Disclaimer (10/29/20) – The benchmarks and performance analysis presented in this post should not be relied on. This post was written roughly six years ago, and at the time, was just the result of my exploration of various messaging systems. The benchmarks are not implemented in a meaningful way, which I discussed in a follow-up post. This post will remain for posterity and learning purposes, but I do not claim that this information is accurate or useful.
Continuing my series on message queues, I spent this weekend dissecting various libraries for performing distributed messaging. In this analysis, I look at a few different aspects, including API characteristics, ease of deployment and maintenance, and performance qualities. The message queues have been categorized into two groups: brokerless and brokered. Brokerless message queues are peer-to-peer such that there is no middleman involved in the transmission of messages, while brokered queues have some sort of server in between endpoints.
The systems I’ll be analyzing are:
Brokerless
nanomsg
ZeroMQ
Brokered
ActiveMQ
NATS
Kafka
Kestrel
NSQ
RabbitMQ
Redis
ruby-nats
To start, let’s look at the performance metrics since this is arguably what people care the most about. I’ve measured two key metrics: throughput and latency. All tests were run on a MacBook Pro 2.6 GHz i7, 16GB RAM. These tests are evaluating a publish-subscribe topology with a single producer and single consumer. This provides a good baseline. It would be interesting to benchmark a scaled-up topology but requires more instrumentation.
The code used for benchmarking, written in Go, is available on GitHub. The results below shouldn’t be taken as gospel as there are likely optimizations that can be made to squeeze out performance gains. Pull requests are welcome.
Throughput Benchmarks
Throughput is the number of messages per second the system is able to process, but what’s important to note here is that there is no single “throughput” that a queue might have. We’re sending messages between two different endpoints, so what we observe is a “sender” throughput and a “receiver” throughput—that is, the number of messages that can be sent per second and the number of messages that can be received per second.
This test was performed by sending 1,000,000 1KB messages and measuring the time to send and receive on each side. Many performance tests tend to use smaller messages in the range of 100 to 500 bytes. I chose 1KB because it’s more representative of what you might see in a production environment, although this varies case by case. For message-oriented middleware systems, only one broker was used. In most cases, a clustered environment would yield much better results.
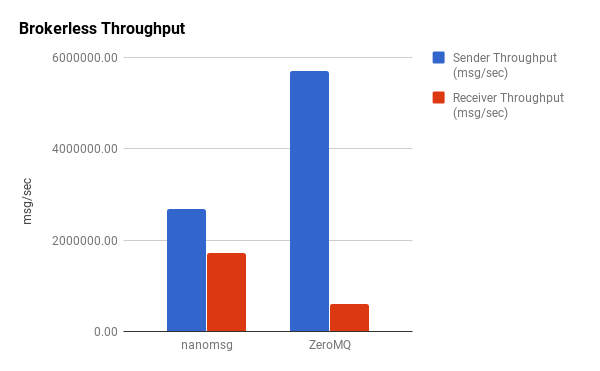
Unsurprisingly, there’s higher throughput on the sending side. What’s interesting, however, is the disparity in the sender-to-receiver ratios. ZeroMQ is capable of sending over 5,000,000 messages per second but is only able to receive about 600,000/second. In contrast, nanomsg sends shy of 3,000,000/second but can receive almost 2,000,000.
Now let’s take a look at the brokered message queues.
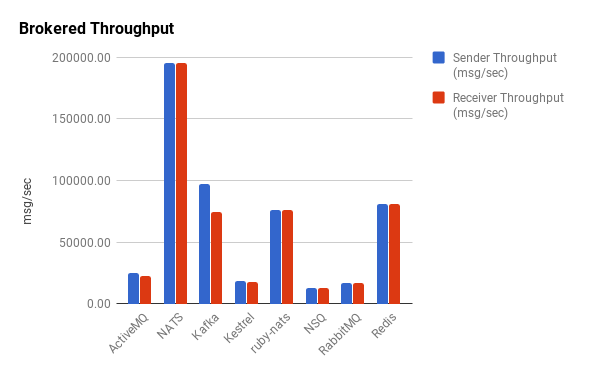
Intuitively, we observe that brokered message queues have dramatically less throughput than their brokerless counterparts by a couple orders of magnitude for the most part. Half the brokered queues have a throughput below 25,000 messages/second. The numbers for Redis might be a bit misleading though. Despite providing pub/sub functionality, it’s not really designed to operate as a robust messaging queue. In a similar fashion to ZeroMQ, Redis disconnects slow clients, and it’s important to point out that it was not able to reliably handle this volume of messaging. As such, we consider it an outlier. Kafka and ruby-nats have similar performance characteristics to Redis but were able to reliably handle the message volume without intermittent failures. The Go implementation of NATS, gnatsd, has exceptional throughput for a brokered message queue.
Outliers aside, we see that the brokered queues have fairly uniform throughputs. Unlike the brokerless libraries, there is little-to-no disparity in the sender-to-receiver ratios, which themselves are all very close to one.
Latency Benchmarks
The second key performance metric is message latency. This measures how long it takes for a message to be transmitted between endpoints. Intuition might tell us that this is simply the inverse of throughput, i.e. if throughput is messages/second, latency is seconds/message. However, by looking closely at this image borrowed from a ZeroMQ white paper, we can see that this isn’t quite the case.
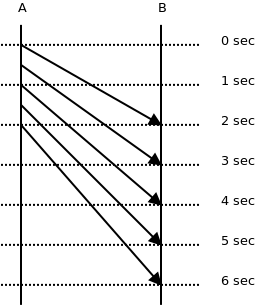
The reality is that the latency per message sent over the wire is not uniform. It can vary wildly for each one. In truth, the relationship between latency and throughput is a bit more involved. Unlike throughput, however, latency is not measured at the sender or the receiver but rather as a whole. But since each message has its own latency, we will look at the averages of all of them. Going further, we will see how the average message latency fluctuates in relation to the number of messages sent. Again, intuition tells us that more messages means more queueing, which means higher latency.
As we did before, we’ll start by looking at the brokerless systems.
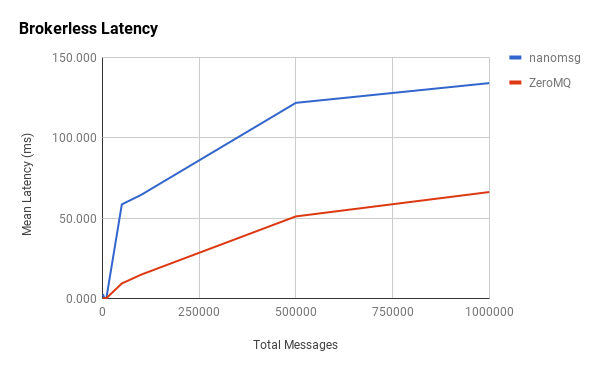
In general, our hypothesis proves correct in that, as more messages are sent through the system, the latency of each message increases. What’s interesting is the tapering at the 500,000-point in which latency appears to increase at a slower rate as we approach 1,000,000 messages. Another interesting observation is the initial spike in latency between 1,000 and 5,000 messages, which is more pronounced with nanomsg. It’s difficult to pinpoint causation, but these changes might be indicative of how message batching and other network-stack traversal optimizations are implemented in each library. More data points may provide better visibility.
We see some similar patterns with brokered queues and also some interesting new ones.
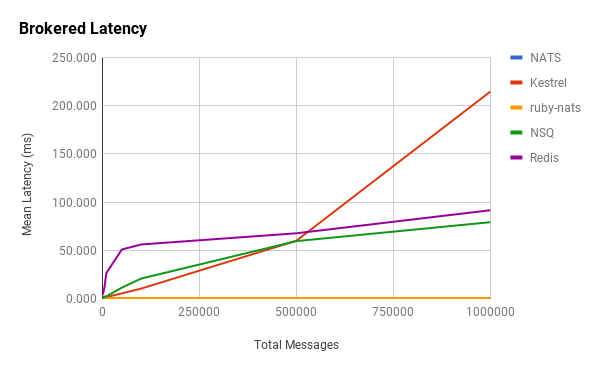
Redis behaves in a similar manner as before, with an initial latency spike and then a quick tapering off. It differs in that the tapering becomes essentially constant right after 5,000 messages. NSQ doesn’t exhibit the same spike in latency and behaves, more or less, linearly. Kestrel fits our hypothesis.
Notice that ruby-nats and NATS hardly even register on the chart. They exhibited surprisingly low latencies and unexpected relationships with the number of messages.
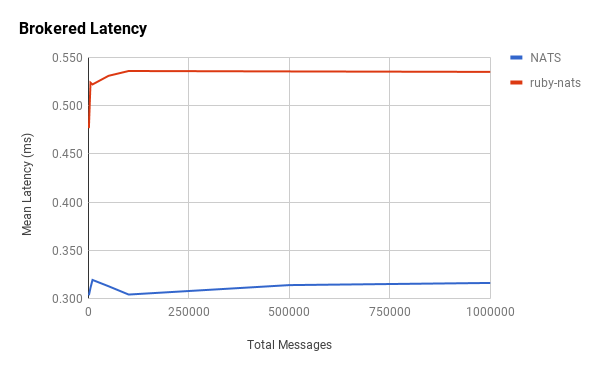
Interestingly, the message latencies for ruby-nats and NATS appear to be constant. This is counterintuitive to our hypothesis.
You may have noticed that Kafka, ActiveMQ, and RabbitMQ were absent from the above charts. This was because their latencies tended to be orders-of-magnitude higher than the other brokered message queues, so ActiveMQ and RabbitMQ were grouped into their own AMQP category. I’ve also included Kafka since it’s in the same ballpark.
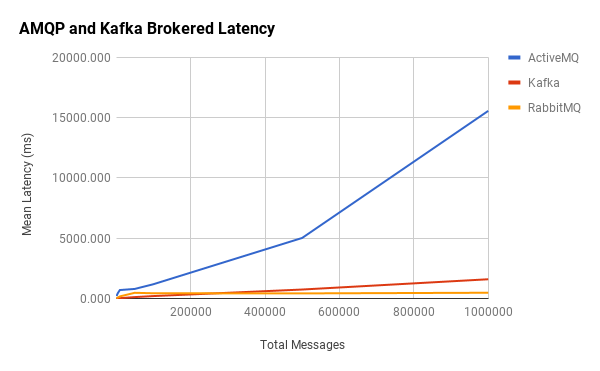
Here we see that RabbitMQ’s latency is constant, while ActiveMQ and Kafka are linear. What’s unclear is the apparent disconnect between their throughput and mean latencies.
Qualitative Analysis
Now that we’ve seen some empirical data on how these different libraries perform, I’ll take a look at how they work from a pragmatic point of view. Message throughput and speed is important, but it isn’t very practical if the library is difficult to use, deploy, or maintain.
ZeroMQ and Nanomsg
Technically speaking, nanomsg isn’t a message queue but rather a socket-style library for performing distributed messaging through a variety of convenient patterns. As a result, there’s nothing to deploy aside from embedding the library itself within your application. This makes deployment a non-issue.
Nanomsg is written by one of the ZeroMQ authors, and as I discussed before, works in a very similar way to that library. From a development standpoint, nanomsg provides an overall cleaner API. Unlike ZeroMQ, there is no notion of a context in which sockets are bound to. Furthermore, nanomsg provides pluggable transport and messaging protocols, which make it more open to extension. Its additional built-in scalability protocols also make it quite appealing.
Like ZeroMQ, it guarantees that messages will be delivered atomically intact and ordered but does not guarantee the delivery of them. Partial messages will not be delivered, and it’s possible that some messages won’t be delivered at all. The library’s author, Martin Sustrik, makes this abundantly clear:
Guaranteed delivery is a myth. Nothing is 100% guaranteed. That’s the nature of the world we live in. What we should do instead is to build an internet-like system that is resilient in face of failures and routes around damage.
The philosophy is to use a combination of topologies to build resilient systems that add in these guarantees in a best-effort sort of way.
On the other hand, nanomsg is still in beta and may not be considered production-ready. Consequently, there aren’t a lot of resources available and not much of a development community around it.
ZeroMQ is a battle-tested messaging library that’s been around since 2007. Some may perceive it as a predecessor to nanomsg, but what nano lacks is where ZeroMQ thrives—a flourishing developer community and a deluge of resources and supporting material. For many, it’s the de facto tool for building fast, asynchronous distributed messaging systems that scale.
Like nanomsg, ZeroMQ is not a message-oriented middleware and simply operates as a socket abstraction. In terms of usability, it’s very much the same as nanomsg, although its API is marginally more involved.
ActiveMQ and RabbitMQ
ActiveMQ and RabbitMQ are implementations of AMQP. They act as brokers which ensure messages are delivered. ActiveMQ and RabbitMQ support both persistent and non-persistent delivery. By default, messages are written to disk such that they survive a broker restart. They also support synchronous and asynchronous sending of messages with the former having substantial impact on latency. To guarantee delivery, these brokers use message acknowledgements which also incurs a massive latency penalty.
As far as availability and fault tolerance goes, these brokers support clustering through shared storage or shared nothing. Queues can be replicated across clustered nodes so there is no single point of failure or message loss.
AMQP is a non-trivial protocol which its creators claim to be over-engineered. These additional guarantees are made at the expense of major complexity and performance trade-offs. Fundamentally, clients are more difficult to implement and use.
Since they’re message brokers, ActiveMQ and RabbitMQ are additional moving parts that need to be managed in your distributed system, which brings deployment and maintenance costs. The same is true for the remaining message queues being discussed.
NATS and Ruby-NATS
NATS (gnatsd) is a pure Go implementation of the ruby-nats messaging system. NATS is distributed messaging rethought to be less enterprisey and more lightweight (this is in direct contrast to systems like ActiveMQ, RabbitMQ, and others). Apcera’s Derek Collison, the library’s author and former TIBCO architect, describes NATS as “more like a nervous system” than an enterprise message queue. It doesn’t do persistence or message transactions, but it’s fast and easy to use. Clustering is supported so it can be built on top of with high availability and failover in mind, and clients can be sharded. Unfortunately, TLS and SSL are not yet supported in NATS (they are in the ruby-nats) but on the roadmap.
As we observed earlier, NATS performs far better than the original Ruby implementation. Clients can be used interchangeably with NATS and ruby-nats.
Kafka
Originally developed by LinkedIn, Kafka implements publish-subscribe messaging through a distributed commit log. It’s designed to operate as a cluster that can be consumed by large amounts of clients. Horizontal scaling is done effortlessly using ZooKeeper so that additional consumers and brokers can be introduced seamlessly. It also transparently takes care of cluster rebalancing.
Kafka uses a persistent commit log to store messages on the broker. Unlike other durable queues which usually remove persisted messages on consumption, Kafka retains them for a configured period of time. This means that messages can be “replayed” in the event that a consumer fails.
ZooKeeper makes managing Kafka clusters relatively easy, but it does introduce yet another element that needs to be maintained. That said, Kafka exposes a great API and Shopify has an excellent Go client called Sarama that makes interfacing with Kafka very accessible.
Kestrel
Kestrel is a distributed message queue open sourced by Twitter. It’s intended to be fast and lightweight. Because of this, it has no concept of clustering or failover. While Kafka is built from the ground up to be clustered through ZooKeeper, the onus of message partitioning is put upon the clients of Kestrel. There is no cross-communication between nodes. It makes this trade-off in the name of simplicity. It features durable queues, item expiration, transactional reads, and fanout queues while operating over Thrift or memcache protocols.
Kestrel is designed to be small, but this means that more work must be done by the developer to build out a robust messaging system on top of it. Kafka seems to be a more “all-in-one” solution.
NSQ
NSQ is a messaging platform built by Bitly. I use the word platform because there’s a lot of tooling built around NSQ to make it useful for real-time distributed messaging. The daemon that receives, queues, and delivers messages to clients is called nsqd. The daemon can run standalone, but NSQ is designed to run in as a distributed, decentralized topology. To achieve this, it leverages another daemon called nsqlookupd. Nsqlookupd acts as a service-discovery mechanism for nsqd instances. NSQ also provides nsqadmin, which is a web UI that displays real-time cluster statistics and acts as a way to perform various administrative tasks like clearing queues and managing topics.
By default, messages in NSQ are not durable. It’s primarily designed to be an in-memory message queue, but queue sizes can be configured such that after a certain point, messages will be written to disk. Despite this, there is no built-in replication. NSQ uses acknowledgements to guarantee message delivery, but the order of delivery is not guaranteed. Messages can also be delivered more than once, so it’s the developer’s responsibility to introduce idempotence.
Similar to Kafka, additional nodes can be added to an NSQ cluster seamlessly. It also exposes both an HTTP and TCP API, which means you don’t actually need a client library to push messages into the system. Despite all the moving parts, it’s actually quite easy to deploy. Its API is also easy to use and there are a number of client libraries available.
Redis
Last up is Redis. While Redis is great for lightweight messaging and transient storage, I can’t advocate its use as the backbone of a distributed messaging system. Its pub/sub is fast but its capabilities are limited. It would require a lot of work to build a robust system. There are solutions better suited to the problem, such as those described above, and there are also some scaling concerns with it.
These matters aside, Redis is easy to use, it’s easy to deploy and manage, and it has a relatively small footprint. Depending on the use case, it can be a great choice for real-time messaging as I’ve explored before.
Conclusion
The purpose of this analysis is not to present some sort of “winner” but instead showcase a few different options for distributed messaging. There is no “one-size-fits-all” option because it depends entirely on your needs. Some use cases require fast, fire-and-forget messages, others require delivery guarantees. In fact, many systems will call for a combination of these. My hope is that this dissection will offer some insight into which solutions work best for a given problem so that you can make an intelligent decision.
Follow @tyler_treat