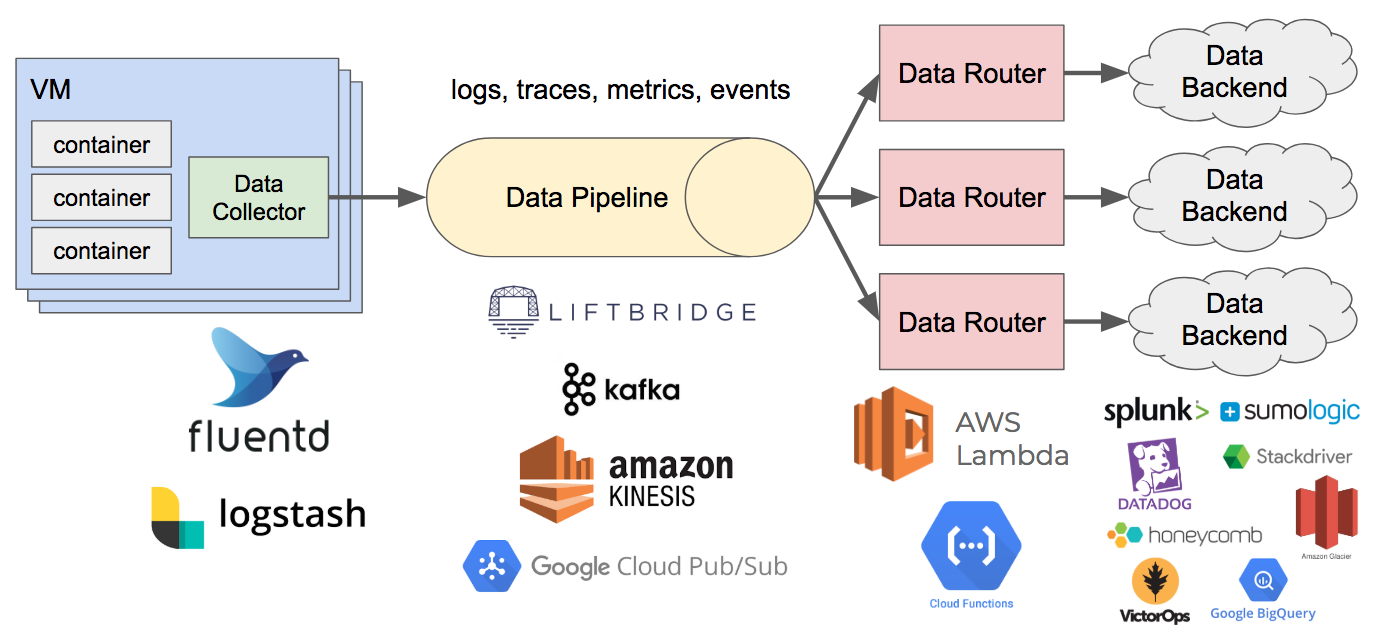
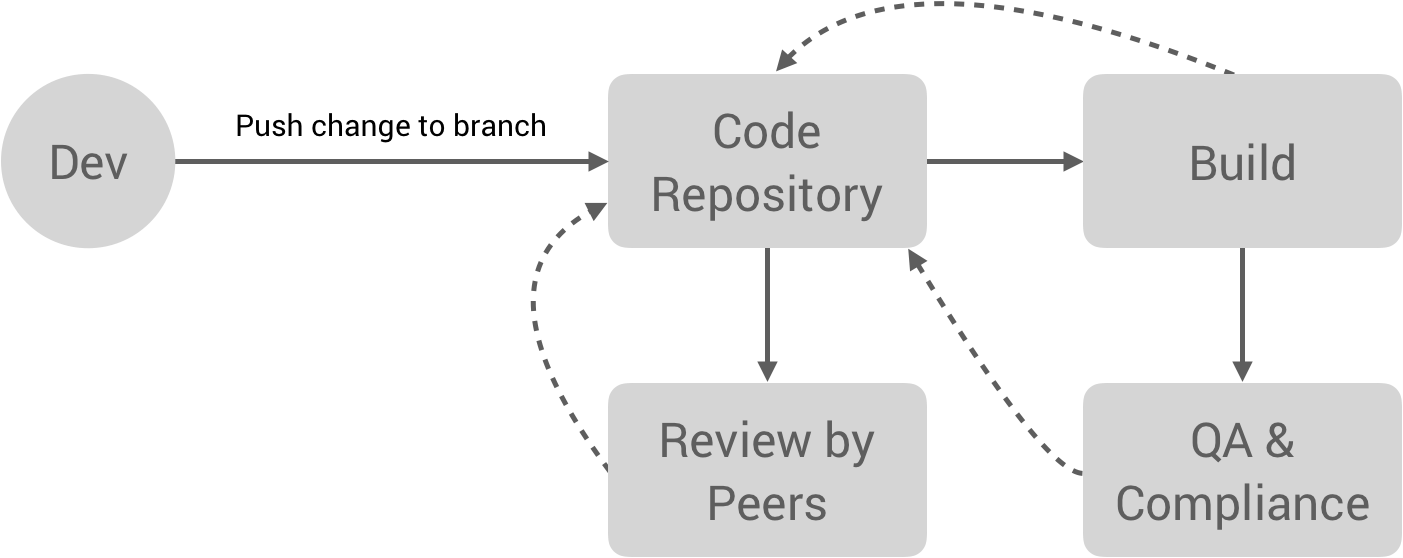
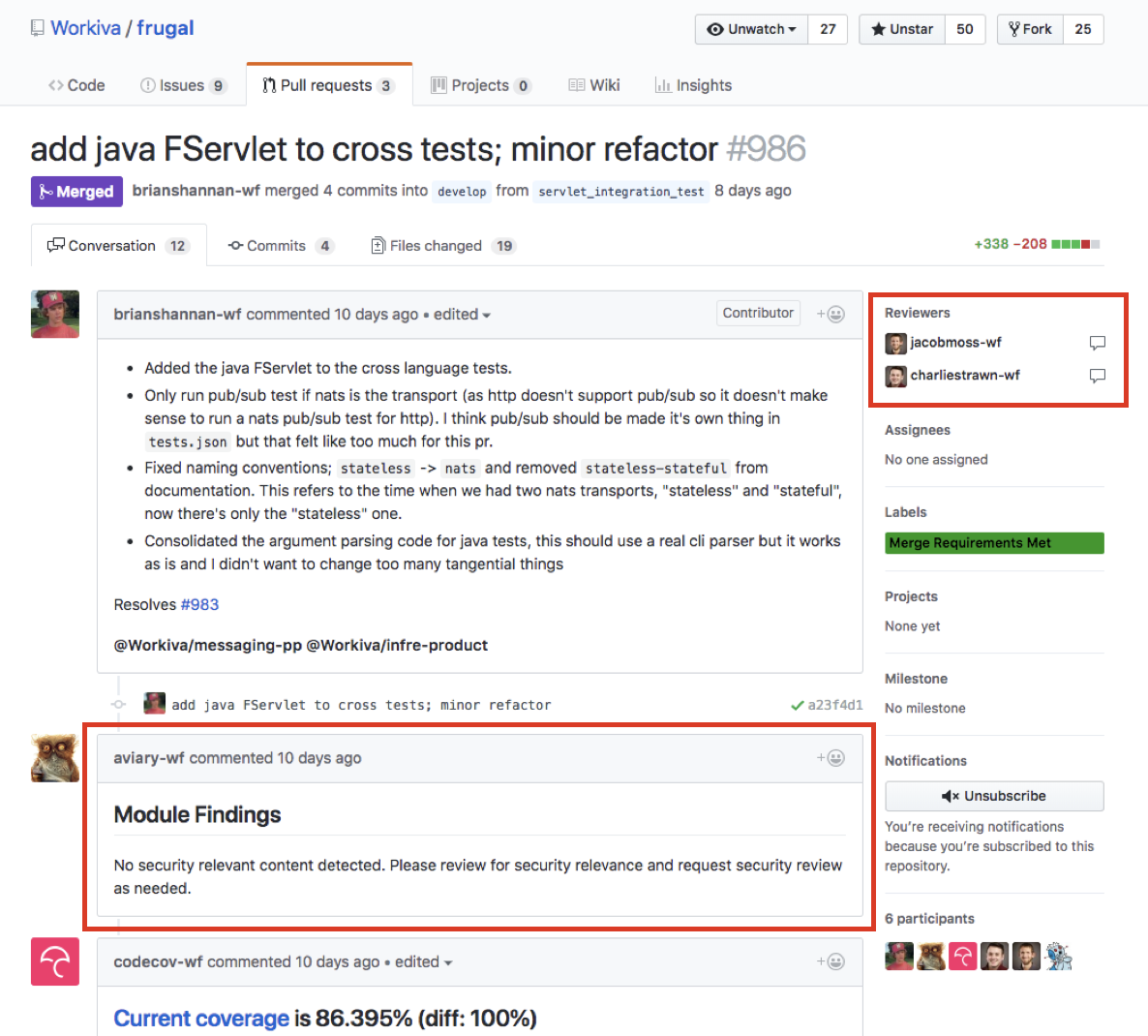
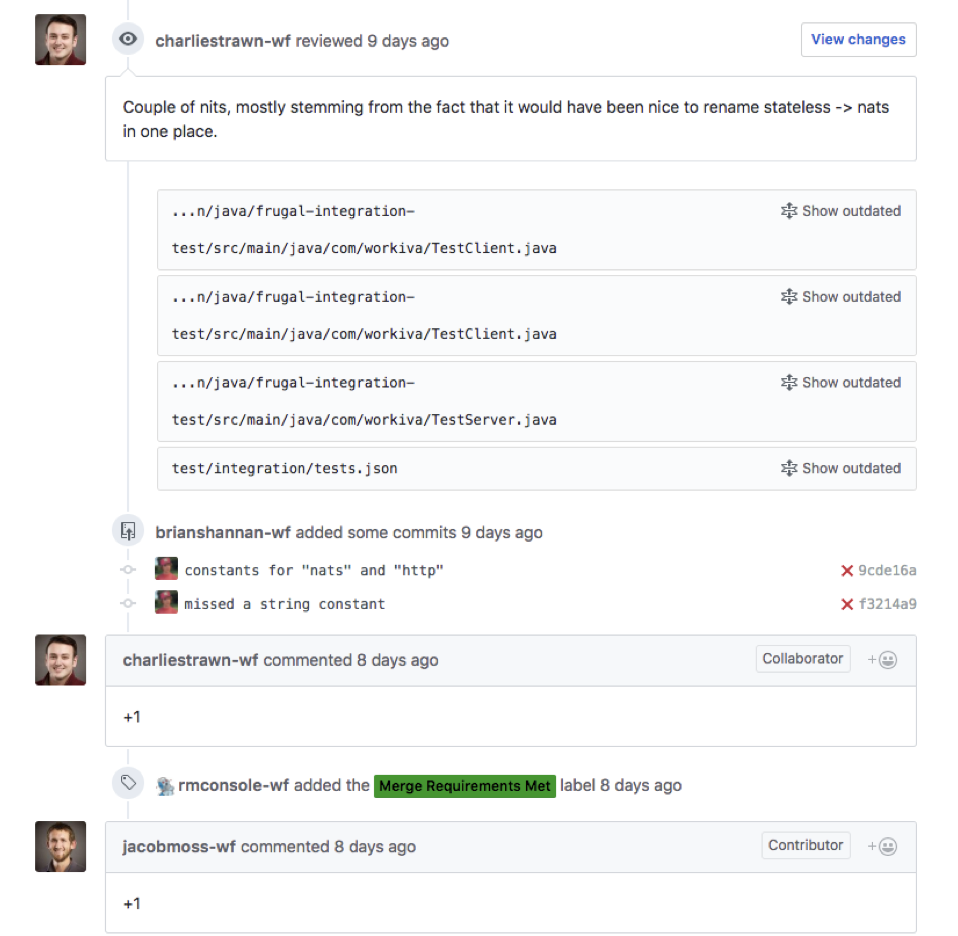
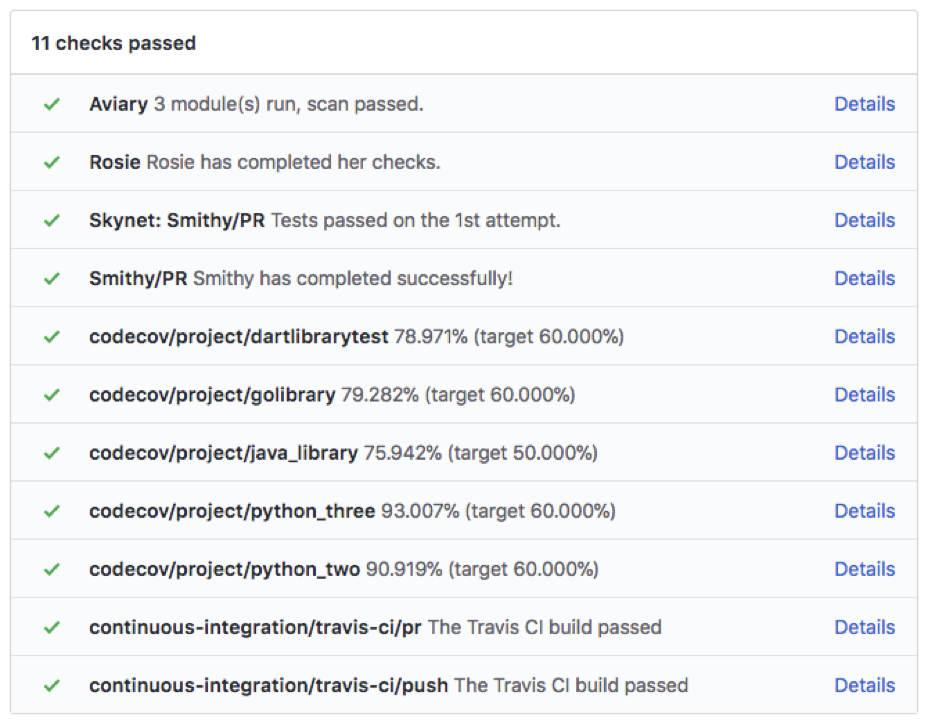
It comes up in a lot of conversations with clients. We want to be cloud-agnostic. We need to avoid vendor lock-in. We want to be able to shift workloads seamlessly between cloud providers. Let me say it again: multi-cloud is a trap. Outside of appeasing a few major retailers who might not be too keen on stuff running in Amazon data centers, I can think of few reasons why multi-cloud should be a priority for organizations of any scale.
A multi-cloud strategy looks great on paper, but it creates unneeded constraints and results in a wild-goose chase. For most, it ends up being a distraction, creating more problems than it solves and costing more money than it’s worth. I’m going to caveat that claim in just a bit because it’s a bold blanket statement, but bear with me. For now, just know that when I say “multi-cloud,” I’m referring to the idea of running the same services across vendors or designing applications in a way that allows them to move between providers effortlessly. I’m not speaking to the notion of leveraging the best parts of each cloud provider or using higher-level, value-added services across vendors.
Multi-cloud rears its head for a number of reasons, but they can largely be grouped into the following points: disaster recovery (DR), vendor lock-in, and pricing. I’m going to speak to each of these and then discuss where multi-cloud actually does come into play.
Disaster Recovery
Multi-cloud gets pushed as a means to implement DR. When discussing DR, it’s important to have a clear understanding of how cloud providers work. Public cloud providers like AWS, GCP, and Azure have a concept of regions and availability zones (n.b. Azure only recently launched availability zones in select regions, which they’ve learned the hard way is a good idea). A region is a collection of data centers within a specific geographic area. An availability zone (AZ) is one or more data centers within a region. Each AZ is isolated with dedicated network connections and power backups, and AZs in a region are connected by low-latency links. AZs might be located in the same building (with independent compute, power, cooling, etc.) or completely separated, potentially by hundreds of miles.
Region-wide outages are highly unusual. When they happen, it’s a high-profile event since it usually means half the Internet is broken. Since AZs themselves are geographically isolated to an extent, a natural disaster taking down an entire region would basically be the equivalent of a meteorite wiping out the state of Virginia. The more common cause of region failures are misconfigurations and other operator mistakes. While rare, they do happen. However, regions are highly isolated, and providers perform maintenance on them in staggered windows to avoid multi-region failures.
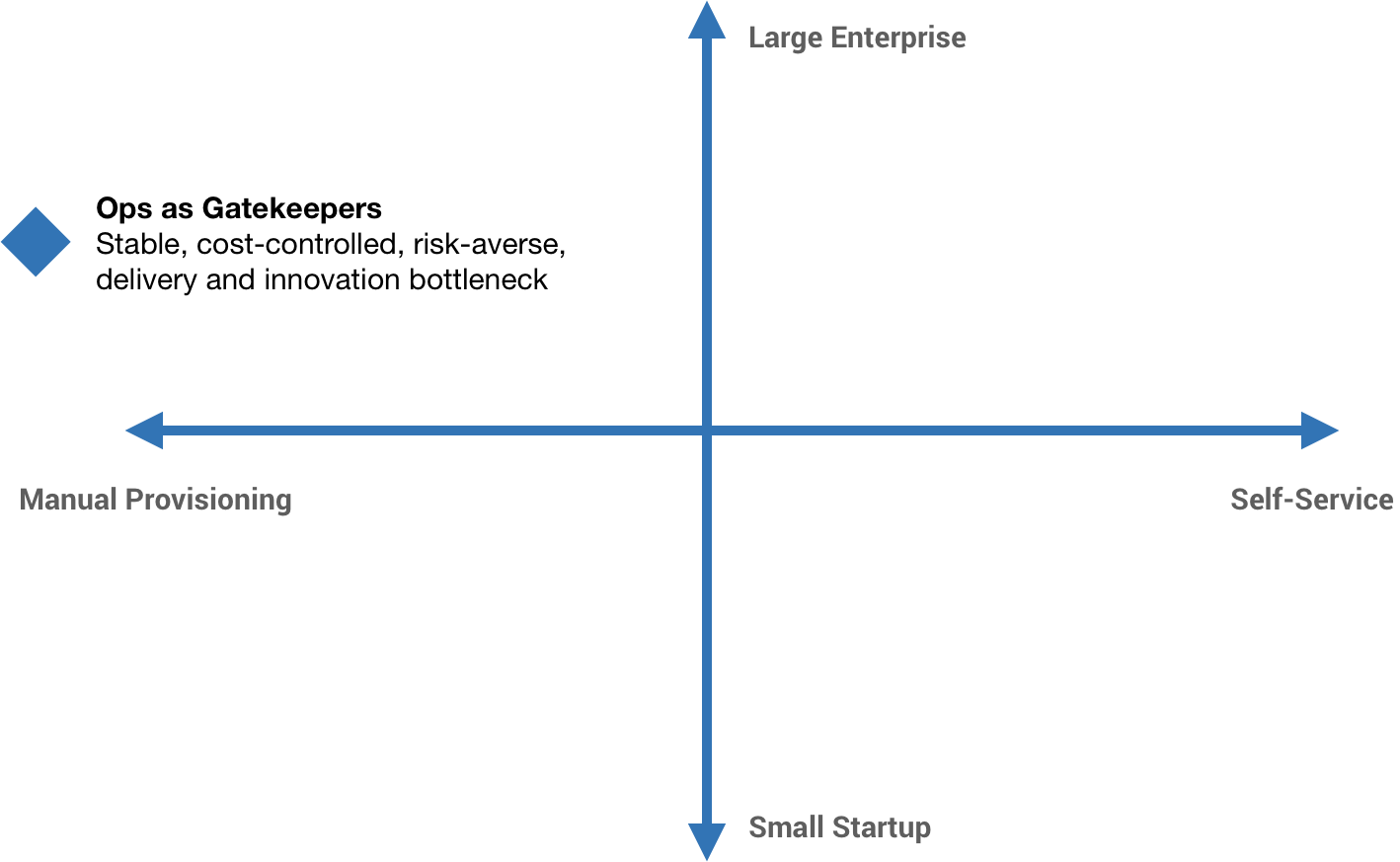
That’s not to say a multi-region failure is out of the realm of possibility (any more than a meteorite wiping out half the continental United States or some bizarre cascading failure). Some backbone infrastructure services might span regions, which can lead to larger-scale incidents. But while having a presence in multiple cloud providers is obviously safer than a multi-region strategy within a single provider, there are significant costs to this. DR is an incredibly nuanced topic that I think goes underappreciated, and I think cloud portability does little to minimize those costs in practice. You don’t need to be multi-cloud to have a robust DR strategy—unless, perhaps, you’re operating at Google or Amazon scale. After all, Amazon.com is one of the world’s largest retailers, so if your DR strategy can match theirs, you’re probably in pretty good shape.
Vendor Lock-In
Vendor lock-in and the related fear, uncertainty, and doubt therein is another frequently cited reason for a multi-cloud strategy. Beau hits on this in Stop Wasting Your Beer Money:
The cloud. DevOps. Serverless. These are all movements and markets created to commoditize the common needs. They may not be the perfect solution. And yes, you may end up “locked in.” But I believe that’s a risk worth taking. It’s not as bad as it sounds. Tim O’Reilly has a quote that sums this up:
“Lock-in” comes because others depend on the benefit from your services, not because you’re completely in control.
We are locked-in because we benefit from this service. First off, this means that we’re leveraging the full value from this service. And, as a group of consumers, we have more leverage than we realize. Those providers are going to do what is necessary to continue to provide value that we benefit from. That is what drives their revenue. As O’Reilly points out, the provider actually has less control than you think. They’re going to build the system they believe benefits the largest portion of their market. They will focus on what we, a player in the market, value.
Competition is the other key piece of leverage. As strong as a provider like AWS is, there are plenty of competing cloud providers. And while competitors attempt to provide differentiated solutions to what they view as gaps in the market they also need to meet the basic needs. This is why we see so many common services across these providers. This is all for our benefit. We should take advantage of this leverage being provided to us. And yes, there will still be costs to move from one provider to another but I believe those costs are actually significantly less than the costs of going from on-premise to the cloud in the first place. Once you’re actually on the cloud you gain agility.
The mental gymnastics I see companies go through to avoid vendor lock-in and “reasons” for multi-cloud always astound me. It’s baffling the amount of money companies are willing to spend on things that do not differentiate them in any way whatsoever and, in fact, forces them to divert resources from business-differentiating things.
Avoiding "vendor lock in" with AWS by building your own functions as a service on a container platform with a cloud provider that has *at best* 1/4th the revenue/customers/scale.
Bonus: you also get to avoid 100% utilization! pic.twitter.com/6hsbw7AftB
— xnoɹǝʃ uɐıɹq 💎 (@brianleroux) August 21, 2018
I think there are a couple reasons for this. First, as Beau points out, we have a tendency to overvalue our own abilities and undervalue our costs. This causes us to miscalculate the build versus buy decision. This is also closely related to the IKEA effect, in which consumers place a disproportionately high value on products they partially created. Second, as the power and influence in organizations has shifted from IT to the business—and especially with the adoption of product mindset—it strikes me as another attempt by IT operations to retain control and relevance.
Being cloud-agnostic should not be an important enough goal that it drives key decisions. If that’s your starting point, you’re severely limiting your ability to fully reap the benefits of cloud. You’re just renting compute. Platforms like Pivotal Cloud Foundry and Red Hat OpenShift tout the ability to run on every major private and public cloud, but doing so—by definition—necessitates an abstraction layer that abstracts away all the differentiating features of each cloud platform. When you abstract away the differentiating features to avoid lock-in, you also abstract away the value. You end up with vendor “lock-out,” which basically means you aren’t leveraging the full value of services. Either the abstraction reduces things to a common interface or it doesn’t. If it does, it’s unclear how it can leverage differentiated provider features and remain cloud-agnostic. If it doesn’t, it’s unclear what the value of it is or how it can be truly multi-cloud.
Not to pick on PCF or Red Hat too much, but as the major cloud providers continue to unbundle their own platforms and rebundle them in a more democratized way, the value proposition of these multi-cloud platforms begins to diminish. In the pre-Kubernetes and containers era—aka the heyday of Platform as a Service (PaaS)—there was a compelling story. Now, with the prevalence of containers, Kubernetes, and especially things like Google’s GKE and GKE On-Prem (and equivalents in other providers), that story is getting harder to tell. Interestingly, the recently announced Knative was built in close partnership with, among others, both Pivotal and Red Hat, which seems to be a play to capture some of the value from enterprise adoption of serverless computing using the momentum of Kubernetes.
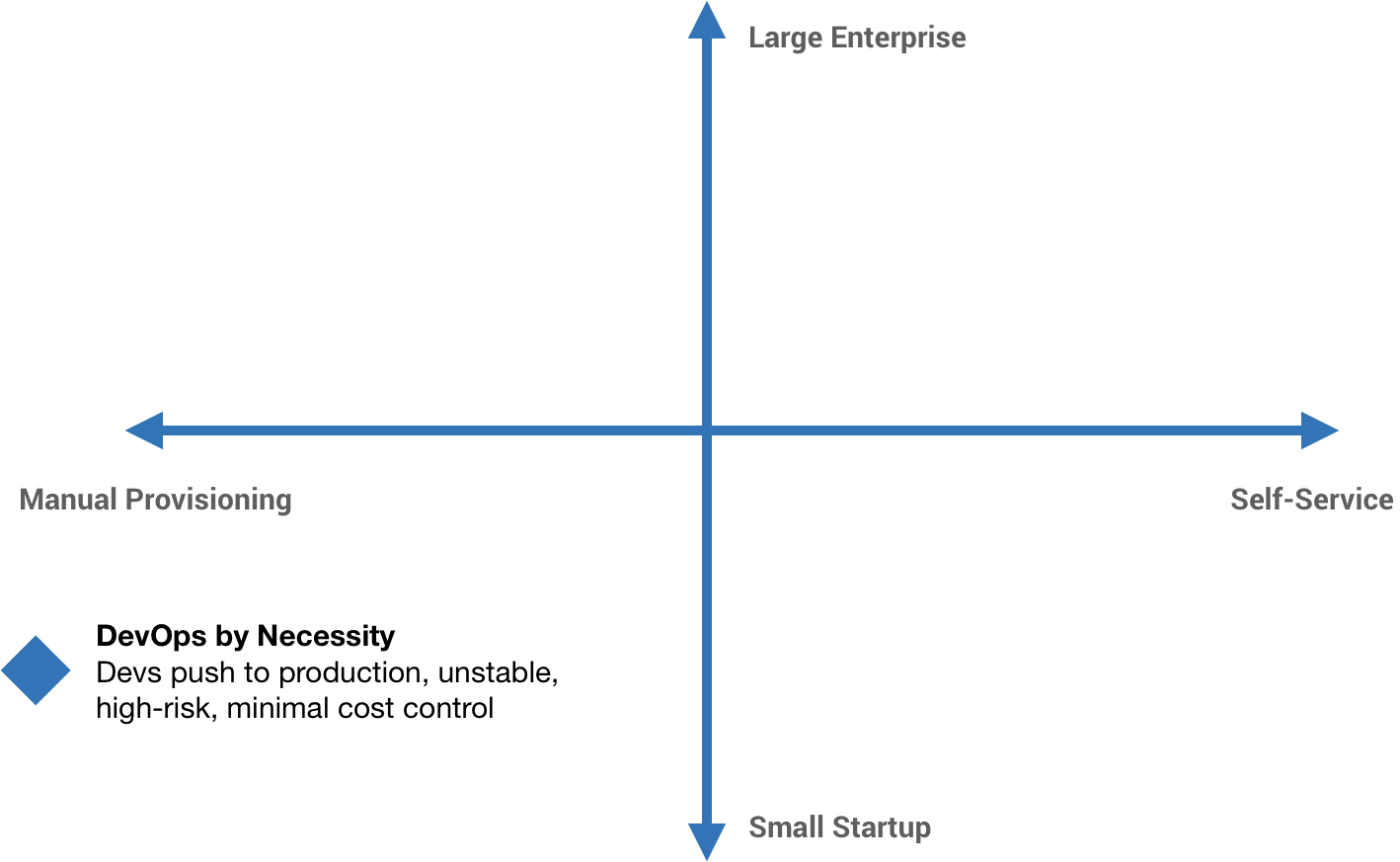
But someone needs to run these multi-cloud platforms as a service, and therein lies the rub. That responsibility is usually dumped on an operations or shared-services team who now needs to run it in multiple clouds—and probably subscribe to a services contract with the vendor.
It is very difficult to keep up with the quirks, gotchas, roadmaps, schedules, contacts, and bugs of a single cloud vendor. Provisioning across multiple vendors is even trickier.
— Bennett (@yo_bennett) September 12, 2018
A multi-cloud deployment requires expertise for multiple cloud platforms. A PaaS might abstract that away from developers, but it’s pushed down onto operations staff. And we’re not even getting in to the security and compliance implications of certifying multiple platforms. For some companies who are just now looking to move to the cloud, this will seriously derail things. Once we get past the airy-fairy marketing speak, we really get into the hairy details of what it means to be multi-cloud.
There’s just less room today for running a PaaS that is not managed for you. It’s simply not strategic to any business. I also like to point out that revenues for companies like Pivotal and Red Hat are largely driven by services. These platforms act as a way to drive professional services revenue.
Generally speaking, the risk posed to businesses by vendor lock-in of non-strategic systems is low. For example, a database stores data. Whether it’s Amazon DynamoDB, Google Cloud Datastore, or Azure Cosmos DB—there might be technical differences like NoSQL, relational, ANSI-compliant SQL, proprietary, and so on—fundamentally, they just put data in and get data out. There may be engineering effort involved in moving between them, but it’s not insurmountable and that cost is often far outweighed by the benefits we get using them. Where vendor lock-in can become a problem is when relying on core strategic systems. These might be systems which perform actual business logic or are otherwise key enablers of a company’s business. As Joel Spolsky says, “If it’s a core business function—do it yourself, no matter what. Pick your core business competencies and goals, and do those in house.”
Pricing
Price competitiveness might be the weakest argument of all for multi-cloud. The reality is, as they commoditize more and more, all providers are in a race to the bottom when it comes to cost. Between providers, you will end up spending more in some areas and less in others. Multi-cloud price arbitrage is not a thing, it’s just something people pretend is a thing. For one, it’s wildly impractical. For another, it fails to account for volume discounts. As I mentioned in my comparison of AWS and GCP, it really comes down more to where you want to invest your resources when picking a cloud provider due to their differing philosophies.
And to Beau’s point earlier, the lock-in angle on pricing, i.e. a vendor locking you in and then driving up prices, just doesn’t make sense. First, that’s not how economies of scale work. And once you’re in the cloud, the cost of moving from one provider to another is dramatically less than when you were on-premise, so this simply would not be in providers’ best interest. They will do what’s necessary to capture the largest portion of the market and competitive forces will drive Infrastructure as a Service (IaaS) costs down. Because of the competitive environment and desire to capture market share, pricing is likely to converge. For cloud providers to increase margins, they will need to move further up the stack toward Software as a Service (SaaS) and value-added services.
Additionally, most public cloud providers offer volume discounts. For instance, AWS offers Reserved Instances with significant discounts up to 75% for EC2. Other AWS services also have volume discounts, and Amazon uses consolidated billing to combine usage from all the accounts in an organization to give you a lower overall price when possible. GCP offers sustained use discounts, which are automatic discounts that get applied when running GCE instances for a significant portion of the billing month. They also implement what they call inferred instances, which is bin-packing partial instance usage into a single instance to prevent you from losing your discount if you replace instances. Finally, GCP likewise has an equivalent to Amazon’s Reserved Instances called committed use discounts. If resources are spread across multiple cloud providers, it becomes more difficult to qualify for many of these discounts.
Where Multi-Cloud Makes Sense
I said I would caveat my claim and here it is. Yes, multi-cloud can be—and usually is—a distraction for most organizations. If you are a company that is just now starting to look at cloud, it will serve no purpose but to divert you from what’s really important. It will slow things down and plant seeds of FUD.
Some companies try to do build-outs on multiple providers at the same time in an attempt to hedge the risk of going all in on one. I think this is counterproductive and actually increases the risk of an unsuccessful outcome. For smaller shops, pick a provider and focus efforts on productionizing it. Leverage managed services where you can, and don’t use multi-cloud as a reason not to. For larger companies, it’s not unreasonable to have build-outs on multiple providers, but it should be done through controlled experimentation. And that’s one of the benefits of cloud, we can make limited investments and experiment without big up-front expenditures—watch out for that with the multi-cloud PaaS offerings and service contracts.
But no, that doesn’t mean multi-cloud doesn’t have a place. Things are never that cut and dry. For large enterprises with multiple business units, multi-cloud is an inevitability. This can be a result of product teams at varying levels of maturity, corporate IT infrastructure, and certainly through mergers and acquisitions. The main value of multi-cloud, and I think one of the few arguments for it, is leveraging the strengths of each cloud where they make sense. This gets back to providers moving up the stack. As they attempt to differentiate with value-added services, multi-cloud starts to become a lot more meaningful. Secondarily, there might be a case for multi-cloud due to data-sovereignty reasons, but I think this is becoming less and less of a concern with the prevalence of regions and availability zones. However, some services, such as Google’s Cloud Spanner, might forgo AZ-granularity due to being “globally available” services, so this is something to be aware of when dealing with regulations like GDPR. Finally, for enterprises with colocation facilities, hybrid cloud will always be a reality, though this gets complicated when extending those out to multiple cloud providers.
If you’re just beginning to dip your toe into cloud, a multi-cloud strategy should not be at the forefront of your mind. It definitely should not be your guiding objective and something that drives core decisions or strategic items for the business. It has a time and place, but outside of that, it’s just a fool’s errand—a distraction from what’s truly important.
Follow @tyler_treat