In a previous post, I explained the fundamental competing priorities that companies have when building software: security and governance, maintainability, and speed to production. These three concerns are all in constant tension with each other. For companies either migrating to the cloud or beginning a modernization effort, addressing them can be a major challenge. When you’re unfamiliar with the cloud, building systems that are both secure and maintainable is difficult because you’re not in a position to make decisions that have long-lasting and significant impact—you just don’t know what you don’t know. One small misstep can result in a major security incident. A bad decision can take years to manifest a problem. As a result, these migration and modernization efforts often stall out as analysis paralysis takes hold.
This is where Real Kinetic usually steps in: to get a stuck project moving again, to provide guard rails, and to help companies avoid the hidden landmines by offering our expertise and experience. We’ve been there before, so we help navigate our clients through the foundational decision making, design, and execution of large-scale cloud migrations. We’ve helped migrate systems generating billions of dollars in revenue and hundreds of millions in cloud spend. We’ve also helped customers save tens of millions in cloud spend by guiding them through more cost-effective solution architectures. And while we’ve had a lot of success helping our clients operationalize the cloud, they still routinely ask us: why is it so damn difficult? The truth is it doesn’t have to be if you’re willing to take just a slightly more opinionated stance.
Recently, we introduced Konfig, our solution for this exact problem. Konfig packages up our expertise and years of experience operationalizing and building software in the cloud. More concretely, it’s an enterprise integration of GitLab and Google Cloud that addresses those three competing priorities I mentioned earlier. The reason it’s so difficult for organizations to operationalize GitLab and GCP is because they are robust and flexible platforms that address a broad set of customer needs. As a result, they do not take an opinionated stance on pretty much anything. This leaves a gap unaddressed, and customers are left having to put together their own opinionation that meets their needs—except, they usually aren’t in a position to do this. Thus, they stall.
Konfig gives you a functioning, enterprise-ready GitLab and GCP environment that is secure by default, has strong governance and best practices built-in, and scales with your organization. The best part? You can start deploying production workloads in a matter of minutes. It does this by taking an opinionated stance on some things. It bridges the gap that is unaddressed by Google and GitLab. Those opinions are the recommendations, guidance, and best practices we share with clients when they are operationalizing the cloud.
Perhaps the most obvious opinion is that Konfig is specific to GCP and GitLab. We could extend this model to other platforms like AWS and GitHub, but we chose to focus on building a white-glove experience with GCP and GitLab first because they work together so well. GCP has first-class managed services and serverless offerings which lend themselves to providing a platform that is secure, maintainable, and has a great developer experience. GitLab’s CI/CD is better designed than GitHub Actions and its hierarchical structure maps well to GCP’s resource hierarchy.
Moreover, Konfig embraces service-oriented architecture and domain-driven design which drives how we structure folders and projects in GCP and groups in GitLab. This structure gives us a powerful way to map access management and governance, which we’ll explore later. It’s a best practice that makes systems more maintainable and evolvable. We’ll discuss Konfig’s opinions and their rationale in more depth in a future post. For now, I want to explain how Konfig provides an enterprise platform by addressing each of the three concerns in the software development triangle: security and governance, maintainable infrastructure, and speed to production.
Security and Governance
Access Management
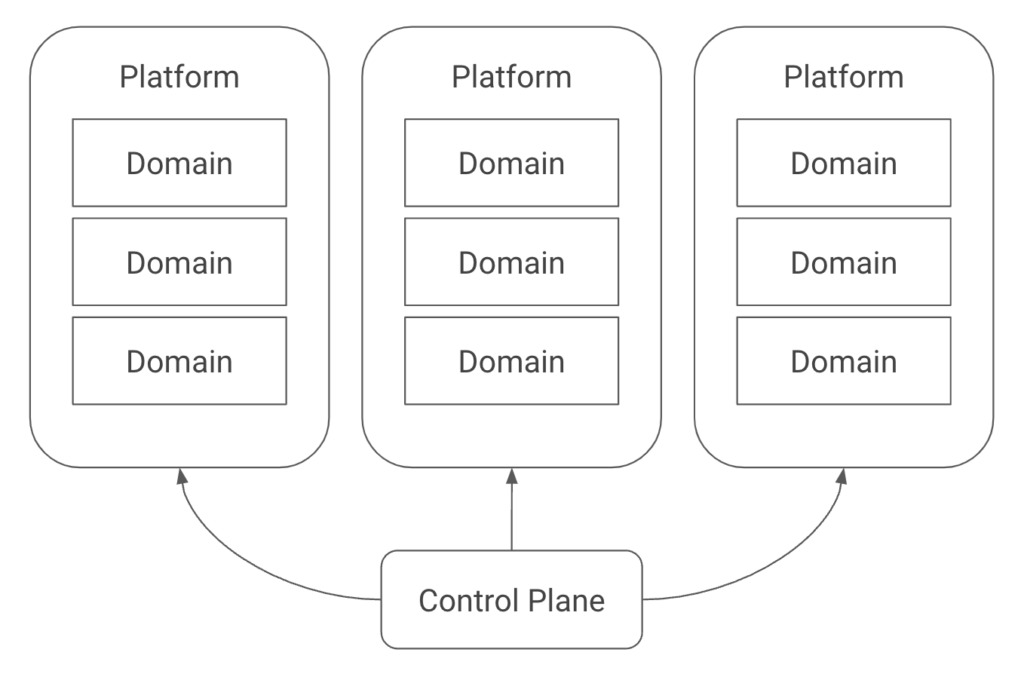
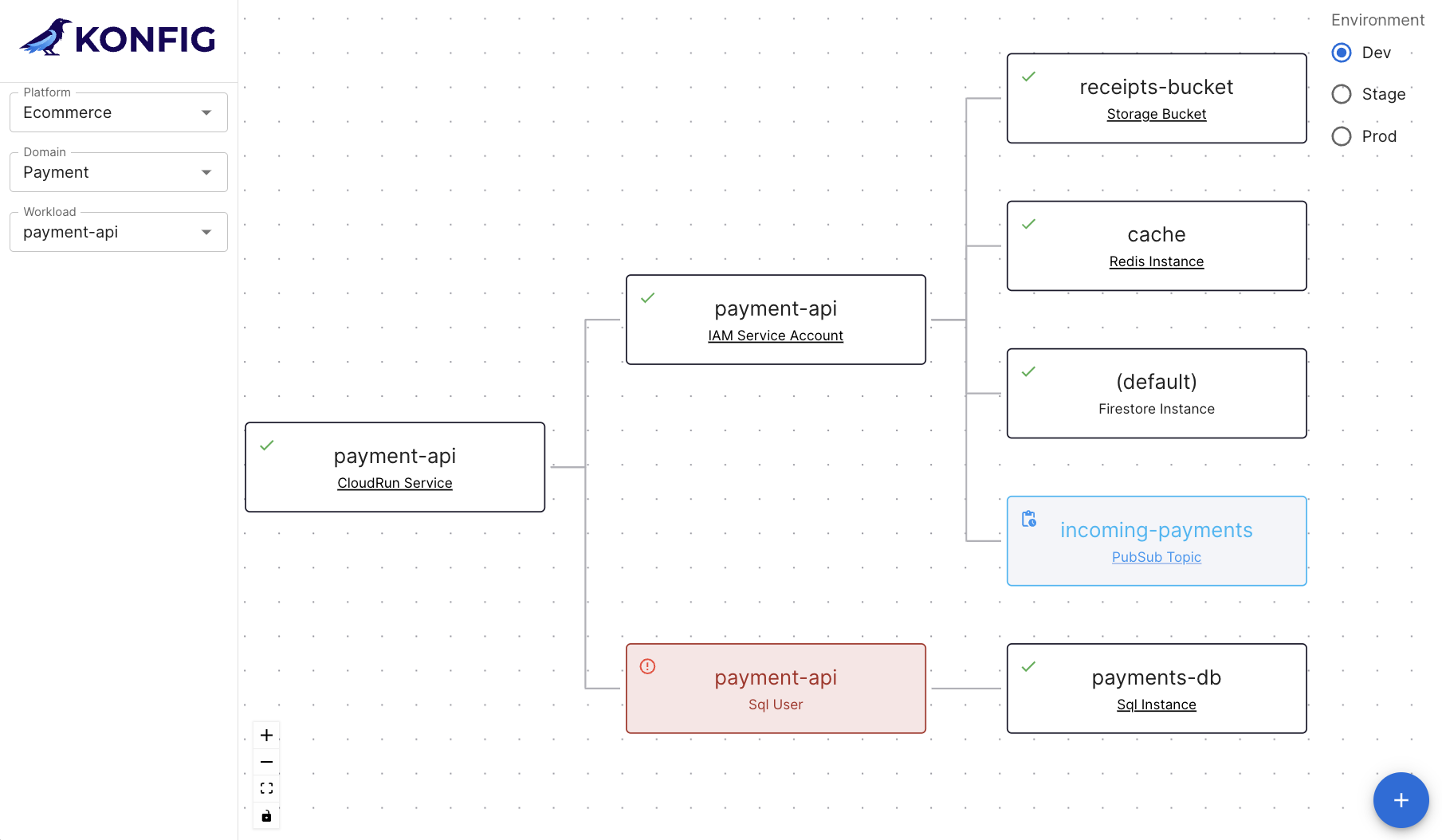
Konfig relies on a hierarchy consisting of control plane > platforms > domains > workloads. The control plane is the top-level container which is responsible for managing all of the resources contained within it. Platforms are used to group different lines of business, product lines, or other organizational units. Domains are a way to group related workloads or services.
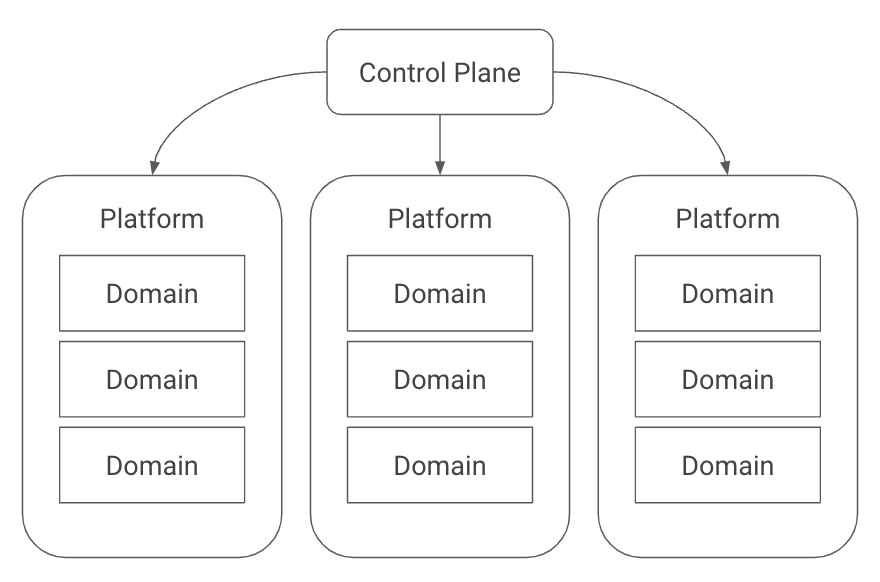
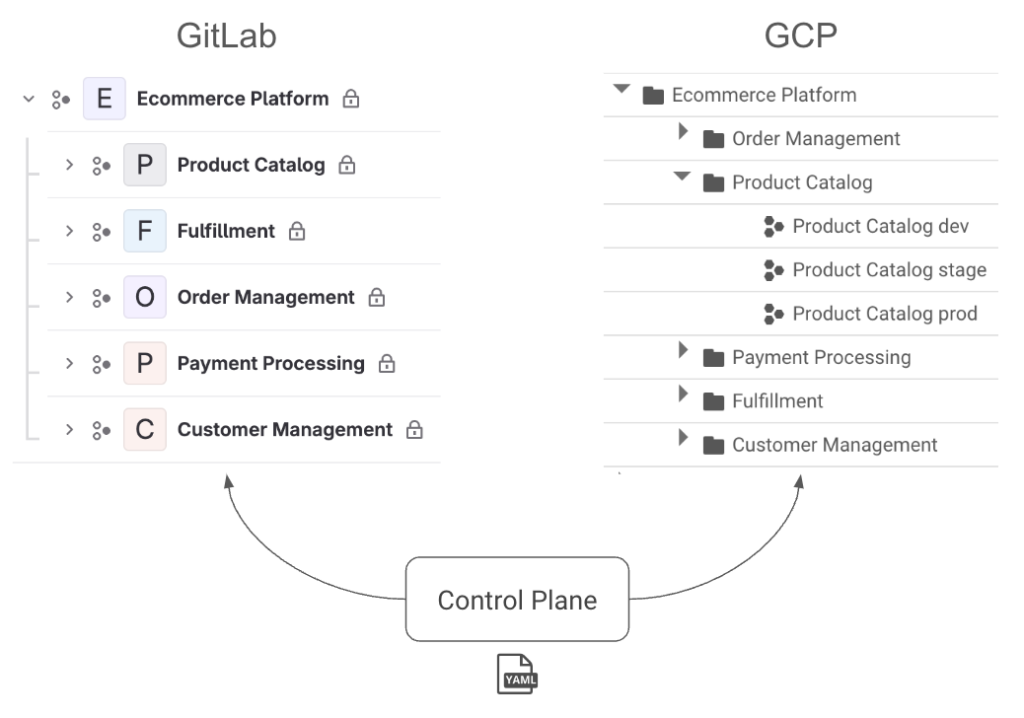
This structure provides several benefits. First, we can map it to hierarchies in both GitLab and GCP, shown in the image below. A platform maps to a group in GitLab and a folder in GCP. A domain maps to a subgroup in GitLab and a nested folder along with a project per environment in GCP.
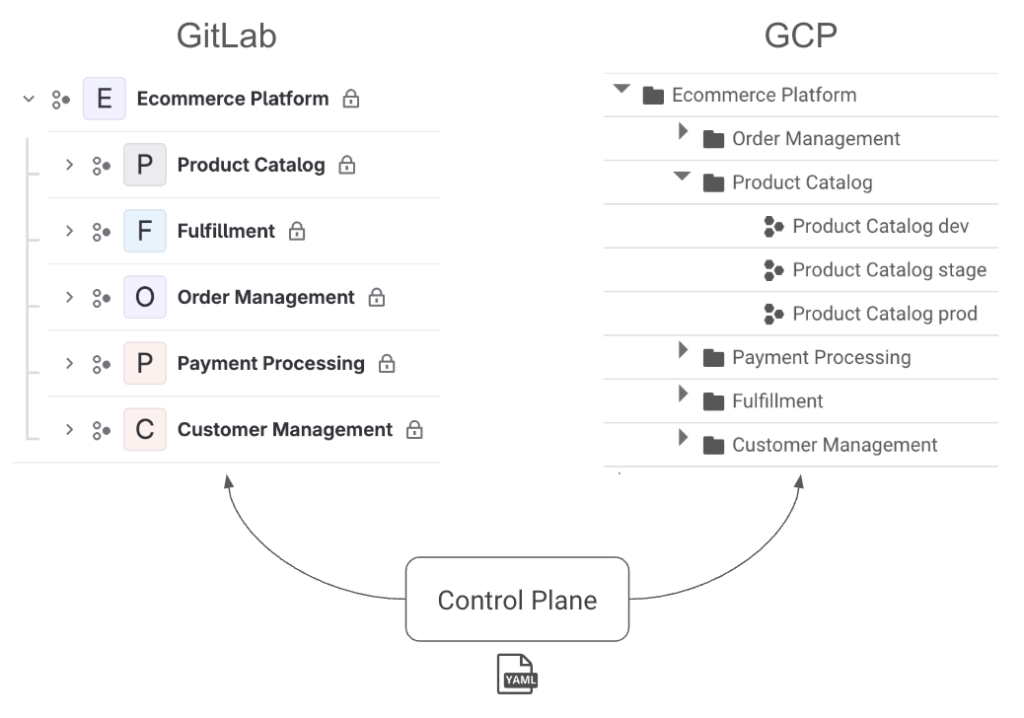
This hierarchy lets us manage permissions cleanly because we can assign access at the control plane, platform, and domain levels. These permissions will be synced to GitLab in the form of SAML group links and to GCP in the form of IAM roles. When a user has “dev” access, they get the Developer role for the respective group in GitLab. In GCP, they get the Editor role for dev environment projects and Viewer for higher environments. “Maintainer” has slightly more elevated access, and “owner” effectively provides root access to allow for a “break-glass” scenario. The hierarchy means these permissions can be inherited by setting them at different levels. This access management is shown in the platform.yaml and domain.yaml examples below highlighted in bold.
apiVersion: konfig.realkinetic.com/v1beta1
kind: Platform
metadata:
name: ecommerce-platform
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/control-plane: konfig-control-plane
spec:
platformName: Ecommerce Platform
groups:
dev: [ecommerce-devs@example.com]
maintainer: [ecommerce-maintainers@example.com]
owner: [ecommerce-owners@example.com]platform.yaml
apiVersion: konfig.realkinetic.com/v1beta1
kind: Domain
metadata:
name: payment-processing
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/platform: ecommerce-platform
spec:
domainName: Payment Processing
groups:
dev: [payment-devs@example.com]
maintainer: [payment-maintainers@example.com]
owner: [payment-owners@example.com]domain.yaml
Authentication and Authorization
There are three different authentication and authorization concerns in Konfig. First, GitLab needs to authenticate with GCP such that pipelines can deploy to the Konfig control plane. Second, the control plane, which runs in a privileged customer GCP project, needs to authenticate with GCP such that it can create and manage cloud resources in the respective customer projects. Third, customer workloads need to be able to authenticate with GCP such that they can correctly access their resource dependencies, such as a database or Pub/Sub topic. The configuration for all of this authentication as well as the proper authorization settings is managed by Konfig. Not only that, but none of these authentication patterns involve any kind of long-lived credentials or keys.
GitLab to GCP authentication is implemented using Workload Identity Federation, which uses OpenID Connect to map a GitLab identity to a GCP service account. We scope this identity mapping so that the GitLab pipeline can only deploy to its respective control plane namespace. For instance, the Payment Processing team can’t deploy to the Fulfillment team’s namespace and vice versa.
Control plane to GCP authentication relies on domain-level service accounts that map a control plane namespace for a domain (let’s say Payment Processing) to a set of GCP projects for the domain (e.g. Payment Processing Dev, Payment Processing Stage, and Payment Processing Prod).
Finally, workloads also rely on service accounts to authenticate and access their resource dependencies. Konfig creates a service account for each workload and sets the proper roles on it needed to access resources. We’ll look at this in more detail next.
This approach to authentication and authorization means there is very little attack surface area. There are no keys to compromise and even if an attacker were to somehow compromise GitLab, such as by hijacking a developer’s account, the blast radius is minimal.
Least-Privilege Access
Konfig is centered around declaratively modeling workloads and their infrastructure dependencies. This is done with the workload.yaml. This lets us spec out all of the resources our service needs like databases, storage buckets, caches, etc. Konfig then handles provisioning and managing these resources. It also handles creating a service account for each workload that has roles that are scoped to only the resources specified by the workload. Let’s take a look at an example.
apiVersion: konfig.realkinetic.com/v1beta1
kind: Workload
metadata:
name: order-api
spec:
region: us-central1
runtime:
kind: RunService
parameters:
template:
containers:
- image: order-api
resources:
- kind: StorageBucket
name: receipts
- kind: SQLInstance
name: order-store
- kind: PubSubTopic
name: order-eventsworkload.yaml
Here we have a simple workload definition for a service called “order-api”. This workload is a Cloud Run service that has three resource dependencies: a Cloud Storage bucket called “receipts”, a Cloud SQL instance called “order-store”, and a Pub/Sub topic called “order-events”. When this YAML definition gets applied by the GitLab pipeline, Konfig will handle spinning up these resources as well as the Cloud Run service itself and a service account for order-api. This service account will have the Pub/Sub Publisher role scoped only to the order-events topic and the Storage Object User role scoped to the receipts bucket. Konfig will also create a SQL user on the Cloud SQL instance whose credentials will be securely stored in Secret Manager and accessible only to the order-api service account. The Konfig UI shows this workload, all of its dependencies, and each resource’s status.
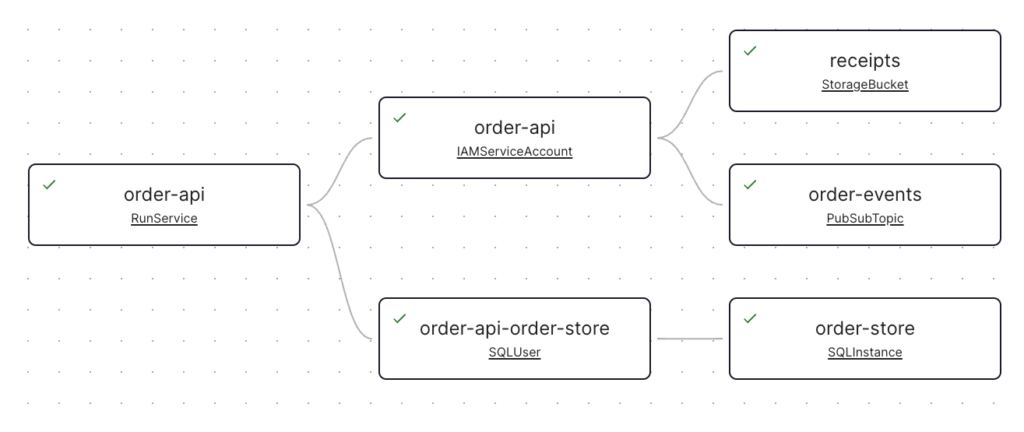
Enforcing Enterprise Standards
After looking at the example workload definition above, you may be wondering: there’s a lot more to creating a storage bucket, Cloud SQL database, or Pub/Sub topic than just specifying its name. Where’s the rest? It’s a good segue into how Konfig offers a means for providing sane defaults and enforcing organizational standards around how resources are configured.
Konfig uses templates to allow an organization to manage either default or required settings on resources. This lets a platform team centrally manage how things like databases, storage buckets, or caches are configured. For instance, our organization might enforce a particular version of PostgreSQL, high availability mode, private IP only, and customer-managed encryption key. For non-production environments, we may use a non-HA configuration to reduce costs. Just like our platform, domain, and workload definitions, these templates are also defined in YAML and managed via GitOps.
We can also take this further and even manage what cloud APIs or services are available for developers to use. Like access management, this is also configured at the control plane, platform, and domain levels. We can specify what services are enabled by default at the platform level which will inherit across domains. We can also disable certain services, for example, at the domain level. The example platform and domain definitions below illustrate this. We enable several services on the Ecommerce platform and restrict Pub/Sub, Memorystore (Redis), and Firestore on the Payment Processing domain.
apiVersion: konfig.realkinetic.com/v1beta1
kind: Platform
metadata:
name: ecommerce-platform
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/control-plane: konfig-control-plane
spec:
platformName: Ecommerce Platform
gcp:
services:
defaults:
- cloud-run
- cloud-sql
- cloud-storage
- secret-manager
- cloud-kms
- pubsub
- redis
- firestoreplatform.yaml
apiVersion: konfig.realkinetic.com/v1beta1
kind: Domain
metadata:
name: payment-processing
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/platform: ecommerce-platform
spec:
domainName: Payment Processing
gcp:
services:
disabled:
- pubsub
- redis
- firestoredomain.yaml
This model provides a means for companies to enforce a “golden path” or an opinionated and supported way of building something within your organization. It’s also a critical component for organizations dealing with regulatory or compliance requirements such as PCI DSS. Even for organizations which prefer to favor developer autonomy, it allows them to improve productivity by setting good defaults so that developers can focus less on infrastructure configuration and more on product or feature development.
SDLC Integration
It’s important to have an SDLC that enables developer efficiency while also providing a sound governance story. Konfig fits into existing SDLCs by following a GitOps model. It allows your infrastructure to follow the same SDLC as your application code. Both rely on a trunk-based development model. Since everything from platforms and domains to workloads is managed declaratively, in code, we can apply typical SDLC practices like protected branches, short-lived feature branches, merge requests, and code reviews.
Even when we create resources from the Konfig UI, they are backed by this declarative configuration. This is something we call “Visual IaC.” Teams who are more comfortable working with a UI can still define and manage their infrastructure using IaC without even having to directly write any IaC. We often encounter organizations who have teams like data analytics, data science, or ETL which are not equipped to deal with managing cloud infrastructure. This approach allows these teams to be just as productive—and empowered—as teams with seasoned infrastructure engineers while still meeting an organization’s SDLC requirements.
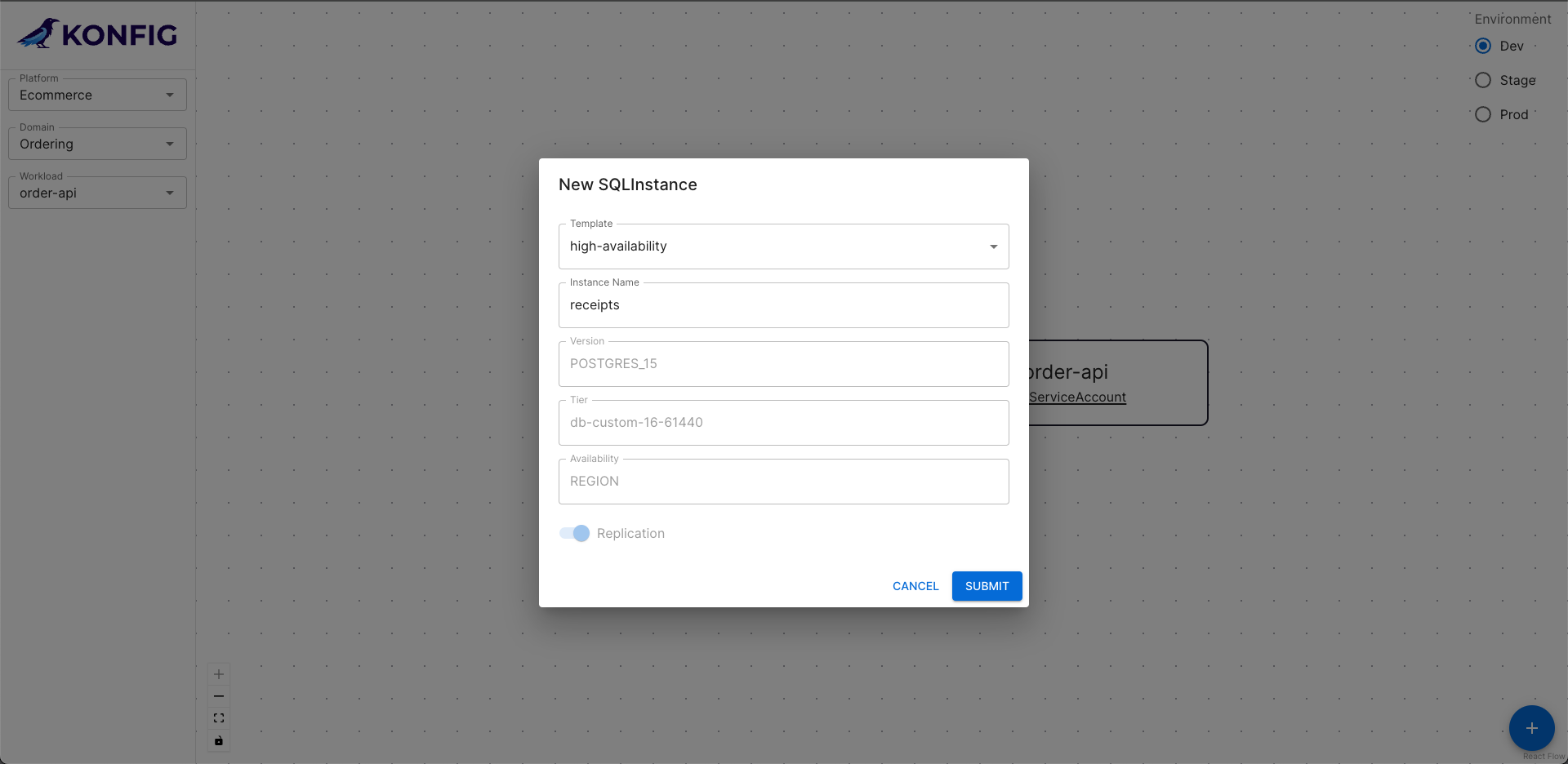
Cost Management
Another key part of governance is having good cost visibility. This can be challenging for organizations because it heavily depends on how workloads and resources are structured in a customer’s cloud environment. If things are structured incorrectly, it can be difficult to impossible to correctly allocate costs across different business units or product areas.
The Konfig hierarchy of platforms > domains > workloads solves this problem altogether because related workloads are grouped into domains and related domains are grouped into platforms. A domain maps to a set of projects, one per environment, which makes it trivial to see what a particular domain costs. Similarly, we can easily see an aggregate cost for an entire platform because of this grouping. The GCP billing account ID is set at the platform level and all projects within a platform are automatically linked to this account. Konfig makes it easy to implement an IT chargeback or showback policy for cloud resource consumption within a large organization.
apiVersion: konfig.realkinetic.com/v1beta1
kind: Platform
metadata:
name: ecommerce-platform
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/control-plane: konfig-control-plane
spec:
platformName: Ecommerce Platform
gcp:
billingAccountId: "123ABC-456DEF-789GHI"platform.yaml
Maintainable Infrastructure
Opinionated Model
We’ve talked about opinionation quite a bit already, but I want to speak to this directly. The reason companies so often struggle to operationalize their cloud environment is because the platforms themselves are unwilling to take an opinionated stance on how customers should solve problems. Instead, they aim to be as flexible and accommodating as possible so they can meet as many customers where they are as possible. But we frequently hear from clients: “just tell me how to do it” or even “can you do it for me?” Many of them don’t want the flexibility, they just want a preassembled solution that has the best practices already implemented. It’s the difference between a pile of Legos with no instructions and an already-assembled Lego factory. Sure, it’s fun to build something yourself and express your creativity, but this is not where most businesses want creativity. They want creativity in the things that generate revenue.
Konfig is that preassembled Lego factory. Does that mean you get to customize and change all the little details of the platform? No, but it means your organization can focus its energy and creativity on the things that actually matter to your customers. With Konfig, we’ve codified the best practices and patterns into a turnkey solution. This more opinionated approach allows us to provide a good developer experience that results in maintainable infrastructure. The absence of creative constraints tends to lead to highly bespoke architectures and solutions that are difficult to maintain, especially at scale. It leads to a great deal of inefficiency and complexity.
Architectural Standards
Earlier we saw how Konfig provides a powerful means for enforcing enterprise standards and sane defaults for infrastructure as well as how we can restrict the use of certain services. While we looked at this in the context of governance, it’s also a key ingredient for maintainable infrastructure. Organizational standards around infrastructure and architecture improve efficiency and maintainability for the same reason the opinionation we discussed above does. Konfig’s templating model and approach to platforms and domains effectively allows organizations to codify their own internal opinions.
Automatic Reconciliation
There are a number of challenges with traditional IaC tools like Terraform. One such challenge is the problem of state management and drift. A resource managed by Terraform might be modified outside of Terraform which introduces a state inconsistency. This can range from something simple like a single field on a resource to something very complex, such as an entire application stack. Resolving drift can sometimes be quite problematic. Terraform works by storing its configuration in a state file. Aside from the problem that the state file often contains sensitive information like passwords and credentials, the Terraform state is applied in a “one-off” fashion. That is to say, when the Terraform apply command is run, the current state configuration is applied to the environment. At this point, Terraform is no longer involved until the next time the state is applied. It could be hours, days, weeks, or longer between applies.
Konfig uses a very different model. In particular, it regularly reconciles the infrastructure state automatically. This solves the issue of state drift altogether since infrastructure is no longer applied as “one-off” events. Instead, it treats infrastructure the way it actually is—a living, breathing thing—rather than a single, point-in-time snapshot.
Speed to Production
Turnkey Setup
Our goal with Konfig is to provide a fully turnkey experience, meaning customers have a complete and enterprise-grade platform with little-to-no setup. This includes setup of the platform itself, but also setup of new workloads within Konfig. We want to make it as easy and frictionless as possible for organizations to start shipping workloads to production. It’s common for a team to build a service that is code complete but getting it deployed to various environments takes weeks or even months due to the different organizational machinations that need to occur first. With Konfig, we start with a workload deploying to an environment. You can use our workload template in GitLab to create a new workload project and deploy it to a real environment in a matter of minutes. The CI/CD pipeline is already configured for you. Then you can work backwards and start adding your code and infrastructure resources. We call this “Deployment-Driven Development.”
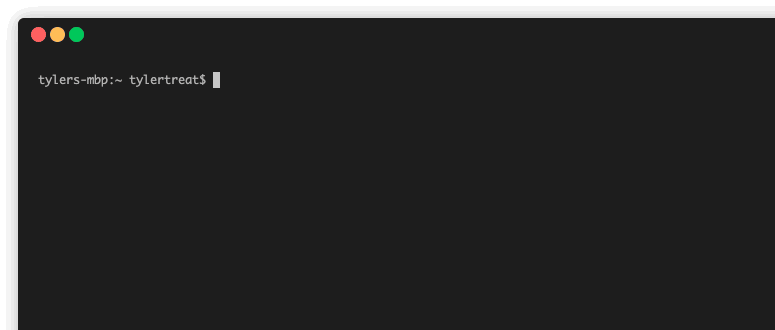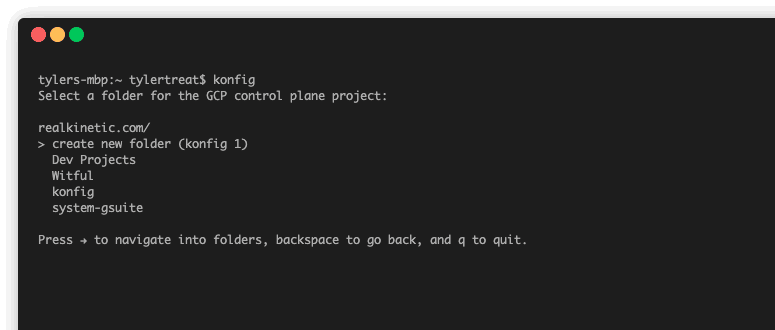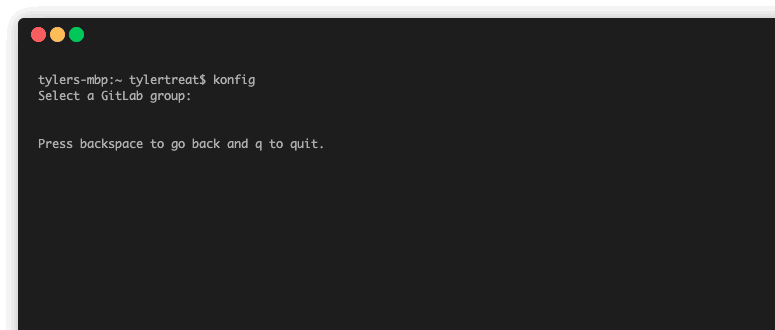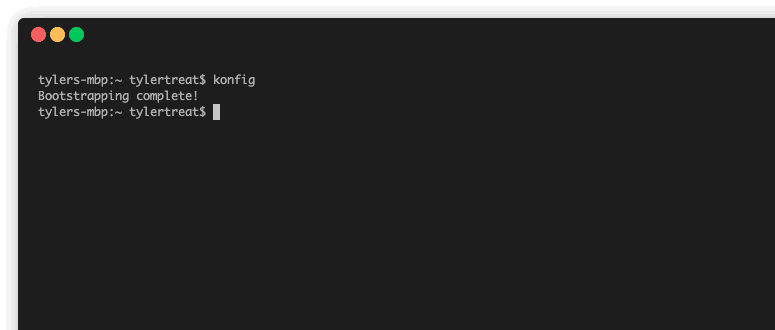
Konfig works by using a control plane which lives in a customer GCP project. The setup of this control plane is fully automated using the Konfig CLI. When you run the CLI bootstrap command, it will run through a guided wizard which sets up the necessary resources in both GitLab and GCP. After this runs, you’ll have a fully functioning enterprise platform.
Workload Autowiring
We saw earlier how workloads declaratively specify their infrastructure resources (something we call resource claims) and how Konfig manages a service account with the correctly scoped, minimal set of permissions to access those resources. For resources that use credentials, such as Cloud SQL database users, Konfig will manage these secrets by storing them in GCP’s Secret Manager. Only the workload’s service account will be able to access this. This secret gets automatically mounted onto the workload. Resource references, such as storage bucket names, Pub/Sub topics, or Cloud SQL connections, will also be injected into the workload to make it simple for developers to start consuming these resources.
API Ingress and Path-Based Routing
Konfig makes it easy to control the ingress of services. We can set a service such that it is only accessible within a domain, within a platform, or within a control plane. We can even control which domains can access an API. Alternatively, we can expose a service to the internet. Konfig uses a path-based routing scheme which maps to the platform > domain > workload hierarchy. Let’s take a look at an example platform, domain, and workload configuration.
apiVersion: konfig.realkinetic.com/v1beta1
kind: Platform
metadata:
name: ecommerce-platform
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/control-plane: konfig-control-plane
spec:
platformName: Ecommerce Platform
gcp:
api:
path: /ecommerceplatform.yaml
apiVersion: konfig.realkinetic.com/v1beta1
kind: Domain
metadata:
name: payment-processing
namespace: konfig-control-plane
labels:
konfig.realkinetic.com/platform: ecommerce-platform
spec:
domainName: Payment Processing
gcp:
api:
path: /paymentdomain.yaml
apiVersion: konfig.realkinetic.com/v1beta1
kind: Workload
metadata:
name: authorization-service
spec:
region: us-central1
runtime:
kind: RunService
parameters:
template:
containers:
- image: authorization-service
api:
path: /authworkload.yaml
Note the API path component in the above configurations. Our ecommerce platform specifies /ecommerce as its path, the payment-processing domain specifies /payment, and the authorization-service workload specifies /auth. The full route to hit the authorization-service would then be /ecommerce/payment/auth. We’ll explore API ingress and routing in more detail in a later post.
An Enterprise-Ready Workload Delivery Platform
We’ve looked at a few of the ways Konfig provides a compelling enterprise integration of GitLab and Google Cloud. It addresses a gap these products leave by not offering strong opinions to customers. Konfig allows us to package up the best practices and patterns for implementing a production-ready workload delivery platform and provide that missing opinionation. It tackles three competing priorities that arise when building software: security and governance, maintainable infrastructure, and speed to production. Konfig plays a strategic role in reducing the cost and improving the efficiency of cloud migration, modernization, and greenfield efforts. Reach out to learn more about Konfig or schedule a demo.
Follow @tyler_treat