Building software of significant complexity is tough because a lot of pieces have to come together and a lot of teams have to work in concert to be successful. It can be extraordinarily difficult to get everyone on the same page and moving in tandem toward a common goal. Product development is largely an exercise in trust (or perhaps more accurately, hiring), but even if you have the “right” people—people you can trust and depend on to get things done—you’re only halfway there.
Trust is an important quality to screen for, difficult though it may be. However, a person’s trustworthiness or dependability doesn’t really tell you much about that person as an engineer. The engineering culture is something that must be cultivated. Etsy’s CTO, John Allspaw, said it best in a recent interview:
Post-mortem debriefings every day are littered with the artifacts of people insisting, the second before an outage, that “I don’t have to care about that.”
If “abstracting away” is nothing for you but a euphemism for “Not my job,” “I don’t care about that,” or “I’m not interested in that,” I think Etsy might not be the place for you. Because when things break, when things don’t behave the way they’re expected to, you can’t hold up your arms and say “Not my problem.” That’s what I could call “covering your ass” engineering, and it may work at other companies, but it doesn’t work here.
Allspaw calls this the distinction between hiring software developers and software engineers. This perception often results in heated debate, but I couldn’t agree with it more. There is a very real distinction to be made. Abstraction is not about boundaries of concern, it’s about boundaries of focus. Engineers need to have an intimate understanding of this.
Engineering, as a discipline and as an activity, is multi-disciplinary. It’s just messy. And that’s actually the best part of engineering. It’s not about everyone knowing everything. It’s about paying attention to the shared, mutual understanding.
But engineering is more than just technical aptitude and a willingness to “dig in” to the guts of something. It’s about having an acute awareness of the delicate structure upon which software is built. More succinctly, it’s about having empathy. It’s recognizing the fact that shit rolls downhill.
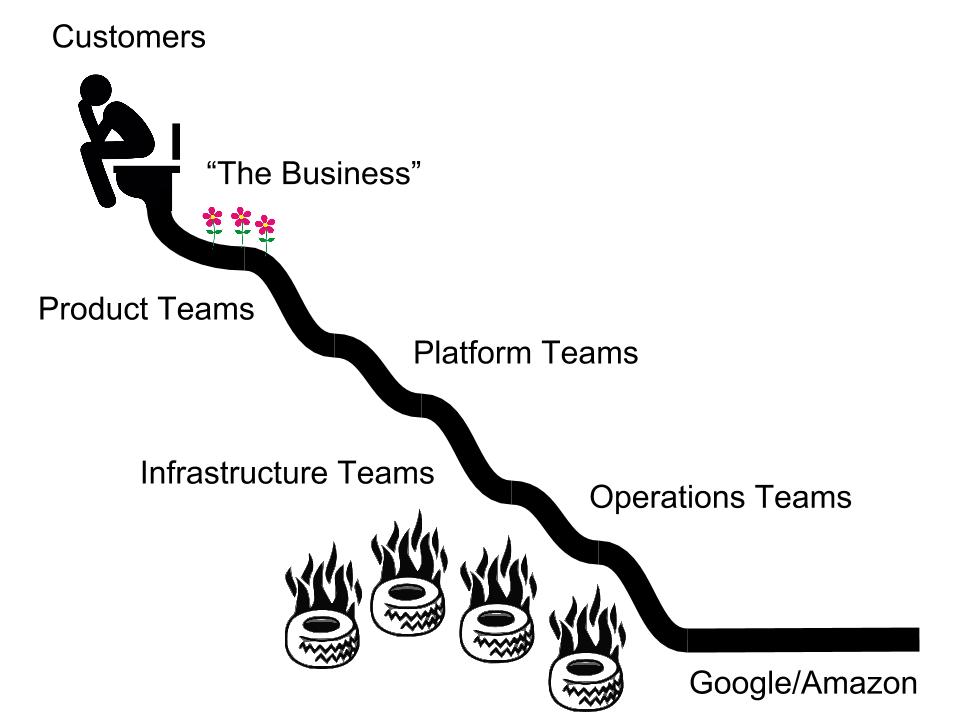
For things to work, the entire structure has to hold, and no one point is any more or less important than the others. It almost always starts off with good intentions at the top, but the shit starts to compound and accelerate as it rolls effortlessly and with abandon toward the bottom. There are a few aspects to this I want to explore.
Understand the Relationships
This isn’t to say that folks near the top are less susceptible to shit. Everyone has to shovel it, but the way it manifests is different depending on where you find yourself on the hill. The key point is that the people above you are effectively your customers, either directly or indirectly, and if you’re toward the top, maybe literally.
And, as all customers do, they make demands. This is a very normal thing and is to be expected. Some of these demands are reasonable, others not so much. Again, this is normal, but what do we make of these demands?
There are some interesting insights we can take from The Innovator’s Dilemma (which, by the way, is an essential read for anyone looking to build, run, or otherwise contribute to a successful business), which are especially relevant toward the top of the hill. Mainly, we should not merely take the customer’s word as gospel. When it comes to products, feature requests, and “the way things should be done,” the customer tends to have a very narrow and predisposed view. I find the following passage to be particularly poignant:
Indeed, the power and influence of leading customers is a major reason why companies’ product development trajectories overshoot demands of mainstream markets.
Essentially, too much emphasis can be placed on the current or perceived needs of the customer, resulting in a failure to meet their unstated or future needs (or if we’re talking about internal customers, the current or future needs of the business). Furthermore, we can spend too much time focusing on the customer’s needs—often perceived needs—culminating in a paralysis to ship. This is very anti-continuous-delivery. Get things out fast, see where they land, and make appropriate adjustments on the fly.
Giving in to customer demands is a judgement game, but depending on the demand, it can have profound impact on the people further down the hill. Thus, these decisions should be made accordingly and in a way that involves a cross section of the hill. If someone near the top is calling all the shots, things are not going to work out, and in all likelihood, someone else is going to end up getting covered in shit.
An interesting corollary is the relationship between leadership and engineers. Even a single, seemingly innocuous question asked in passing by a senior manager can change the entire course of a development team. In fact, the manager was just trying to gain information, but the team interpreted the question as a statement suggesting “this thing needs to be done.” It’s important to recognize this interaction for what it is.
Set Appropriate Expectations
In truth, the relationship between teams is not equivalent to the relationship between actual customers and the business. You may depend on another team in order to provide a certain feature or to build a certain product. If the business is lagging, the customer might take their money elsewhere. If the team you depend on is lagging, you might not have the same liberty. This leads to the dangerous “us versus them” trap teams fall in as an organization grows. The larger a company gets, the more fingers get pointed because “they’re no longer us, they’re them.” There are more teams, they are more isolated, and there are more dependencies. It doesn’t matter how great your culture is, changing human nature is hard. And when pressure builds from above, the finger-pointing only intensifies.
Therefore, it’s critical to align yourself with the teams you depend on. Likewise, align yourself with the teams that depend on you, don’t alienate them. In part, this means have a realistic sense of urgency, have realistic expectations, and plan accordingly. It’s not reasonable to submit a work item to another team and turn around and call it a blocker. Doing so means you failed to plan, but now to outside observers, it’s the other team which is the problem. As we prioritize the work precipitated by our customers, so do the rest of our teams. With few exceptions, you cannot expect a team to drop everything they’re doing to focus on your needs. This is the aforementioned “us versus them” mentality. Instead, align. Speak with the team you depend on, understand where your needs fit within their current priorities, and if it’s a risk, be willing to roll up your sleeves and help out. This is exactly what Allspaw was getting at when he described what a “software engineer” is.
Setting realistic expectations is vital. Just as products ship with bugs, so does everything else in the stack. Granted, some bugs are worse than others, but no amount of QA will fully prevent them from going to production. Bugs will only get worked out if the code actually gets used. You cannot wait until something is perfect before adopting it. You will wait forever. Remember that Agile is micro failure on a macro level. Adopt quickly, deploy quickly, fail quickly, adjust quickly. As Jay Kreps once said, “The only way to really know if a system design works in the real world is to build it, deploy it for real applications, and see where it falls short.”
While it’s important to set appropriate expectations downward, it’s also important to communicate upward. Ensure that the teams relying on you have the correct expectations. Establish what the team’s short-term and long-term goals are and make them publicly available. Enable those teams to plan accordingly, and empower them so that they can help out when needed. Provide adequate documentation such that another engineer can jump in at any time with minimal handoff.
Be Curious
This largely gets back to the quote by John Allspaw. The point is that we want to hire and develop software engineers, not programmers. Being an engineer should mean having an innate curiosity. Figure out what you don’t know and push beyond it.
Understand, at least on some level, the things that you depend on. Own everything. Similarly, if you built it and it’s running in production, it’s on you to support it. Throwing code over the wall is no longer acceptable. When there’s a problem with something you depend on, don’t just throw up your hands and say “not my problem.” Investigate it. If you’re certain it’s a problem in someone else’s system, bring it to them and help root cause it. Provide context. When did it start happening? What were the related events? What were the effects? Don’t just send an error message from the logs.
This is the engineering culture that gets you the rest of the way there. The people are important, especially early on, but it’s the core values and practices that will carry you. The Innovator’s Dilemma again provides further intuition:
In the start-up stages of an organization, much of what gets done is attributable to resources—people, in particular. The addition or departure of a few key people can profoundly influence its success. Over time, however, the locus of the organization’s capabilities shifts toward its processes and values. As people address recurrent tasks, processes become defined. And as the business model takes shape and it becomes clear which types of business need to be accorded highest priority, values coalesce. In fact, one reason that many soaring young companies flame out after an IPO based on a single hot product is that their initial success is grounded in resources—often the founding engineers—and they fail to develop processes that can create a sequence of hot products.
Summary
There will always be gravity. As such, shit will always roll downhill. It’s important to embrace this structure, to understand the relationships, and to set appropriate expectations. Equally important is fostering an engineering culture—a culture of curiosity, ownership, and mutual understanding. Having the right people is essential, but it’s only half the problem. The other half is instilling the right values and practices. Shit rolls downhill, but if you have the right people, values, and practices in place, that manure might just grow something amazing.