
Last week I open sourced Liftbridge, my latest project and contribution to the Cloud Native Computing Foundation ecosystem. Liftbridge is a system for lightweight, fault-tolerant (LIFT) message streams built on NATS and gRPC. Fundamentally, it extends NATS with a Kafka-like publish-subscribe log API that is highly available and horizontally scalable.
I’ve been working on Liftbridge for the past couple of months, but it’s something I’ve been thinking about for over a year. I sketched out the design for it last year and wrote about it in January. It was largely inspired while I was working on NATS Streaming, which I’m currently still the second top contributor to. My primary involvement with NATS Streaming was building out the early data replication and clustering solution for high availability, which has continued to evolve since I left the project. In many ways, Liftbridge is about applying a lot of the things I learned while working on NATS Streaming as well as my observations from being closely involved with the NATS community for some time. It’s also the product of scratching an itch I’ve had since these are the kinds of problems I enjoy working on, and I needed something to code.
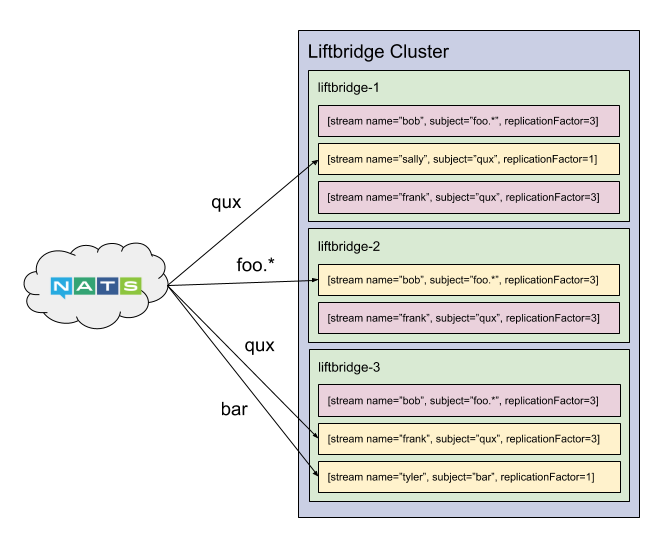
At its core, Liftbridge is a server that implements a durable, replicated message log for the NATS messaging system. Clients create a named stream which is attached to a NATS subject. The stream then records messages on that subject to a replicated write-ahead log. Multiple consumers can read back from the same stream, and multiple streams can be attached to the same subject.

The goal is to bridge the gap between sophisticated log-based messaging systems like Apache Kafka and Apache Pulsar and simpler, cloud-native systems. This meant not relying on external coordination services like ZooKeeper, not using the JVM, keeping the API as simple and small as possible, and keeping client libraries thin. The system is written in Go, making it a single static binary with a small footprint (~16MB). It relies on the Raft consensus algorithm to do coordination. It has a very minimal API (just three endpoints at the moment). And the API uses gRPC, so client libraries can be generated for most popular programming languages (there is a Go client which provides some additional wrapper logic, but it’s pretty thin). The goal is to keep Liftbridge very lightweight—in terms of runtime, operations, and complexity.
However, the bigger goal of Liftbridge is to extend NATS with a durable, at-least-once delivery mechanism that upholds the NATS tenets of simplicity, performance, and scalability. Unlike NATS Streaming, it uses the core NATS protocol with optional extensions. This means it can be added to an existing NATS deployment to provide message durability with no code changes.
NATS Streaming provides a similar log-based messaging solution. However, it is an entirely separate protocol built on top of NATS. NATS is an implementation detail—the transport—for NATS Streaming. This means the two systems have separate messaging namespaces—messages published to NATS are not accessible from NATS Streaming and vice versa. Of course, it’s a bit more nuanced than this because, in reality, NATS Streaming is using NATS subjects underneath; technically messages can be accessed, but they are serialized protobufs. These nuances often get confounded by first–time users as it’s not always clear that NATS and NATS Streaming are completely separate systems. NATS Streaming also does not support wildcard subscriptions, which sometimes surprises users since it’s a major feature of NATS.
As a result, Liftbridge was built to augment NATS with durability rather than providing a completely separate system. To be clear, it’s still a separate server, but it merely acts as a write-ahead log for NATS subjects. NATS Streaming provides a broader set of features such as durable subscriptions, queue groups, pluggable storage backends, and multiple fault-tolerance modes. Liftbridge aims to have a relatively small API surface area.
The key features that differentiate Liftbridge are the shared message namespace, wildcards, log compaction, and horizontal scalability. NATS Streaming replicates channels to the entire cluster through a single Raft group, so adding servers does not help with scalability and actually creates a head-of-line bottleneck since everything is replicated through a single consensus group (n.b. NATS Streaming does have a partitioning mechanism, but it cannot be used in conjunction with clustering). Liftbridge allows replicating to a subset of the cluster, and each stream is replicated independently in parallel. This allows the cluster to scale horizontally and partition workloads more easily within a single, multi-tenant cluster.
Some of the key features of Liftbridge include:
- Log-based API for NATS
- Replicated for fault-tolerance
- Horizontally scalable
- Wildcard subscription support
- At-least-once delivery support
- Message key-value support
- Log compaction by key (WIP)
- Single static binary (~16MB)
- Designed to be high-throughput (more on this to come)
- Supremely simple
Initially, Liftbridge is designed to point to an existing NATS deployment. In the future, there will be support for a “standalone” mode where it can run with an embedded NATS server, allowing for a single deployable process. And in support of the “cloud-native” model, there is work to be done to make Liftbridge play nice with Kubernetes and generally productionalize the system, such as implementing an Operator and providing better instrumentation—perhaps with Prometheus support.
Over the coming weeks and months, I will be going into more detail on Liftbridge, including the internals of it—such as its replication protocol—and providing benchmarks for the system. Of course, there’s also a lot of work yet to be done on it, so I’ll be continuing to work on that. There are many interesting problems that still need solved, so consider this my appeal to contributors. :)
Follow @tyler_treat
After reading through Liftbridge docs and the replication protocol, I’m curious what was the reason you used Kafka’s in-sync replica protocol rather than the “raft log as message log” approach from NATS Streams?
NATS Streaming doesn’t actually use the Raft log as the message log, it uses it as a secondary replication/recovery log meaning it stores messages redundantly. The Kafka-based protocol means we can use the message log itself for replication so no redundancy and it’s faster. It also means we can “tune” the replication based on durability needs (replicate to all or subset of replicas, etc.). Lastly, the ISR approach allows balancing availability with durability. If brokers fail, the ISR can shrink and the cluster can maintain availability. With Raft, you cannot make this trade-off and must retain a quorum.