey. Many come from a conventional on-prem IT organization, which typically looks like separate development and IT operations groups. One of the main challenges we help these clients with is how to structure their engineering organizations effectively as they make this transition. While we approach this problem holistically, it can generally be looked at as two components: product development and infrastructure. One might wonder if this is still the case with the shift to DevOps and cloud, but as we’ll see, these two groups still play important and distinct roles.
We help clients understand and embrace the notion of a product mindset as it relates to software development. This is a fundamental shift from how many of these companies have traditionally developed software, in which development was viewed as an IT partner beholden to the business. This transformation is something I’ve discussed at length and will not be the subject of this conversation. Rather, I want to spend some time talking about the other side of the coin: operations.
Operations in the Cloud
While I’ve talked about operations in the context of cloud before, it’s only been in broad strokes and not from a concrete, organizational perspective. Those discussions don’t really get to the heart of the matter and the question that so many IT leaders ask: what does an operations organization look like in the cloud?
This, of course, is a highly subjective question to which there is no “right” answer. This is doubly so considering that every company and culture is different. I can only humbly offer my opinion and answer with what I’ve seen work in the context of particular companies with particular cultures. Bear this in mind as you think about your own company. More often than not, the cultural transformation is more arduous than the technology transformation.
I should also caveat that—outside of being a strategic instrument—Real Kinetic is not in the business of simply helping companies lift-and-shift to the cloud. When we do, it’s always with the intention of modernizing and adapting to more cloud-native architectures. Consequently, our clients are not usually looking to merely replicate their current org structure in the cloud. Instead, they’re looking to tailor it appropriately.
Defining Lines of Responsibility
What should developers need to understand and be responsible for? There tend to be two schools of thought at two different extremes when it comes to this depending on peoples’ backgrounds and experiences. Oftentimes, developers will want more control over infrastructure and operations, having come from the constraints of a more siloed organization. On the flip side, operations folks and managers will likely be more in favor of having a separate group retain control over production environments and infrastructure for various reasons—efficiency, stability, and security to name a few. Not to mention, there are a lot of operational concerns that many developers are likely not even aware of—the sort of unsung, unglamorous bits of running software.
Ironically, both models can be used as an argument for “DevOps.” There are also cases to be made for either. The developer argument is better delivery velocity and innovation at a team level. The operations argument is better stability, risk management, and cost control. There’s also likely more potential for better consistency and throughput at an organization level.
The answer, unsurprisingly, is a combination of both.
There is an inherent tension between empowering developers and running an efficient organization. We want to give developers the flexibility and autonomy they need to develop good solutions and innovate. At the same time, we also need to realize the operational efficiencies that common solutions and standardization provide in order to benefit from economies of scale. Should every developer be a generalist or should there be specialists?
Real Kinetic helps clients adopt a model we refer to as “Developer Enablement.” The idea of Developer Enablement is shifting the focus of ops teams from being “masters” of production to “enablers” of production by applying a product lens to operations. In practical terms, this means less running production workloads on behalf of developers and more providing tools and products that allow developers to run workloads themselves. It also means thinking of operations less as a task-driven service model and more as a strategic enabler. However, Developer Enablement is not about giving full autonomy to developers to do as they please, it’s about providing the abstractions they need to be successful on the platform while realizing the operational efficiencies possible in a larger organization. This means providing common tooling, products, and patterns. These are developed in partnership with product teams so that they meet the needs of the organization. Some companies might refer to this as a “platform” team, though I think this has a slightly different meaning. So how does this map to an actual organization?
Mapping Out an Engineering Organization
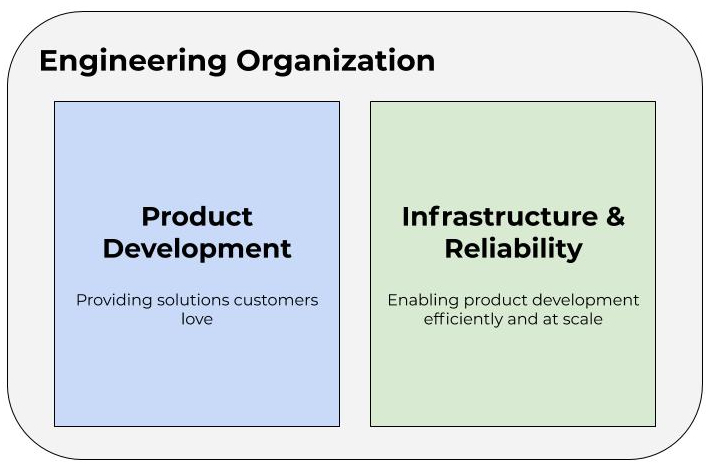
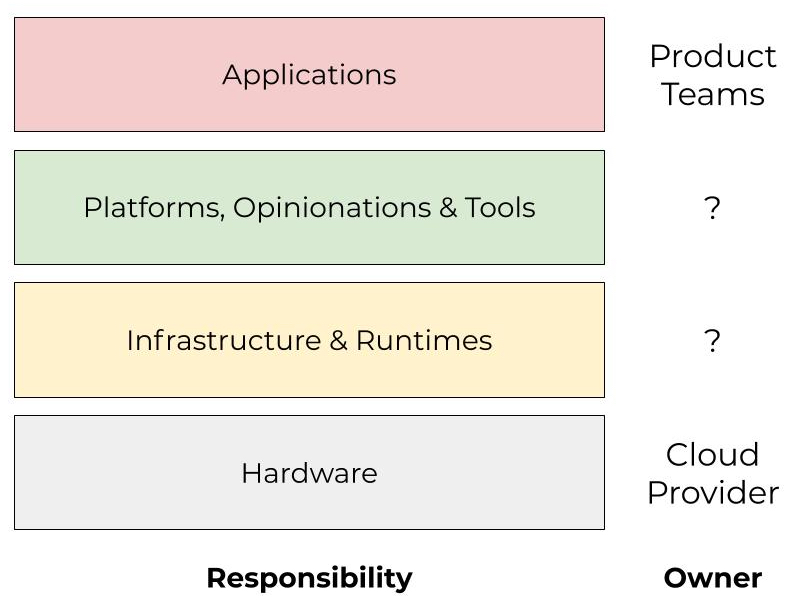
First, let’s mentally model our engineering organization as two groups: Product Development and Infrastructure and Reliability. The first is charged with developing products for end users and customers. This is the stuff that makes the business money. The second is responsible for supporting the first. This is where the notion of “developer enablement” comes into play. And while this group isn’t necessarily doing work that is directly strategic to the business, it is work that is critical to providing efficiencies and keeping the lights on just the same. This would traditionally be referred to as Operations.
As mentioned above, the focus of this discussion is the green box. And as you might infer from the name, this group is itself composed of two subgroups. Infrastructure is about enabling product teams, and Reliability is about providing a first line of defense when it comes to triaging production incidents. This latter subgroup is, in and of itself, its own post and worthy of a separate discussion, so we’ll set that aside for another day. We are really focused on what a cloud infrastructure organization might look like. Let’s drill down on that piece of the green box.
An Infrastructure Organization Model
When thinking about organization structure, I find that it helps to consider layers of operational concern while mapping the ownership of those concerns. The below diagram is an example of this. Note that these do not necessarily map to specific team boundaries. Some areas may have overlap, and responsibilities may also shift over time. This is mostly an exercise to identify key organizational needs and concerns.
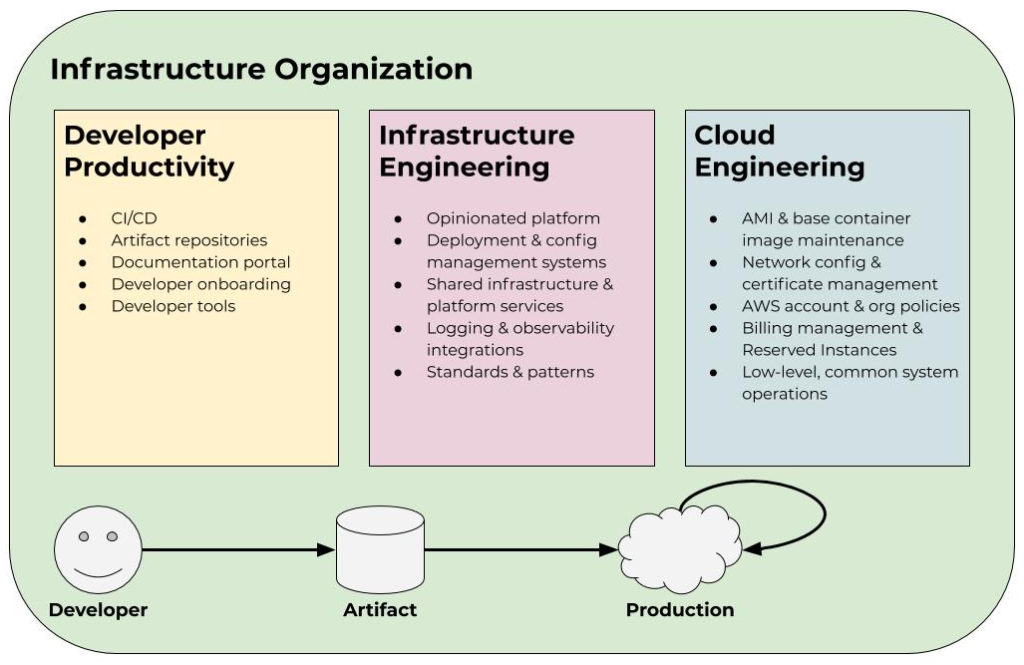
We like to model the infrastructure organization as three teams: Developer Productivity, Infrastructure Engineering, and Cloud Engineering. Each team has its own charter and mission, but they are all in support of the overarching objective of enabling product development efficiently and at scale. In some cases, these teams consist of just a handful of engineers, and in other cases, they consist of dozens or hundreds of engineers depending on the size of the organization and its needs. These team sizes also change as the priorities and needs of the company evolve over time.
Developer Productivity
Developer Productivity is tasked with getting ideas from an engineer’s brain to a deployable artifact as efficiently as possible. This involves building or providing solutions for things like CI/CD, artifact repositories, documentation portals, developer onboarding, and general developer tooling. This team is primarily an engineering spend multiplier. Often a small Developer Productivity team can create a great deal of leverage by providing these different tools and products to the organization. Their core mandate is reducing friction in the delivery process.
Infrastructure Engineering
The Infrastructure Engineering team is responsible for making the process of getting a deployable artifact to production and managing it as painless as possible for product teams. Often this looks like providing an “opinionated platform” on top of the cloud provider. Completely opening up a platform such as AWS for developers to freely use can be problematic for larger organizations because of cost and time inefficiencies. It also makes security and compliance teams’ jobs much more difficult. Therefore, this group must walk the fine line between providing developers with enough flexibility to be productive and move fast while ensuring aggregate efficiencies to maintain organization-wide throughput as well as manage costs and risk. This can look like providing a Kubernetes cluster as a service with opinions around components like load balancing, logging, monitoring, deployments, and intra-service communication patterns. Infrastructure Engineering should also provide tooling for teams to manage production services in a way that meets the organization’s regulatory requirements.
The question of ownership is important. In some organizations, the Infrastructure Engineering team may own and operate infrastructure services, such as common compute clusters, databases, or message queues. In others, they might simply provide opinionated guard rails around these things. Most commonly, it is a combination of both. Without this, it’s easy to end up with every team running their own unique messaging system, database, cache, or other piece of infrastructure. You’ll have lots of architecture astronauts on your hands, and they will need to be able to answer questions around things like high availability and disaster recovery. This leads to significant inefficiencies and operational issues. Even if there isn’t shared infrastructure, it’s valuable to have an opinionated set of technologies to consolidate institutional knowledge, tooling, patterns, and practices. This doesn’t have to act as a hard-and-fast rule, but it means teams should be able to make a good case for operating outside of the guard rails provided.
This model is different from traditional operations in that it takes a product-mindset approach to providing solutions to internal customers. This means it’s important that the group is able to understand and empathize with the product teams they serve in order to identify areas for improvement. It also means productizing and automating traditional operations tasks while encouraging good patterns and practices. This is a radical departure from the way in which most operations teams normally operate. It’s closer to how a product development team should work.
This group should also own standards around things like logging and instrumentation. These standards allow the team to develop tools and services that deal with this data across the entire organization. I’ve talked about this notion with the Observability Pipeline.
Cloud Engineering
Cloud Engineering might be closest to what most would consider a conventional operations team. In fact, we used to refer to this group as Cloud Operations but have since moved away from that vernacular due to the connotation the word “operations” carries. This group is responsible for handling common low-level concerns, underlying subsystems management, and realizing efficiencies at an aggregate level. Let’s break down what that means in practice by looking at some examples. We’ll continue using AWS to demonstrate, but the same applies across any cloud provider.
One of the low-level concerns this group is responsible for is AMI and base container image maintenance. This might be the AMIs used for Kubernetes nodes and the base images used by application pods running in the cluster. These are critical components as they directly relate to the organization’s security and compliance posture. They are also pieces most developers in a large organization are not well-equipped to—or interested in—dealing with. Patch management is a fundamental concern that often takes a back seat to feature development. Other examples of this include network configuration, certificate management, logging agents, intrusion detection, and SIEM. These are all important aspects of keeping the lights on and the company’s name out of the news headlines. Having a group that specializes in these shared operational concerns is vital.
In terms of realizing efficiencies, this mostly consists of managing AWS accounts, organization policies (another important security facet), and billing. This group owns cloud spend across the organization and, as a result, is able to monitor cumulative usage and identify areas for optimization. This might look like implementing resource-tagging policies, managing Reserved Instances, or negotiating with AWS on committed spend agreements. Spend is one of the reasons large companies standardize on a single cloud platform, so it’s essential to have good visibility and ownership over this. Note that this team is not responsible for the spend itself, rather they are responsible for visibility into the spend and cost allocations to hold teams accountable.
The unfortunate reality is that if the Cloud Engineering team does their job well, no one really thinks about them. That’s just the nature of this kind of work, but it has a massive impact on the company’s bottom line.
Summary
Depending on the company culture, words like “standards” and “opinionated” might be considered taboo. These can be especially unsettling for developers who have worked in rigid or siloed environments. However, it doesn’t have to be all or nothing. These opinions are more meant to serve as a beaten path which makes it easier and faster for teams to deliver products and focus on business value. In fact, opinionation will accelerate cloud adoption for many organizations, enable creativity on the value rather than solution architecture, and improve efficiency and consistency at a number of levels like skills, knowledge, operations, and security. The key is in understanding how to balance this with flexibility so as to not overly constrain developers.
We like taking a product approach to operations because it moves away from the “ticket-driven” and gatekeeper model that plagues so many organizations. By thinking like a product team, infrastructure and operations groups are better able to serve developers. They are also better able to scale—something that is consistently difficult for more interrupt-driven ops teams who so often find themselves becoming the bottleneck.
Notice that I’ve entirely sidestepped terms like “DevOps” and “SRE” in this discussion. That is intentional as these concepts frequently serve as a distraction for companies who are just beginning their journey to the cloud. There are ideas encapsulated by these philosophies which provide important direction and practices, but it’s imperative to not get too caught up in the dogma. Otherwise, it’s easy to spin your wheels and chase things that, at least early on, are not particularly meaningful. It’s more impactful to focus on fundamentals and finding some success early on versus trying to approach things as town planners.
Moreover, for many companies, the organization model I walked through above was the result of evolving and adapting as needs changed and less of a wholesale reorg. In the spirit of product mindset, we encourage starting small and iterating as opposed to boiling the ocean. The model above can hopefully act as a framework to help you identify needs and areas of ownership within your own organization. Keep in mind that these areas of responsibility might shift over time as capabilities are implemented and added.
Lastly, do not mistake this framework as something that might preclude exploration, learning, and innovation on the part of development teams. Again, opinionation and standards are not binding but rather act as a path of least resistance to facilitate efficiency. It’s important teams have a safe playground for exploratory work. Ideally, new ideas and discoveries that are shown to add value can be standardized over time and become part of that beaten path. This way we can make them more repeatable and scale their benefits rather than keeping them as one-off solutions.
How has your organization approached cloud development? What’s worked? What hasn’t? I’d love to hear from you.
I’ve worked as a software engineer, manager, consultant, and business owner. All of these jobs have involved meetings. What those meetings look like has varied greatly.
As an engineer, meetings typically entailed technical conversations with peers, one-on-ones with managers, and planning meetings or demos with stakeholders.
As a manager, these looked more like quarterly goal-setting with engineering leadership, one-on-ones with direct reports, and decision-making discussions with the team.
As a consultant, my day often consists of talking to clients to provide input and guidance, communicating with partners to develop leads and strategize on accounts, and meeting with sales prospects to land new deals.
As a business owner, I am in conversations with attorneys and accountants regarding legal and financial matters, with advisors and brokers for things like employee benefits and health insurance, and with my co-owner Robert to discuss items relating to business operations.
What I’ve come to realize is this: we suck at meetings. We’re really bad at them. After starting my first job out of college, I quickly discovered that everyone’s just winging it when it comes to meetings. We’re winging it in a way the likes of which Dilbert himself would envy. We’re so bad at it that it’s become a meme in the corporate world. Whether it’s joking about your lack of productivity due to the number of meetings you have or that one meeting that could have been an email, we’ve basically come to terms with the fact that most meetings are just not very good.
And who’s to blame? There’s no science to meetings. It’s not something they teach you in school. Everyone just shows up and sort of finds a system that works—or doesn’t work—for them. What’s most shocking to me, however, is that meetings are one of the most expensive things a business can do—like billions-of-dollars expensive. If you’re going to pay a bunch of people a lot of money to talk to other people who you’re similarly paying a lot of money, you probably want that talking to be worthwhile, right? And yet here we are, jumping from one meeting to the next, unable to even process what was said in the last one. It’s become an inside joke that every company is in on.
But meetings are also important. They’re where collaboration happens, where ideas are born, where decisions are made. Is being “good at meetings” a legitimate hiring criteria? Should it be?
From all of the meetings I’ve had across these different jobs, I’ve learned that the biggest difference throughout is that of the role played in the meeting. In some cases, it’s The Spectator—there mostly to listen and maybe ask questions. In other cases, it’s playing the role of The Advisor—actively participating in the meeting but mostly in the form of offering advice and guidance. Sometimes it’s The Facilitator, who helps move the agenda along, captures notes, and keeps track of action items or decisions. It might be the Decision Maker, who’s there to decide which way to go and be the tie breaker.
Whatever the role, I’ve consistently struggled with how to insert the most value into meetings and extract the most value out of them. This is doubly so when your job revolves around people, which I didn’t recognize until I became a manager and, later, consultant. In these roles, your calendar is usually stacked with meetings, often with different groups of people across many different contexts. A software engineer’s work happens outside of meetings, but for a manager or consultant, it revolves around what gets done during and after meetings. This is true of a lot of other roles as well.
I’ve always had a vague sense for how to do meetings effectively—have a clear purpose or desired outcome, gather necessary context and background information, include an agenda, invite only the people you need, be present and engaged in the discussion, document the action items and decisions, follow up. The problem is I’ve never had a system for doing it that wasn’t just ad hoc and scattered. Also, most of these things happen outside of the conference room or Zoom call, and who has the time to do all of that when your schedule looks like a Dilbert calendar? All of it culminates in a feeling of severe meeting fatigue.
That’s when it occurred to us: what if meetings could be good? Shortly after starting Real Kinetic, we began to explore this question, but the idea had been rattling around our heads long before that. And so we started to develop a solution, first by building a prototype on nights and weekends, then later by investing in it as a full-fledged product. We call it Witful—a note-taking app that connects to your calendar. It’s deceptively simple, but its mission is not: make meetings suck less.
Most calendar and note-taking apps focus on time. After all, what’s the first thing we do when we create a meeting? We schedule it. When it comes to meetings, time is important for logistical purposes—it’s how we know when we need to be somewhere. But the real value of meetings is not time, it’s the people and discussion, decisions, and action items that result. This is what Witful emphasizes by creating a network of all these relationships. It’s less an extension of your notebook and calendar and—forgive the cliche—more like an extension of your brain. It’s a more natural way to organize the information around your work.
We’re still early on this journey, but the product is evolving quickly. We’ve also been clear from the start: Witful isn’t for everyone. If your day is not run by your calendar, it might not be for you. If your role doesn’t center around managing people or maintaining relationships, it might not be for you. Our focus right now is to make you better at meetings. We want to give you the tools and resources you need to conquer your calendar and look good doing it. We use Witful every day to make our consulting work more manageable at Real Kinetic. And while we’re focused on empowering the individual today, our eyes are set towards making teams better at meetings too.
We don’t want to change the way people work, we want to help them do their best work. We want to make meetings suck less. Come join us.