Key rotation, auditing, and secure CI/CD
Companies often require employees to regularly change their passwords for security purposes. PCI compliance, for example, requires that passwords be changed every 90 days. However, NIST, whose guidelines commonly become the foundation for security best practices across countless organizations, recently revised its recommendations around password security. Its Digital Identity Guidelines (NIST 800-63-3) now recommends removing periodic password-change requirements due to a growing body of research suggesting that frequent password changes actually makes security worse. This is because these requirements encourage the use of passwords which are more susceptible to cracking (e.g. incrementing a number or altering a single character) or result in people writing their passwords down.
Unfortunately, many companies have now adapted these requirements to other parts of their IT infrastructure. This is largely due to legacy holdover practices which have crept into modern systems (or simply lingered in older ones), i.e. it’s tech debt. Specifically, I’m talking about practices like using username/password credentials that applications or systems use to access resources instead of individual end users. These special credentials may even provide a system free rein within a network much like a user might have, especially if the network isn’t segmented (often these companies have adopted a perimeter-security model, relying on a strong outer wall to protect their network). As a result, because they are passwords just like a normal user would have, they are subject to the usual 90-day rotation policy or whatever the case may be.
Today, I think we can say with certainty that—along with the perimeter-security model—relying on usernames and passwords for system credentials is a security anti-pattern (and really, user credentials should be relying on multi-factor authentication). With protocols like OAuth2 and OpenID Connect, we can replace these system credentials with cryptographically strong keys. But because these keys, in a way, act like username/passwords, there is a tendency to apply the same 90-day rotation policy to them as well. This is a misguided practice for several reasons and is actually quite risky.
First, changing a user’s password is far less risky than rotating an access key for a live, production system. If we’re changing keys for production systems frequently, there is a potential for prolonged outages. The more you’re touching these keys, the more exposure and opportunity for mistakes there is. For a user, the worst case is they get temporarily locked out. For a system, the worst case is a critical user-facing application goes down. Second, cryptographically strong keys are not “guessable” like a password frequently is. Since they are generated by an algorithm and not intended to be input by a human, they are long and complex. And unlike passwords, keys are not generally susceptible to social engineering. Lastly, if we are requiring keys to be rotated every 90 days, this means an attacker can still have up to 89 days to do whatever they want in the event of a key being compromised. From a security perspective, this frankly isn’t good enough to me. It’s security by happenstance. The Twitter thread below describes a sequence of events that occurred after an AWS key was accidentally leaked to a public code repository which illustrates this point.
To recap that thread, here’s a timeline of what happened:
- AWS credentials are pushed to a public repository on GitHub.
- 55 seconds later, an email is received from AWS telling the user that their account is compromised and a support ticket is automatically opened.
- A minute later (2 minutes after the push), an attacker attempts to use the credentials to list IAM access keys in order to perform a privilege escalation. Since the IAM role attached to the credentials is insufficient, the attempt failed and an event is logged in CloudTrail.
- The user disables the key 5 minutes and 58 seconds after the push.
- 24 minutes and 58 seconds after the push, GuardDuty fires a notification indicating anomalous behavior: “APIs commonly used to discover the users, groups, policies and permissions in an account, was invoked by IAM principal some_user under unusual circumstances. Such activity is not typically seen from this principal.”
Given this timeline, rotating access keys every 90 days would do absolutely no good. If anything, it would provide a false sense of security. An attack was made a mere 2 minutes after the key was compromised. It makes no difference if it’s rotated every 90 days or every 9 minutes.
If 90-day key rotation isn’t the answer, what is? The timeline above already hits on it. System credentials, i.e. service accounts, should have very limited permissions following the principle of least privilege. For instance, a CI server which builds artifacts should have a service account which only allows it to push artifacts to a storage bucket and nothing else. This idea should be applied to every part of your system.
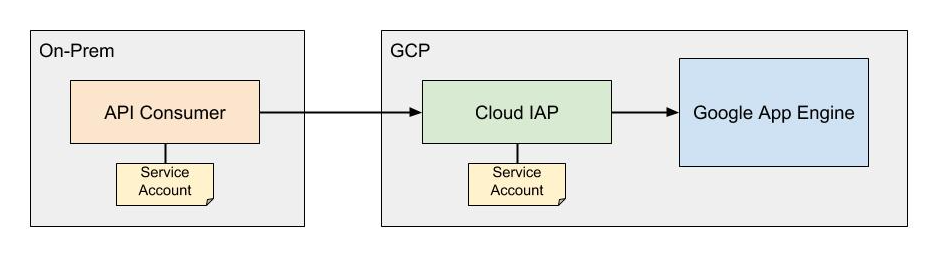
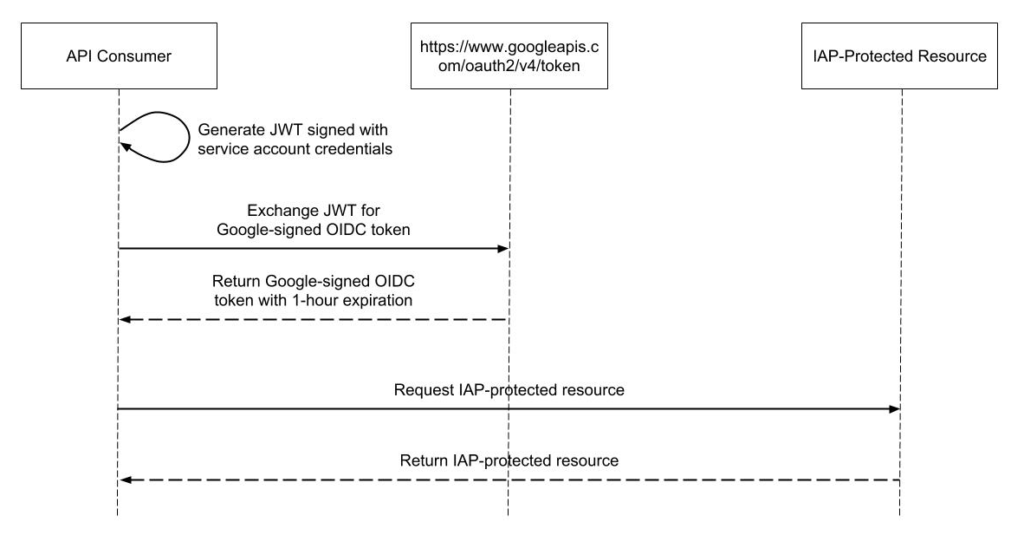
For things running inside the cloud, such as AWS or GCP, we can usually avoid the need for access keys altogether. With GCP, we rely on service accounts with GCP-managed keys. The keys for these service accounts are not exposed to users at all and are, in fact, rotated approximately every two weeks (Google is able to do this because they own all of the infrastructure involved and have mature automation). With AWS, we rely on Identity and Access Management (IAM) users and roles. The role can then be assumed by the environment without having to deal with a token or key. This situation is ideal because we can avoid key exposure by never having explicit keys in the first place.
For things running outside the cloud, it’s a bit more involved. In these cases, we must deal with credentials somehow. Ideally, we can limit the lifetime of these credentials, such as with AWS’ Security Token Service (STS) or GCP’s short-lived service account credentials. However, in some situations, we may need longer-lived credentials. In either case, the critical piece is using limited-privilege credentials such that if a key is compromised, the scope of the damage is narrow.
The other key component of this is auditing. Both AWS and GCP offer extensive audit logs for governance, compliance, operational auditing, and risk auditing of your cloud resources. With this, we can audit service account usage, detect anomalous behavior, and immediately take action—such as revoking the credential—rather than waiting up to 90 days to rotate it. Amazon also has GuardDuty which provides intelligent threat detection and continuous monitoring which can identify unauthorized activity as seen in the scenario above. Additionally, access credentials and other secrets should never be stored in source code, but tools like git-secrets, GitGuardian, and truffleHog can help detect when it does happen.
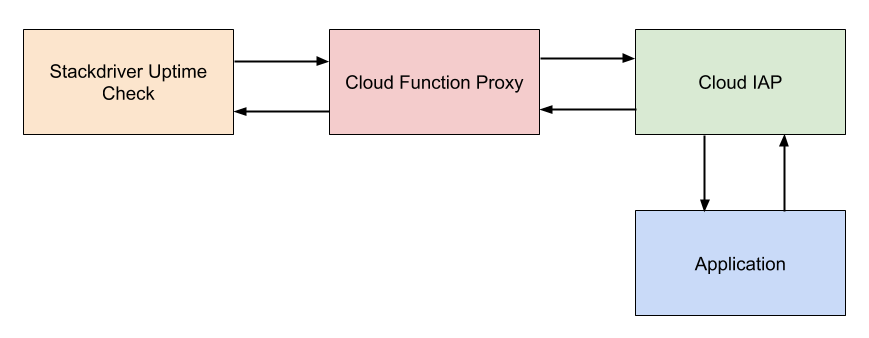
Let’s look at a hypothetical CI/CD pipeline as an example which ties these ideas together. Below is the first pass of our proposed pipeline. In this case, we’re targeting GCP, but the same ideas apply to other environments.
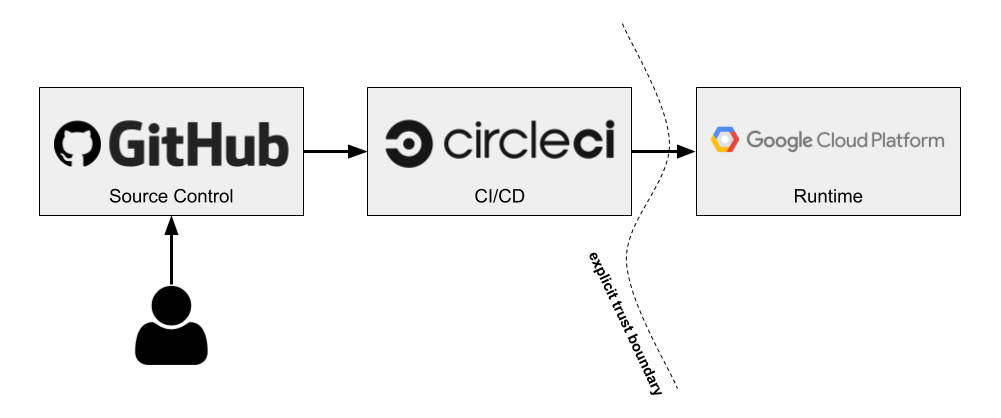
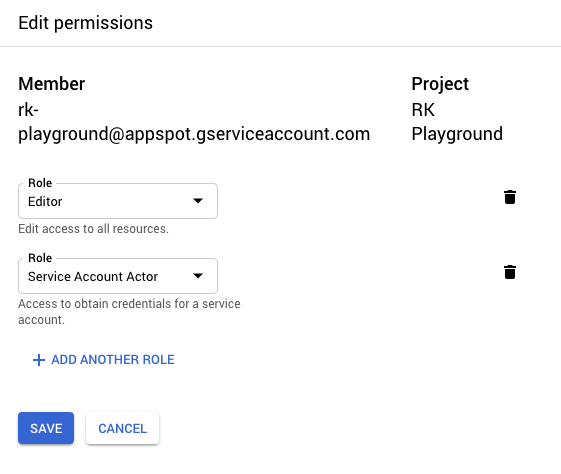
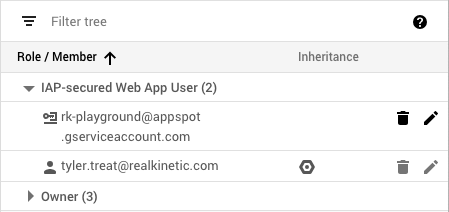
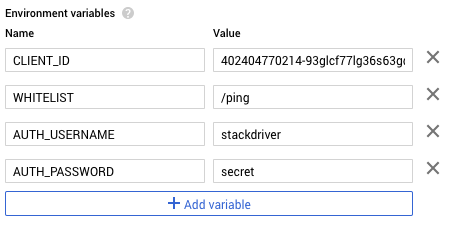
CircleCI is a SaaS-based CI/CD solution. Because it’s deploying to GCP, it will need a service account with the appropriate IAM roles. CircleCI has support for storing secret environment variables, which is how we would store the service account’s credentials. However, there are some downsides to this approach.
First, the service account that Circle needs in order to make deploys could require a fairly wide set of privileges, like accessing a container registry and deploying to a runtime. Because it lives outside of GCP, this service account has a user-managed key. While we could use a KMS to encrypt it or a vault that provides short-lived credentials, we ultimately will need some kind of credential that allows Circle to access these services, so at best we end up with a weird Russian-doll situation. If we’re rotating keys, we might wind up having to do so recursively, and the value of all this indirection starts to come into question. Second, these credentials—or any other application secrets—could easily be dumped out as part of the build script. This isn’t good if we wanted Circle to deploy to a locked-down production environment. Developers could potentially dump out the production service account credentials and now they would be able to make deploys to that environment, circumventing our pipeline.
This is why splitting out Continuous Integration (CI) from Continuous Delivery (CD) is important. If, instead, Circle was only responsible for CI and we introduced a separate component for CD, such as Spinnaker, we can solve this problem. Using this approach, now Circle only needs the ability to push an artifact to a Google Cloud Storage bucket or Container Registry. Outside of the service account credentials needed to do this, it doesn’t need to deal with secrets at all. This means there’s no way to dump out secrets in the build because they will be injected later by Spinnaker. The value of the service account credentials is also much more limited. If compromised, it only allows someone to push artifacts to a repository. Spinnaker, which would run in GCP, would then pull secrets from a vault (e.g. Hashicorp’s Vault) and deploy the artifact relying on credentials assumed from the environment. Thus, Spinnaker only needs permissions to pull artifacts and secrets and deploy to the runtime. This pipeline now looks something like the following:
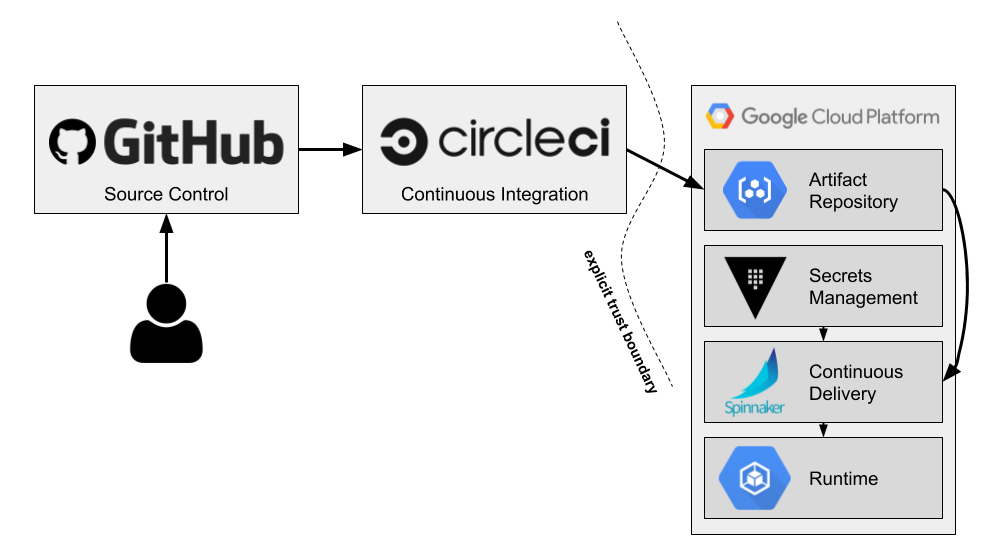
With this pipeline, we now have traceability from code commit and pull request (PR) to deploy. We can then scan audit logs to detect anomalous behavior—a push to an artifact repository that is not associated with the CircleCI service account or a deployment that does not originate from Spinnaker, for example. Likewise, we can ensure these processes correlate back to an actual GitHub PR or CircleCI build. If they don’t, we know something fishy is going on.
To summarize, requiring frequent rotations of access keys is an outdated practice. It’s a remnant of password policies which themselves have become increasingly reneged by security experts. While similar in some ways, keys are fundamentally different than a username and password, particularly in the case of a service account with fine-grained permissions. Without mature practices and automation, rotating these keys frequently is an inherently risky operation that opens up the opportunity for downtime.
Instead, it’s better to rely on tightly scoped (and, if possible, short-lived) service accounts and usage auditing to detect abnormal behavior. This allows us to take action immediately rather than waiting for some arbitrary period to rotate keys where an attacker may have an unspecified amount of time to do as they please. With end-to-end traceability and evidence collection, we can more easily identify suspicious actions and perform forensic analysis.
Note that this does not mean we should never rotate access keys. Rather, we can turn to NIST for its guidance on key management. NIST 800-57 recommends cryptoperiods of 1-2 years for asymmetric authentication keys in order to maximize operational efficiency. Beyond these particular cryptoperiods, the value of rotating keys regularly is in having the confidence you can, in fact, rotate them without incident. The time interval itself is mostly immaterial, but developing this confidence is important in the event of a key actually being compromised. In this case, you want to know you can act swiftly and revoke access without causing outages.
The funny thing about compliance is that, unless you’re going after actual regulatory standards such as FedRAMP or PCI compliance, controls are generally created by the company itself. Compliance auditors mostly ensure the company is following its own controls. So if you hear, “it’s a compliance requirement” or “that’s the way it’s always been done,” try to dig deeper to understand what risk the control is actually trying to mitigate. This allows you to have a dialog with InfoSec or compliance folks and possibly come to the table with better alternatives.
Follow @tyler_treat