Like most industry jargon, “DevOps” means a lot of things to a lot of different people. While many folks view it as specific to certain tooling or practices, such as CI/CD or Infrastructure as Code (IaC), I’ve always viewed it as an organizational model for how software is built and delivered. In particular, my interpretation is that DevOps is about shifting more responsibilities “left” onto developers, moving away from the more traditional “throw it over the wall” approach to IT operations. No doubt this encompasses tooling or practices like CI/CD and IaC, which are responsibilities that developers now shoulder, perhaps with the support of dev tools, productivity, or enablement teams—some companies just call this the “DevOps” team.
While many organizations still operate with the traditional silos, DevOps has established itself as an industry norm. But as organizations push the boundaries of software development, the limitations of DevOps are becoming increasingly apparent. The problem is that DevOps, in its pursuit of speed and autonomy, often results in chaos and inefficiency. Teams end up reinventing the wheel, creating bespoke solutions for the same problems, and struggling with inconsistent tooling and practices across the organization. The outcome? Technical debt, fragmented processes, and wasted effort. Many of the teams we work with at Real Kinetic spend significantly more time on the “DevOps work” than they do on actual product work.
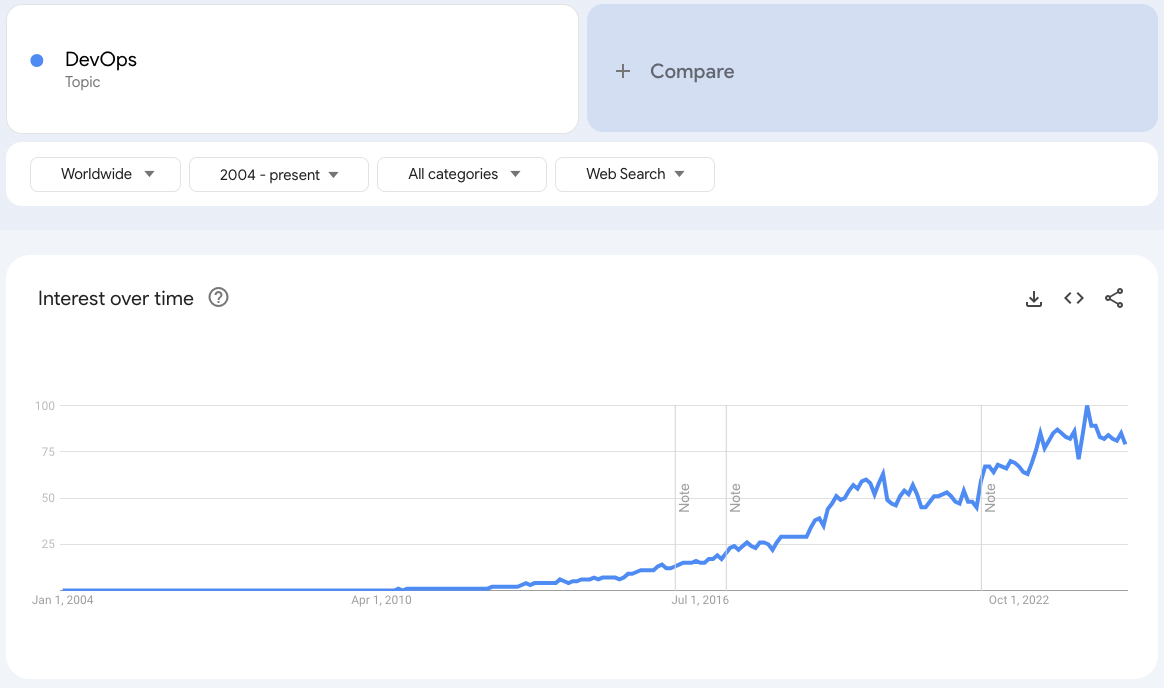
Google Trends for “DevOps”
The Rise of Platform Engineering
This is where Platform Engineering comes in. Rather than having each development team own their entire infrastructure stack, platform engineering provides a centralized, productized approach to infrastructure and developer tools. It’s about creating reusable, self-service platforms that development teams can leverage to build, deploy, and scale their applications efficiently. These platforms abstract away the complexities of cloud infrastructure, CI/CD pipelines, and security, enabling developers to focus on writing code rather than managing infrastructure or “glue”.
Platform engineering brings structure to the chaos of DevOps by creating a standardized, cohesive platform that empowers development teams while maintaining best practices and governance. It’s a solution to the growing complexity and sprawl that comes with scaling software delivery and scaling DevOps. Platform engineering is very much in its infancy as DevOps was circa 2012, but there’s growing interest in it as organizations hit the ceiling of DevOps.
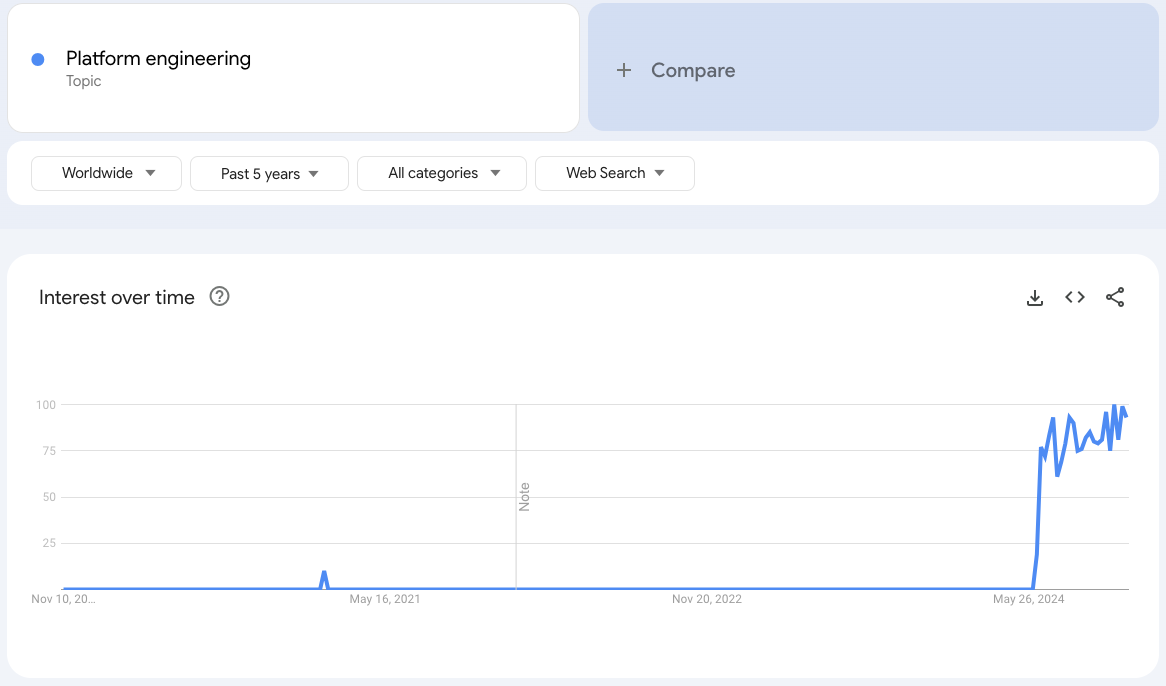
Google Trends for “Platform Engineering”
But There’s a Catch: The Investment Barrier
Implementing platform engineering isn’t without its challenges. Building a robust, scalable platform requires significant time, resources, and expertise. It demands a deep understanding of your organization’s technology stack, development workflows, and business objectives. And importantly, it diverts valuable resources away from core product development efforts.
Many organizations are hesitant to make this level of investment, especially if it’s not their core competency. They either end up doing it poorly—leading to a half-baked platform that doesn’t deliver the promised efficiencies—or they avoid it altogether, sticking to the DevOps status quo. This often leaves them with the worst of both worlds: the overhead of DevOps without the benefits of a streamlined, developer-friendly platform.
What we most often see are dev tools teams masquerading as platform engineering.As Camille Fournier puts it, they build scripts or tools around configuration management and infrastructure provisioning, not products. Usually it’s because they either don’t want to have skin in the game or they don’t have a mandate from leadership. “Not having skin in the game” means some combination of these things: a) they don’t want to build their own software, b) they don’t want to be on the hook for operations, or c) they don’t want to be in the critical path for production or become a bottleneck. Instead, they provide “blueprints” for these things and the burden and responsibility ultimately falls on the product teams—this is just DevOps.
Another issue is that organizations don’t want to allocate the headcount to do real platform engineering. They’re not wrong to be hesitant because it takes real investment to actually do it. As a result, however, they take half measures. We frequently see companies take an InnerSource approach as an attempt to basically socialize platform engineering. I have never seen this approach work well in practice unless there’s clear ownership and the team has a clear mandate. And just as before, this approach pushes scripts, not products. Without ownership and directive, it just reverts back to DevOps which leads to inefficiency and sprawl.
The Solution: Platform Engineering as a Service
This is where Platform Engineering as a Service (PEaaS) comes in. Unlike traditional Platform as a Service (PaaS) offerings, which provide a rigid, one-size-fits-all platform that abstracts away the underlying infrastructure, PEaaS is designed to be flexible and tailored to your unique requirements. It doesn’t hide the infrastructure but rather empowers your teams by providing the tools, automation, and best practices needed to build and operate cloud-native applications efficiently for your organization.
Instead of building and maintaining a custom platform internally, organizations can partner with experts who specialize in platform engineering and bring deep, hands-on experience to the table. With PEaaS, you get all the benefits of a mature, scalable platform without the heavy upfront investment or the distraction from your core product development. This means that a robust, enterprise-grade platform can be implemented in a fraction of the time, and managed for a fraction of the cost. What typically takes companies 6 months or more to build can be accomplished in days or weeks. And, what typically takes a team of 5 – 10 engineers working full-time to manage can be handled by 1 engineer, often on a part-time basis.
At Real Kinetic, we’ve been helping organizations accelerate their software delivery for years. In fact, we’ve been doing platform engineering long before it was called platform engineering. We bring our extensive expertise in cloud infrastructure, CI/CD, and developer enablement to build platforms that align with your organization’s unique needs and technology stack. By leveraging our Platform Engineering as a Service, you can stay focused on what you do best—building great products—while we take care of the complexities of infrastructure, automation, and developer tooling.
Why Real Kinetic?
Why should you trust us with your platform engineering needs? Because we’ve done it before, time and time again. Real Kinetic has helped numerous organizations—from startups to large enterprises—modernize their software delivery practices, improve developer productivity, and accelerate time to market. Our approach is rooted in real-world experience, not theory. We understand the challenges of scaling platforms because we’ve been there ourselves.
When you partner with Real Kinetic, you’re not just getting a service provider—you’re getting a team of experts who are invested in your success and have skin in the game. We’re here to build a platform that scales with your business, optimizes your development workflows, and ultimately drives more value for your customers.
Ready to Level Up Your Software Delivery?
If you’re tired of the inefficiencies of DevOps and ready to embrace the power of platform engineering, let’s talk. Real Kinetic’s Platform Engineering as a Service is your fast track to a scalable, efficient platform that empowers your developers and accelerates your time to market. And if you’re using AWS or GCP, we’re also looking for a few companies to pilot our batteries-included platform engineering product Konfigurate.
Most people use “DDD” to refer to Domain-Driven Design, which is a useful tool for thinking about API boundaries and system architecture. It provides a way to map a business problem into software. At Real Kinetic, we regularly help our clients utilize Domain-Driven Design as well as other strategies to architect their systems, avoid some of the pitfalls of DDD, and build an effective foundation for designing software. But this DDD only speaks to one small aspect of building and shipping software.
Software architecture is critical to a number of concerns like scalability, adaptability, and speed-to-market for new products and features, but its effects are usually not felt for some time—weeks, months, even years later. These delayed effects are lagging indicators that reveal how “well” a system was architected (I use quotes here because this is really quite subjective and relative to both the short- and long-term needs of the business). Other lagging indicators also highlight problems in software development. For instance, a high number of reported bugs may point to deficiencies in QA and testing processes, while the volume or severity of findings in an audit may signal issues in security, compliance, or SDLC practices. Similarly, accumulated tech debt may reflect deeper systemic issues.
These lagging indicators often result from a delayed and reactive approach to managing concerns like security, compliance, quality, and even architecture. These concerns are frequently deferred to later stages in the development process or left to evolve on their own organically. It’s not uncommon for us to see teams complete the development of a product or feature, only to spend months navigating the hurdles to get it into production. It may be testing or production-readiness processes, integration challenges, infrastructure issues, change-review boards, or a combination of all of these. One way or another, it takes many teams inordinately long to go from idea to in-customer’s-hands.
Through our work consulting with startups, scaleups, and Fortune 500 companies to improve their product delivery, we’ve been building a solution to this problem called Konfigurate. But before diving into that, I want to introduce you to the other DDD—Deployment-Driven Development—and why it’s critical to improving delivery, how it relates to platform engineering, and how it can be implemented.
Shift Left
The act of scaling a product—that is to say, going from prototype to production and beyond—takes focus off the product itself. This is because there is a whole host of undifferentiated work that is needed at various stages of a product’s lifecycle:
Infrastructure configuration and management
CI/CD tooling
Workforce and workload IAM
System security
Compliance
Sprawl and tech debt management
“Shifting left” has become a mantra for high-performing teams, particularly as it relates to software testing. The reality, though, is that much of this undifferentiated work—security, compliance, infrastructure, deployment—is still often treated as a separate concern to be tackled just before the system goes live or, in some cases, after it’s already been deployed to production. Security is a good example of this, where tools like Wiz scan for security issues in the runtime environment or during CI/CD—after the code has been written. Nothing against continuous security, but wouldn’t it be nice if systems could be built the “right” way up front to reduce rework or delays?
Deployment-Driven Development—a different kind of DDD—challenges this approach by flipping the paradigm. Instead of treating deployment as a final milestone, it prioritizes deployment from the start. The idea is simple but powerful: start with a deployment to a real, production-like environment on day one then work your way backwards. Doing this shifts more of these concerns left into the development process.
What is Deployment-Driven Development?
Deployment-Driven Development begins with a live, deployable environment and treats it as the foundation for all development activities that follow. The very first step when a new workload is created, before anything else happens, is deploying it to a real environment. From that point on, every line of code, every change, and every new feature is created and tested in an environment that mirrors production. This approach ensures that from day one, teams are building, testing, and iterating in conditions that match the realities of their live system, giving them the confidence that their application is production-ready at any given moment. As a result, teams avoid the common bottleneck of scrambling to get the application ready for production after development is complete—what I call “running the production gauntlet.”
While early-stage deployment to production-like environments is often considered best practice in modern software development, DDD formalizes this approach by reversing the typical order: start with deployment, then integrate code and configuration into that live setup. Setting up a real environment can be a significant lift for many teams, as provisioning and configuring production-like environments with the right infrastructure and permissions remains a complex task. By making deployment as simple and foundational as possible, Deployment-Driven Development makes it easier for teams to deliver faster with fewer roadblocks.
Shifting left traditionally applies to moving testing earlier in the development lifecycle, but DDD takes this idea further by shifting the deployment process itself to the beginning. Instead of validating code in isolation, the code is deployed in a full, production-ready environment, using automated provisioning to manage resources and integrate infrastructure. By proactively addressing deployment hurdles early, DDD helps reduce surprises and delays later on.
Why Legacy Infrastructure as Code Falls Short
Legacy Infrastructure as Code (IaC) like Terraform or CloudFormation doesn’t enable Deployment-Driven Development because these tools lack opinionation—clear, enforced standards for how infrastructure should be built and configured. They are general-purpose tools designed to solve all problems, much like a general-purpose programming language. For example, “least-privileged access” is widely accepted as a best practice, yet IaC tools don’t inherently enforce this principle. Developers must implement least-privileged access and other standards themselves. These IaC primitives just wrap the cloud provider’s API. The result is that legacy IaC tools don’t facilitate Deployment-Driven Development without a sizable investment into platform engineering.
There are abstractions that can help with this, whether it’s writing Terraform modules or using CDK to abstract CloudFormation and implement reusable constructs, but this goes back to what I said earlier about undifferentiated work: the act of “scaling” a product takes focus off the product itself. Consequently, we often see teams—especially those following a DevOps model—spending a disproportionate amount of time writing IaC versus writing product code.
With Deployment-Driven Development, however, opinionated infrastructure must be baked in from the beginning, automating setup in a way that enforces best practices, such as least-privileged access, as default behavior rather than optional guidance. To make this work with traditional IaC tools, it requires investing in a true platform engineering team to solve these problems for the rest of the organization. I rarely see teams approaching this from the DevOps angle doing this well at scale—it usually results in a great deal of inefficiency and sprawl. People copy/paste and bad patterns quickly proliferate.
Platform Engineering and Golden Paths
Shipping software the right way should be the easy way. At Real Kinetic, our Platform Engineering as a Service empowers organizations to adopt Deployment-Driven Development by creating golden paths for streamlined development. A golden path is an opinionated and supported way of building something within your organization. What it allows us to do is shift more things left into the development process. Rather than relying on policy and security scanners like Checkov or Wiz to detect issues reactively, we make it possible to only ship software that conforms to your organization’s internal controls or standards. While security scanners still play a role, this model significantly reduces the undifferentiated work and removes the guesswork from figuring out your organization’s standards. It lets product teams focus on the stuff that actually matters. Konfigurate, our modern IaC solution, allows organizations to enforce their standards easily—without requiring a substantial platform engineering investment.
Konfigurate was designed and built around the notion of Deployment-Driven Development. The platform’s opinionated IaC approach represents a modern solution to deployment and infrastructure management. By shifting infrastructure, compliance, and security concerns left, Konfigurate ensures that applications are production-ready from day one, enabling faster deployments and reducing time spent on “overhead” work so you can focus more on your actual product. It minimizes this work that otherwise gets deferred or left to evolve organically until it becomes a much bigger problem. This shift-left approach to IaC not only accelerates time-to-production but also provides peace of mind, knowing that infrastructure is secure, compliant, and standardized by design.
Platform engineering offers a scalable approach to DevOps by enabling organizations to codify best practices while providing the tooling and services that empower product teams to work more efficiently. However, this approach requires a dedicated investment in a platform engineering team. For startups and scaleups, this can be particularly challenging as their focus is often on rapid product development rather than internal infrastructure. Even large enterprises, especially those outside the tech industry, face hurdles in adopting platform engineering. IT departments in these organizations are frequently seen as cost centers, making it difficult to justify strategic investments like building a dedicated platform engineering function.
Conclusion
Deployment-Driven Development represents a subtle, yet fundamental, shift in how teams approach software delivery, prioritizing deployment from day one rather than treating it as an afterthought. By starting with a real, production-like environment, teams can build, test, and iterate more effectively, reducing the friction often caused by traditional infrastructure and deployment practices. This shift-left approach ensures that security, compliance, and operational concerns are addressed early, leading to faster, more reliable releases.
At Real Kinetic, we’ve embraced this methodology to help our clients streamline their delivery processes. Tools like Konfigurate embody this philosophy by providing opinionated, ready-to-use infrastructure that automates best practices, eliminating much of the undifferentiated work that slows teams down. By adopting Deployment-Driven Development, organizations can not only accelerate their time-to-market but also reduce tech debt, improve security posture, and focus more on delivering value to their customers.
Ultimately, Deployment-Driven Development is about making deployment the easy and natural part of the development lifecycle, allowing teams to deliver high-quality software with greater agility and confidence. Whether you’re a startup looking to scale quickly or an enterprise aiming to optimize your delivery pipeline, embracing this approach can be a game changer for your organization.
A lot of companies are trying to figure out how AI can be used to improve their business. Most of them are struggling to not just implement AI, but to even find use cases that aren’t contrived and actually add value to their customers. We recently discovered a compelling use case for AI integration in our Konfigurate platform, and we found that implementing generative AI doesn’t require a great deal of complexity. I’m going to walk you through what we learned about integrating an AI assistant into our production system. There’s a ton of noise out there about what you “need” to integrate AI into your product. The good news? You don’t need much. The bad news? It took too much time sifting through nonsense to find what actually helps deliver value with AI.
We’ll show you how to leverage Google’s Vertex AI with Gemini 1.5 to implement multimodal input for automating the creation of infrastructure as code. We’ll see how to make our AI assistant context-aware, how to configure output to be well-structured, how to tune the output without needing actual model tuning, and how to test the model.
Our Use Case
The Context
Konfigurate takes a modern approach to infrastructure as code (IaC) that shifts more concerns left into the development process such as security, compliance, and architecture standardization. In addition to managing your cloud infrastructure, it also integrates with GitHub or GitLab to manage your organization’s repository structure and CI/CD.
Workloads are organized into Platforms and Domains, creating a structured environment that connects GitHub/GitLab with your cloud platform for seamless application and infrastructure management. Everything in Konfigurate—Platforms, Domains, Workloads, Resources—is GitOps-driven and implemented through YAML configuration. Below is an example showing the configuration for an “Ecommerce” Platform:
The Konfigurate objects like Platforms, Domains, and Workloads are a well-structured problem. We have technical specifications for them defined in a way that’s easily interpretable by programs. In fact, as you can probably tell from the example above, they are simply Kubernetes CRDs, meaning they are—quite literally—well-defined APIs. And as you can tell from the example, these YAML configurations are fairly straightforward, but they can still be tedious to write by hand. Instead, usually what happens, which also happens with every other IaC tool, is definitions get copy/pasted and proliferated. We saw an opportunity for AI due to the structured nature of the system and definition of the problem space.
The Solution
Our idea was to create an AI assistant that could generate Konfigurate IaC definitions based on flexible user input. Users could interact with the system in a couple different ways:
Text Description: users could describe their desired system architecture using natural language, e.g. “Add a new analytics domain to the ecommerce platform and within it I need a new ETL pipeline that will pull data from the orders database, process it in Cloud Run, and write the transformed data to BigQuery.”
Architecture Diagram: users could provide an image of their architecture diagram.
While we only introduced support for natural language and image-based inputs, we also validated that it worked with audio-based descriptions of the architecture as well with no additional effort. We tested this by recording ourselves describing the infrastructure and then providing an M4A file to the model. We decided not to include this mode of input since, while cool, it seemed not particularly practical.
The Value
This multimodal approach not only saves developers hours of time spent on boilerplate code but also accommodates different working styles and preferences. Whether a team uses visual tools for architecture design or prefers text-based planning, our system can adapt, getting them up and running with minimal mental effort. Developers would still be responsible for verifying system behavior and testing, but the initial setup time could be drastically reduced across various input methods.
Critically, we found this feature makes IaC more accessible and productive for a much broader set of roles and skill sets. For instance, we’ve worked with mainframe COBOL engineers, data analysts, and developers with no cloud experience who are now able to more effectively implement cloud infrastructure and systems. It doesn’t hide the IaC from them, it just gives them a reliable starting point to work from that is actually grounded to their environment and problem space. What we have found with our AI-assisted infrastructure and our more general approach to Visual IaC is that developers spend more time focusing on their actual product and less time on undifferentiated work.
The Technology
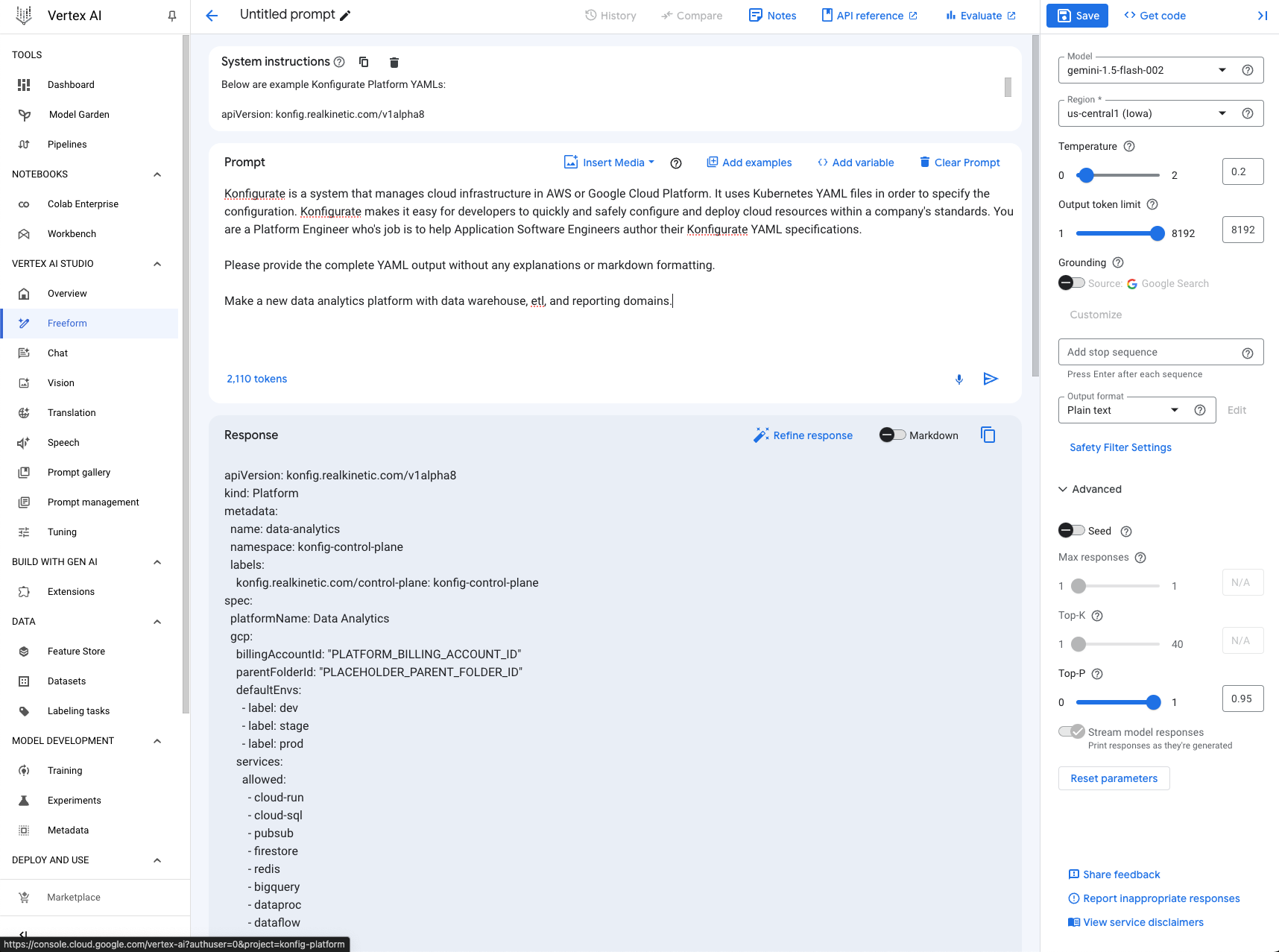
Our team has a lot of GCP experience, so we decided to use the Vertex AI platform and the Gemini-1.5-Flash-002 model for this project. It was a no-brainer for us. We know the ins and outs of GCP, and Vertex AI offers an all-in-one managed solution that makes it easy to get going. This particular model is fast and most importantly it’s cost-effective. As I am sure this will ring true for many of you, we didn’t want to mess around with setting up our own infrastructure or dealing with the headaches of managing our own AI models. The Vertex AI Studio made it really easy to start developing and iterating prompts as well as trying different models.
Vertex AI Studio
No, You Don’t Need RAG (At Least, We Didn’t)
Great, you’ve got your fancy AI setup, but don’t you need some complex retrieval system to make it context-aware? Sure, RAG (Retrieval Augmented Generation) is often touted as essential for creating context-aware AI agents. Our experience took us down a different path.
When researching how to create a context-aware GPT agent, you’ll inevitably encounter RAG. This typically involves:
Additional infrastructure for training and fine-tuning models
Our Initial Approach
We started by preparing JSONL-formatted data thinking we’d feed it into a RAG system. The plan was to have our AI model learn from this structured data to understand our Konfigurate specifications like Platforms and Domains. As we experimented, we found that going the RAG route wasn’t giving us the consistent, high-quality outputs we needed, so we pivoted.
The Big Prompt Solution
Instead of relying on RAG, we leaned heavily into prompt engineering. Here’s what we did:
Long-Context Prompts: we crafted detailed prompts that provided the necessary context about our Konfigurate system, its components, and how they interact.
Example IaC: as part of the prompt, we included numerous example definitions for Konfigurate objects such as Platforms and Domains.
Example Prompts: we also included example prompts and their corresponding correct outputs, essentially “showing” the AI what we expected.
Error Handling Prompts: we even included prompting that guided the AI on how to handle errors or edge cases.
Why This Worked Better
Consistency: by explicitly stating our requirements in the prompts, we got more consistent outputs.
Flexibility: it was easier to tweak and refine our prompts than to restructure a RAG system.
Control: we had more direct control over how the AI interpreted and used our domain-specific knowledge.
Simplicity: no need for additional infrastructure or complex retrieval systems—instead, it’s just a single API call.
The Takeaway
While RAG has its place, don’t assume it’s always necessary. For our use case, well-crafted prompts proved more effective than a sophisticated retrieval system. I believe this was a better fit because of the well-structured nature of our problem space. We can trivially validate the results output by the model because they are data structures with specifications. As a result, we got our context-aware AI assistant up and running faster, with better results, and without the overhead or complexity of RAG. Remember, in the world of technology, most times the simplest solution is the most elegant.
Prompt Engineering: The Secret Sauce
While prompt engineering has become a bit of a meme, it turned out to be the most crucial part of this whole process. When you’re working with these AI models, everything boils down to how you craft your prompts. It’s where the magic happens—or doesn’t.
Let’s break down what this looks like in practice. We’re using the Vertex AI API with Node.js , so we started with their boilerplate code. The key player is the getGenerativeModel() function. Here’s a stripped-down version of what we’re feeding it:
Model: We’re using the latest version of Gemini 1.5 Flash, which is a lightweight and cost-effective model that excels at multimodal tasks and processing large amounts of text.
Generation Config: This is where we control things like the max output length as well as the “temperature” of the model. Temperature controls the randomness in token selection for the output. Gemini 1.5 Flash has a temperature range of 0 to 2 with 1 being the default. A lower temperature is good when you’re looking for a “true or correct” response, while a higher temperature can result in more diverse or unexpected results. This can be good for use cases that require a more “creative” model, but since our use case requires quite a bit of precision, we opted for a low temperature value.
Safety Settings: These are Google’s defaults. Refer to their documentation for customization.
System Instruction: This is the real meat of prompt engineering. It’s where you prime the model, giving it context and setting its role. I’ve omitted this from the example above to go into more depth on this below since it’s a critical part of the solution.
The Art and Science of Prompting
Here’s the thing: prompt engineering is a fine line between science and art. We spent a non-trivial amount of time crafting our prompts to get consistent, useful outputs. It’s not just about dumping information, it’s about structuring it in a way that guides the AI to give you what you actually need. Remember, these models will do exactly what you tell them to do, not necessarily what you want them to do. Sound familiar? It’s like debugging code, but instead of fixing logic errors, you’re fine-tuning language.
Fair warning, this is probably where you’ll spend most of your engineering time. It’s tempting to think the AI will just “get it,” but that’s not how this works. You need to be painfully clear and specific in your instructions. We went through many iterations, tweaking words here and there, restructuring our prompts, and sometimes completely overhauling our approach. But each iteration got us closer to that sweet spot where the model consistently churned out exactly what we needed. In the end, nailing your prompt engineering is what separates a frustrating, inconsistent AI experience from one that feels like you’ve just added a new team member to your crew.
The System Instructions mentioned above provide a way to inform the model how it should behave, provide it context, tell it how to structure output, and so forth. Though this information is separate from the actual user-provided prompt, they are still technically part of the overall prompt sent into the model. Effectively, System Instructions provide a way to factor out common prompt components from the user-provided prompt. I won’t show all of our System Instructions because there are quite a few, but I’ll show several examples below to give you an idea. Again, this is about being painstakingly explicit and clear about what you want the model to do.
“Konfigurate is a system that manages cloud infrastructure in AWS or Google Cloud Platform. It uses Kubernetes YAML files in order to specify the configuration. Konfigurate makes it easy for developers to quickly and safely configure and deploy cloud resources within a company’s standards. You are a Platform Engineer who’s job is to help Application Software Engineers author their Konfigurate YAML specifications.”
“I am going to provide some example Konfigurate YAML files for your reference. Never output this example YAML directly. Rather, when providing examples in your output, generate new examples with different names and so forth.”
“Please provide the complete YAML output without any explanations or markdown formatting.”
“If the user asks about something other than Konfigurate or if you are unable to produce Konfigurate YAML for their prompt, tell them you cannot help with that (this is the one case to return something other than YAML). Specifically, respond with the following: ‘Sorry, I’m unable to help with that.’”
Controlling Output and Context-Awareness
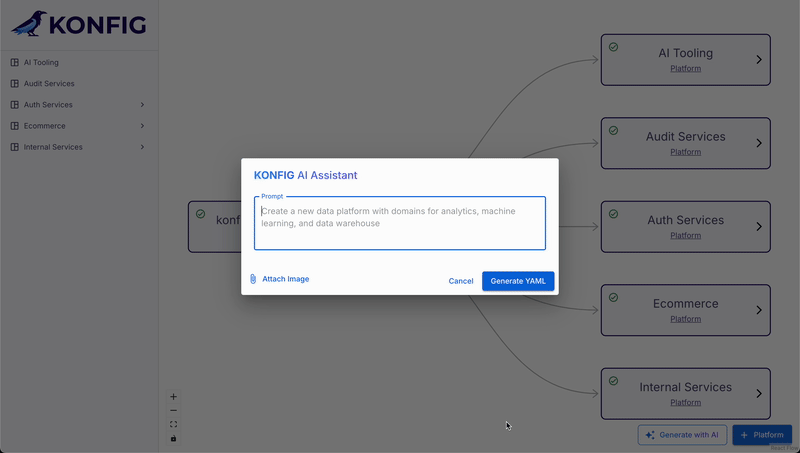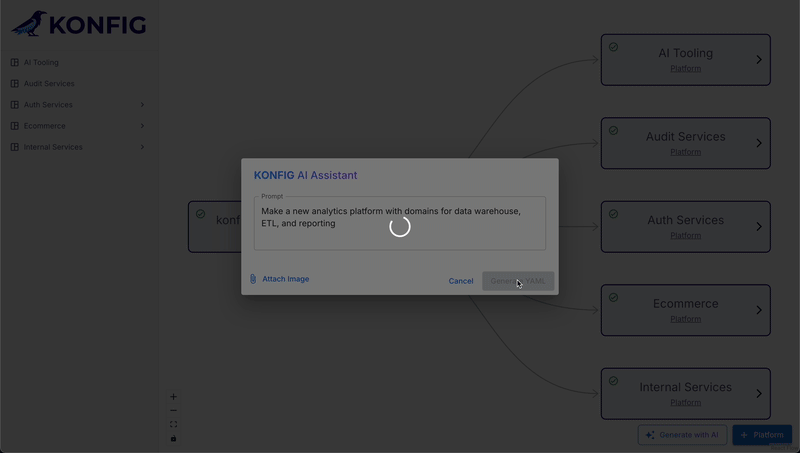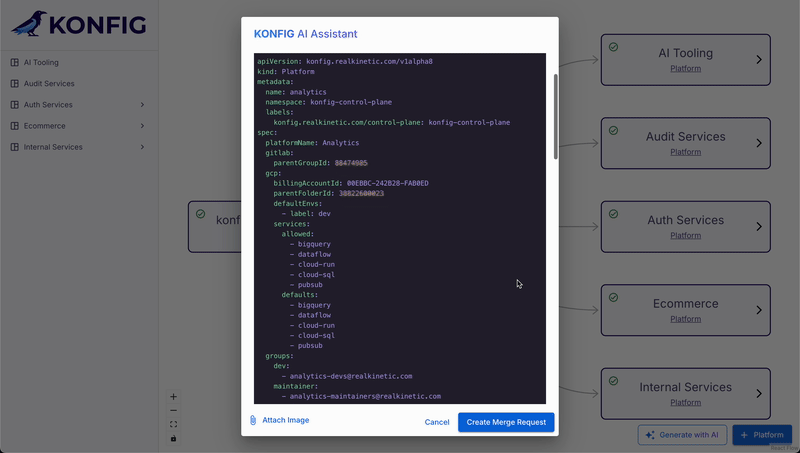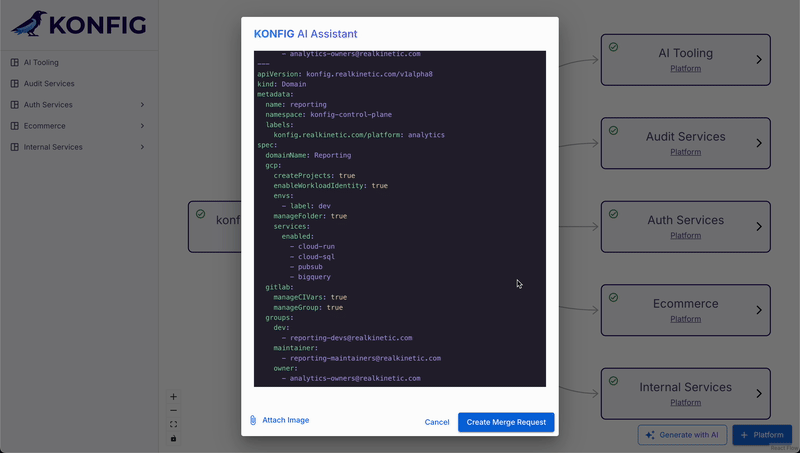
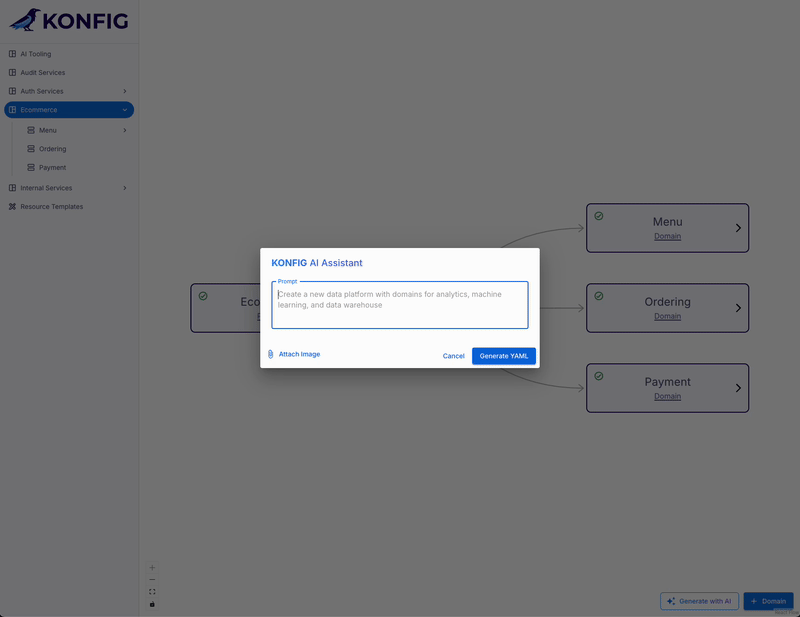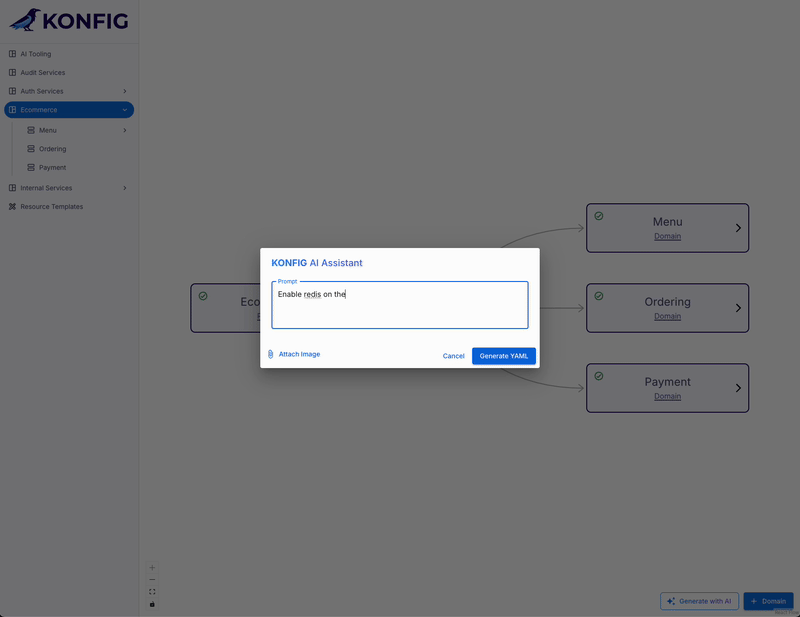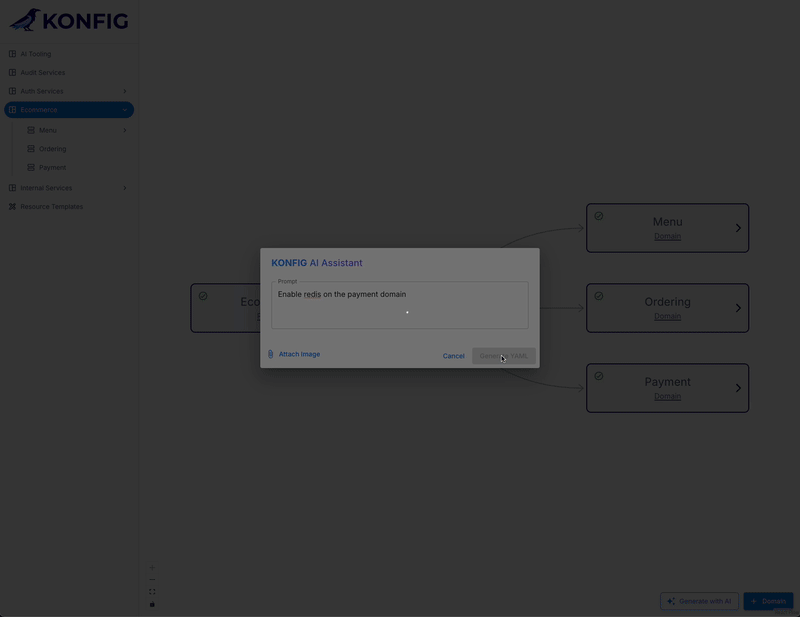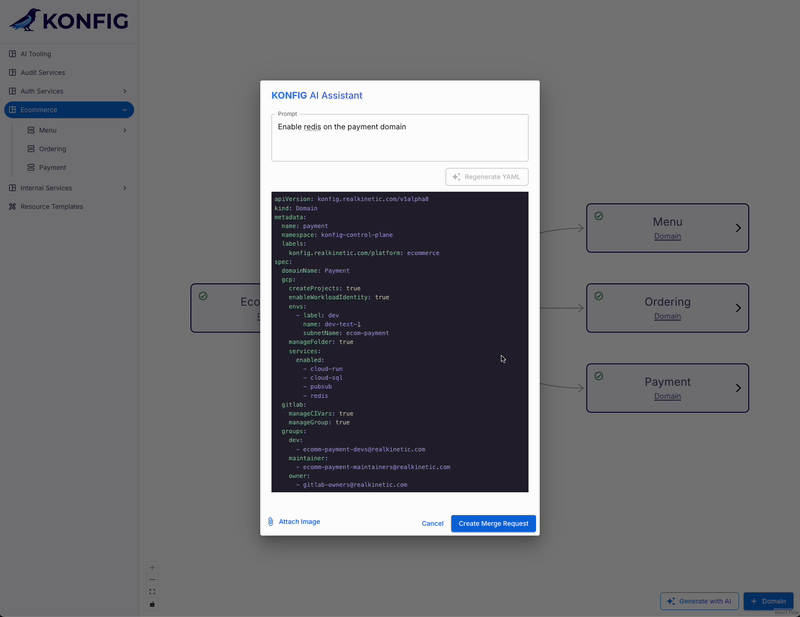
The example System Instructions above hint at this but it’s something worth going into more detail. First, our AI assistant has a very specific task: generate Konfigurate IaC YAML for users. For this reason, we never want it to output anything other than Konfigurate YAML to users, nor do we want it to respond to any prompts that are not directly related to Konfigurate. We handle this purely through prompting. To help the model understand Konfigurate IaC, we provide it with an extensive set of examples and tell it to only ever output complete YAML without any explanations or markdown formatting.
However, the output is actually more involved than this for our situation. That’s because we don’t just want to support generating new IaC, but also modify existing resources as well. This means the model doesn’t just need to be context-aware, it also needs to understand the distinction between “this is a new resource” and “this is an existing resource being modified.” This is important because Konfigurate is GitOps-driven, meaning the IaC resources are created in a branch and then a pull request is created for the changes. We need to know which resources are being created or modified, and if the latter, where those resources live.
Modifying an existing resource
To make the model context-aware, we feed it the definitions for the existing resources in the user’s environment. This needs to happen at “prompt time”, so this information is not included as part of the System Instructions. Instead, we fetch this information on demand when a user prompt is submitted and augment their prompt with it. Additionally, we provide the UI context in which the user is submitting the prompt from. For example, if they submit a prompt to create a new Domain while within the Ecommerce Platform, we can infer that they wish to create a new Domain within this specific Platform. It may seem obvious to us, but the model is completely unaware of this and so we need to provide it with this context. Below is the full code showing how this works and how the prompt is constructed.
export const generateYaml = async (
context: AIContext,
prompt: string,
fileData?: FileData,
) => {
const k8sApi = kc.makeApiClient(k8s.CustomObjectsApi);
const { controlPlaneProjectId, defaultBranch } = await getOrSetGitlabContext(k8sApi);
// Get user's environment information from the control plane
const [placeholders, konfigObjects] = await Promise.all([
getPlaceHolders(),
getKonfigObjectsYAML(controlPlaneProjectId, defaultBranch),
]);
const parts: Part[] = [];
if (fileData) {
parts.push({
fileData,
});
}
if (prompt) {
parts.push({
text: prompt,
});
}
// Add user's environment context to the prompt
parts.push(
{
text:
"Replace the placeholders with the following values if they should be present " +
"in the output YAML unless the prompt is referring to actual YAMLs from the " +
"user's environment, in which case use the YAML as is without replacing " +
"values: " + JSON.stringify(placeholders, null, 2) + ".",
},
{
text:
'Following the "---" below are all existing Konfigurate YAMLs for the ' +
"user\'s environment should they be needed either to reference or modify " +
"and provide as output based on the prompt. Don't forget to never output " +
"the example YAML exactly as is without modifications. Only output " +
"Konfigurate object YAML and no other YAML structures. Infer appropriate " +
"emails for dev, maintainer, and owner groups based on those in the " +
"provided YAML below if possible.\n" +
"---\n" +
konfigObjects +
"\n---\n",
},
);
// Add user's UI context to the prompt
if (context) {
let contextPrompt = "";
let contextSet = false;
if (context.platform && context.domain && context.workload) {
contextPrompt = `The user is operating within the context of the ${context.workload} Workload which is in the ${context.domain} Domain of the ${context.platform} Platform.`;
contextSet = true;
} else if (context.platform && context.domain) {
contextPrompt = `The user is operating within the context of the ${context.domain} Domain of the ${context.platform} Platform.`;
contextSet = true;
} else if (context.platform) {
contextPrompt = `The user is operating within the context of the ${context.platform} Platform.`;
contextSet = true;
}
if (contextSet) {
contextPrompt +=
" Use this context to infer where output objects should go should " +
"the user not provide explicit instructions in the prompt.";
parts.push({
text: contextPrompt,
});
}
}
const contents: Content[] = [
{
role: "user",
parts,
},
];
const req: GenerateContentRequest = {
contents,
};
const resp = await makeVertexRequest(req);
return { error: resp === errorResponseMessage, content: resp };
};
This prompt manipulation makes the model smart enough to understand the user’s environment and the context in which they are operating within. Feeding it all of this information is possible due to Gemini 1.5’s context window. The context window acts like a short-term memory, allowing the model to recall information as part of its output generation. While a person’s short-term memory is generally quite limited both in terms of the amount of information and recall accuracy, generative models like Gemini 1.5 can have massive context windows and near-perfect recall. Gemini 1.5 Flash in particular has a 1-million-token context window, and Gemini 1.5 Pro has a 2-million-token context window. For reference, 1 million tokens is the equivalent of 50,000 lines of code (with standard 80 characters per line) or 8 average-length English novels. This is called “long context”, and it allows us to provide the model with massive prompts while it is still able to find a “needle in a haystack.”
Long context has allowed us to make the model context-aware with minimal effort, but there’s still a question we have not yet addressed: how can the model also output metadata along with the generated IaC YAML? Specifically, we need to know the file path for each respective Konfigurate object so that we create new resources in the right place or we modify the correct existing resources. The answer, of course, is more prompt engineering. To solve this problem, we instructed the model to include metadata YAML with each Konfigurate object. This metadata contains the file path for the object and whether or not it’s an existing resource. Here’s an example:
We did this by providing the model with several examples. Here is the System Instruction prompt we used:
{
text:
"For each Konfigurate YAML you output, include the following metadata, " +
"also in YAML format, following the Konfigurate object itself: " +
"filePath, isExisting. Here are some examples:\n" + metadataExample,
}
It seems simple, but it was surprisingly effective and reliable.
Model Stability and Testing
Working with LLMs is a bit like describing a problem to someone else who writes the code to solve it—but without seeing the code, making it impossible to debug when issues arise. Worse yet, subtle changes in the description of the problem is akin to the other person starting over fully from scratch each time, so you might get consistent results or it could be completely different. There are also cases where no matter how explicit you are in your prompting, the model just doesn’t do the right thing. For example, with Gemini-1.5-Flash-001, I had problems preventing the AI from outputting the examples verbatim. I told it, in a variety of ways, to generate new examples using the provided ones as reference for the overall structure of resources, but it simply wouldn’t do it—until I upgraded to Gemini-1.5-Flash-002.
What we saw is that something as simple as just changing the model version could result in wildly different output. This is a nascent area but it’s a major challenge for companies attempting to leverage generative AI within their products or, worse, as a core component of their product. The only solution I can think of is to have a battery of test prompts you feed your AI and compare the results. But even this is problematic as the output content might be the same but the structure may have slight variations. In our case because we are generating YAML, it’s easy for us to validate output, but for use cases that are less structured, this seems like a major concern. Another solution is to feed results into a different model, but this feels equally precarious.
In addition to model stability, we had some challenges with “jailbreaking” the model. While we were never able to jailbreak the model to operate outside the context of Konfigurate, we were on occasion able to get it to provide Konfigurate output that was outside the bounds of our prompting. We did not invest a ton of time into this area as it felt like there wasn’t great ROI and it wasn’t really a concern within our product, but it’s certainly a concern when building with LLMs.
Patterns That Worked For Us: Prompt Engineering Pro Tips
You have stuck with us this far and now it’s time for some concrete strategies that consistently improved our AI’s performance. Here’s what we learned:
Be Specific About Output: tell the model exactly what you want and how you want it. For us, that meant specifying YAML as the output format. Don’t leave room for interpretation—the clearer you are, the better the results.
Show, Don’t Just Tell: give the model examples of what good output looks like. We explicitly prompted our model to reference our example resource specifications. It’s like training a new team member—show them what success looks like.
Use Placeholders: providing examples to the model worked great, except when it would use specific field values from the examples in the user’s output. To address this we used sentinel placeholder values in the examples and then had a step that told the model to replace the placeholders with values from the user’s environment at prompt time.
Error Handling is Key: just like you’d build error handling into your code, build it into your prompts. Give the model clear instructions on how to respond when it encounters ambiguous or out-of-scope requests. This keeps the user experience smooth, even when things go sideways.
The Anti-Hallucination Trick: it sounds silly but it helps to explicitly tell the model not to hallucinate and to only respond within the context you’ve provided. It’s not foolproof, but we’ve seen a significant reduction in made-up information, especially when you’ve fine-tuned the temperature.
Remember, prompt engineering is an iterative process. What works for one use case might not work for another. Keep experimenting, keep refining, and don’t be afraid to start from scratch if something’s not clicking. The goal is to find that sweet spot where your AI becomes a reliable, consistent part of your workflow.
Wrapping It Up
There you have it, our journey into integrating AI into the Konfigurate platform. We started thinking we needed all sorts of fancy tech only to find that sometimes, simpler is better. The big takeaways?
You don’t always need complex systems like RAG. A well-crafted prompt can often do the job just as well, if not better. Gemini 1.5’s long context and near-perfect recall makes it quite adept at the “needle-in-a-haystack” problem, and it enables pretty sophisticated use cases through complex prompting.
Prompt engineering isn’t just a buzzword or meme. It’s where the real work happens, and it’s worth investing your time to get it right.
LLMs are well-suited to structured problems because they are good at pattern matching. They’re also good at creative problems, but it’s less clear to us how to integrate something like this into a product versus a structured problem.
The AI landscape is constantly evolving. What works today might not be the best approach tomorrow. Stay flexible and keep experimenting.
We hope sharing our experience saves you some time and headaches. Remember, there’s no one-size-fits-all solution in AI integration. What worked for us might need tweaking for your specific use case. The key is to start simple, iterate often, and don’t be afraid to challenge conventional wisdom. You might just find that the “must-have” tools aren’t so must-have after all.